パフォーマンスのトラブルシューティング ツールに関するベスト プラクティス
プラットフォームについて: Server および Data Center のみ。この記事は、Server および Data Center プラットフォームのアトラシアン製品にのみ適用されます。
サーバー*製品のサポートは 2024 年 2 月 15 日に終了しました。サーバー製品を利用している場合は、アトラシアンのサーバー製品のサポート終了のお知らせページにて移行オプションをご確認ください。
*Fisheye および Crucible は除く
問題
これは、インスタンスで発生していることを確認したり、アトラシアン サポートを最大限に活用したりするための方法を探しているシステム管理者向けのベスト プラクティス ガイドです。アトラシアン製品の診断データを監視および分析するための推奨ツールをご紹介し、これらの情報をアトラシアン株式会社に提供するための最適な方法をご案内します。このガイドは診断アーティファクト別に分類されており、推奨されるツール、およびそれらを最大限に活用するための方法について紹介します。
このドキュメントでリンクされているナレッジベース記事は特定の製品を参照する場合がありますが、記載されている技術は汎用的に使用できるものです。
以降は、発生している問題に応じた推奨ツールの概要です。
インスタンス全体が遅い
スレッド ダンプ、ガベージ コレクションのログ、データベース プロファイリング、CPU プロファイリング、ディスク速度、アクセス ログ、ページ (アプリケーション) プロファイリング
インスタンス全体でレスポンスが返されない
スレッド ダンプ、ガベージ コレクションのログ、データベース プロファイリング、CPU プロファイリング、ディスク速度、アクセス ログ、ページ (アプリケーション) プロファイリング
アプリケーションの特定の機能が遅い
スレッド ダンプ、ガベージ コレクションのログ、データベース プロファイリング、クライアント側の診断、ページ (アプリケーション) プロファイリング
アプリケーション サーバーの負荷が高い (ただしデータベース サーバーには問題がないように見受けられる)
スレッド ダンプ、ガベージ コレクションのログ、CPU プロファイリング、ディスク速度、アクセス ログ、ページ (アプリケーション) プロファイリング
データベース サーバーの負荷が高い (ただしアプリケーション サーバーには問題がないように見受けられる)
スレッド ダンプ、データベース プロファイリング
OutOfMemory エラーまたは高いメモリ使用率
ヒープ ダンプ、ガベージ コレクションのログ
ツール
スレッド ダンプ
スレッド ダンプを生成すべきタイミング
スレッド ダンプは、パフォーマンスの問題を調査するためのもっとも便利なツールです。インスタンスの速度が低下していたり、インスタンスで停止が発生したりしている場合、スレッド ダンプを確認することで、その時間にインスタンスで発生していた出来事を確認できます。一連のスレッド ダンプを確認することで、インスタンスで特定の期間に発生していた出来事を確認できます。スレッド ダンプにより、アプリケーション コードにパフォーマンスの問題があるかどうかを確認できます。これはパフォーマンスの問題がもっとも頻繁に確認される箇所です。スレッド ダンプを確認することで、ほかに必要な診断要素を見つけられる場合もあります。
作成すべきスレッド ダンプの量やタイミングについての、簡単に利用できるような固定ルールはありませんが、インスタンスのパフォーマンスに問題が発生している一定の期間に定期的な間隔で取得されている場合、そのようなスレッド ダンプは調査に役立ちます。たとえばアトラシアン サポートでは、合計 6 個のスレッドダンプを 30 秒ごとに取得する形式を頻繁に使用しています。
使用すべきツール
For generating thread dumps, please follow the instructions in Generating a Thread Dump. We recommend using the method in Troubleshooting Jira performance with Thread dumps if using Linux, as the output of the CPU % can be correlated to a thread.
スレッド ダンプの処理について、アトラシアンのサポート チームでは TDA を使用および推奨しています。

TDA を使用することで、長期間実行されているスレッドの特定や、輻輳または競合のロックを行い、インスタンスでのスレッドの実行内容の概要を理解することができます。
ヒープ ダンプ
ヒープ ダンプを生成すべきタイミング
A heap dump is useful when the instance is running out of memory and the common causes have already been addressed. A heap dump gives us a breakdown of all the objects that exists in the java heap at the time it was taken. It's important to lower the size of the heap as much as possible before creating a heap dump, as a very large heap can make it harder to analyse as significant resources are required for large heap dumps. A heap dump can also be useful in conjunction with garbage collection logs.
使用すべきツール
For generating heap dumps, please follow the instructions in Generating a Heap Dump. Heap dumps can be configured to be automatically generated when an instance runs out of memory, or can be run manually. However, if a heap dump is not generated when an OutOfMemoryError is thrown, it is generally not at all useful.
For processing heap dumps, The Atlassian Support team uses and recommends Eclipse MAT.
