AWS クイック スタート テンプレートを使用して Data Center 製品をデプロイする
デプロイ方法としての AWS クイック スタート テンプレートはアトラシアンではサポートされなくなりました。テンプレートは今後も利用できますが、保守や更新は行われません。
より効率的で堅牢なインフラストラクチャと運用のセットアップのために、Helm チャートを使用して Data Center 製品を Kubernetes クラスターにデプロイすることをお勧めします。Kubernetes へのデプロイに関する詳細はこちらをご確認ください。
AWS は、現在、AWS クイック スタート テンプレートで使用される起動設定を起動テンプレートに切り替えることを推奨していますが、AWS クイック スタート テンプレートのサポートは終了しているため、アトラシアンではこの切り替えを行う予定はありません。そのため、このテンプレートを使用して起動設定を作成することはできません。
Data Center インスタンスをクラスタ環境でデプロイする場合は、Amazon Web Services (AWS) の利用をご検討ください。AWS では、追加のノードをサイズ変更してすばやく起動することでデプロイを柔軟にスケーリングできます。また、Data Center 製品ですぐに使える多数の管理サービスが用意されています。これらのサービスによって、デプロイのクラスタ インフラストラクチャの設定、管理、保守がより容易になります。Data Center の詳細をご確認ください。
非クラスタ環境とクラスタ環境
クラスタ化を必要とする特定の機能 (高可用性やゼロダウンタイムのアップグレードなど) を必要としない場合、ほとんどの「小」または「中」サイズのデプロイでは単一ノードが適しています。
既存の Server インストールがある場合は、Data Center にアップグレードする際にそのインフラストラクチャを引き続き使用できます。Data Center 専用の多くの機能 (SAML シングル サインオン、レート制限によるシステムの保護、CDN サポートなど) では、クラスタ インフラストラクチャは不要です。Server インストールのライセンスをアップグレードするだけで、Data Center のこれらの機能の使用を開始できます。
クラスタ化が必要かどうかの詳細については「Data Center のアーキテクチャとインフラストラクチャのオプション」をご参照ください。
AWS クイック スタートを使用したクラスタでの Data Center インスタンスのデプロイ
AWS に Data Center クラスタ全体をデプロイする最も単純な方法は、クイック スタートを使用することです。Quick Start は、AWS のセキュリティと可用性のためのベスト プラクティスを使用して、AWS 上に特定のワークロードをデプロイするのに必要な AWS コンピュータ、ネットワーク、ストレージ、およびその他のサービスを、起動、設定、および実行します。
クイック スタートでは 2 つのデプロイ オプションが提供されており、それぞれ独自のテンプレートを使用します。1 つ目のオプションでは、Atlassian Standard Infrastructure (ASI) をデプロイし、この ASI に Data Center 製品をプロビジョニングします。2 つ目のオプションでは、既存の ASI への Data Center 製品のプロビジョニングのみを行います。
ASI は、アトラシアンのすべての Data Center アプリで必要なコンポーネントを含む仮想プライベート クラウド (VPC) です。詳細については、「AWS の Atlassian Standard Infrastructure (ASI)」を参照してください。
デプロイメントは、以下のコンポーネントで構成されています。
Bitbucket ではデプロイ インフラストラクチャが異なりますのでご注意ください。詳細は次をご確認ください。
インスタンス / ノード: Data Center インスタンスを実行しているクラスタ ノードとしての 1 つ以上の Amazon Elastic Cloud (EC2) インスタンス。
ロード バランサ: ロード バランサおよび SSL ターミネート リバース プロキシの両方として機能する Application Load Balancer (ALB)。
Amazon EFS: 複数のノードにアクセス可能な共通の場所にアーティファクトを保存する共有ファイル システム。クイック スタートのアーキテクチャでは、高可用性構成の Amazon Elastic File System (Amazon EFS) サービスを使用して、共有ファイル システムを実装します。
データベース: 選択した共有データベース インスタンス (Amazon RDS または Amazon Aurora)。
Amazon CloudWatch: Amazon のネイティブ CloudWatch サービスによる基本的なモニタリングおよび中央ログ。
Confluence では、EC2 インスタンスにインストールされている Java Runtime Engine (JRE) (/usr/lib/jvm/jre/) ではなく、Confluence にバンドルされている JRE (/opt/atlassian/confluence/jre/) が使用されます。
AWS での Jira 製品、AWS での Confluence、AWS での Bitbucket、AWS での Crowd の詳細をご確認ください。
高度なカスタマイズ
迅速な実装のため、クイック スタートでは手動インストールと同じレベルのカスタマイズは提供していません。ただし、アトラシアンで使用している Ansible プレイブックの変数を通じてデプロイメントをさらにカスタマイズできます。
アトラシアンが提供しているすべての AWS クイック スタートでは、Ansible プレイブックを使用してデプロイの特定のコンポーネントを設定します。これらのプレイブックはリポジトリ https://bitbucket.org/atlassian/dc-deployments-automation で公開されています。
Ansible 変数を使用してこれらの構成をオーバーライドできます。詳細は、リポジトリの README ファイルを参照してください。
Jira でのカスタマイズに関する注意事項
Jira では jira-config.properties ファイルを通じて高度な設定を適用できます。同じファイルを使用して既存のクイック スタート デプロイに同じ設定を適用することもできます。jira-config.properties ファイルのカスタマイズ方法をご確認ください。
自身の S3 バケットからのクイック スタートの起動 (推奨)
クイック スタートをもっとも素早く起動する方法は、AWS S3 バケットから直接起動することです。だだしこれを行った場合、アトラシアンでクイック スタート テンプレートに加えているすべての更新がデプロイメントに直接伝播されます。これらの更新には、テンプレートからのパラメーターの追加や削除が含まれる場合があります。これにより、デプロイメントに予期しない (および大幅な) 変更が発生する可能性があります。
本番環境の場合、クイック スタート テンプレートを自身の S3 バケットにコピーすることをおすすめします。次に、それらをそこから直接起動します。これにより、クイック スタートの更新をデプロイメントに伝播するタイミングを制御できるようになります。
クイック スタートを起動するには、次の手順に従います。
高可用性のための Amazon Aurora データベース
クイック スタートによって、(RDS の代わりに) Amazon Aurora クラスタ データベースを使用して Data Center インスタンスをデプロイすることもできます。
クラスタは PostgreSQL 互換で、2 つのデータベース リーダーをレプリケートする、プライマリ データベース ライターを備えています。冗長性を向上させるため、異なるアベイラビリティ ゾーンにライターとリーダーをセットアップすることもできます。
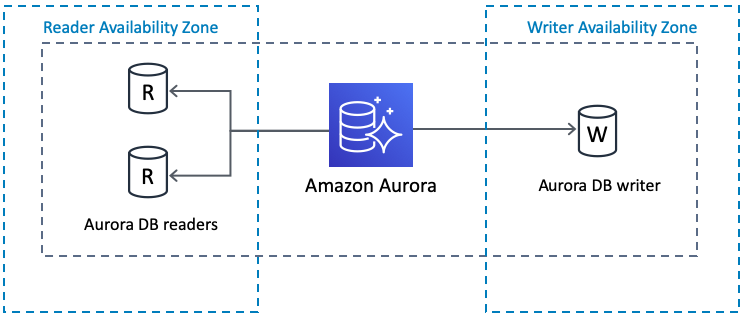
ライターが失敗した場合、Aurora はリーダーの 1 つを自動的にプロモートしてライターにします。詳細は「Amazon Aurora の特徴: PostgreSQL 互換エディション」 を参照してください。
Amazon Aurora クラスタ データベースは次の製品でサポートされています。
Amazon CloudWatch による基本的なモニタリングおよび中央ログ
また、クイック スタートでは、Amazon CloudWatch によるノード管理も提供されます。これにより、各ノードの CPU、ディスク、およびネットワーク アクティビティのすべてを、事前設定済みの CloudWatch ダッシュボードから追跡できます。ダッシュボードは、最新のログ出力を表示するように設定され、後で監視および指標を追加してカスタマイズできます。
既定では、Amazon CloudWatch は各ノードからログを収集し、単一の中央ソースに保存します。この中央ログにより、デプロイのログ データをより簡単かつ効果的に検索および分析できます。詳細については、「CloudWatch Logs Insights を使用したログ データの分析」および「フィルター パターンを使用したログ データ検索」を参照してください。
オート スケーリング グループ
この Quick Start は Auto Scaling グループを使用しますが、これはクラスタ ノード数の静的制御のみを目的としています。Auto Scaling を使用してクラスタのサイズを動的に拡張することは推奨されません。アプリケーション ノードのクラスタへの追加には通常 20 分以上かかりますが、この速度では突然の負荷のスパイクに対処できません。
高負荷および低負荷の期間を特定できる場合、それに応じてアプリ ノード クラスタのスケーリングをスケジュールできます。詳細については、「Amazon EC2 Auto Scaling のスケジュールに基づくスケーリング」を参照してください。組織の負荷の傾向を調査するには、デプロイのパフォーマンスを監視する必要があります。
AWS クイック スタートの CloudFormation テンプレートのカスタマイズ
迅速な実装のため、クイック スタートでは手動インストールと同じレベルのカスタマイズは提供していません。代わりに、クイック スタートで使用される CloudFormation テンプレートを必要に応じてカスタマイズできます。これらのテンプレートは以下のリポジトリで入手できます。
サポート対象の AWS リージョン
すべての地域が Data Center 製品の実行に必要なサービスを提供しているわけではありません。Amazon Elastic File System (EFS) に対応している地域を選択する必要があります。対応地域は次のとおりです。
アメリカ
バージニア北部
オハイオ
オレゴン
北カリフォルニア
モントリオール
ヨーロッパ / 中東 / アフリカ
アイルランド
フランクフルト
ロンドン
パリ
アジア太平洋
シンガポール
東京
シドニー
ソウル
ムンバイ
このリストの最終更新日は 2019 年 6 月 20 日です。
各リージョンで提供されるサービスは随時変更される可能性があります。使用したいリージョンがこの一覧に含まれていない場合、そこが EFS をサポートしているかどうかを AWS ドキュメントの「リージョンごとの製品サービス」の表でご確認ください。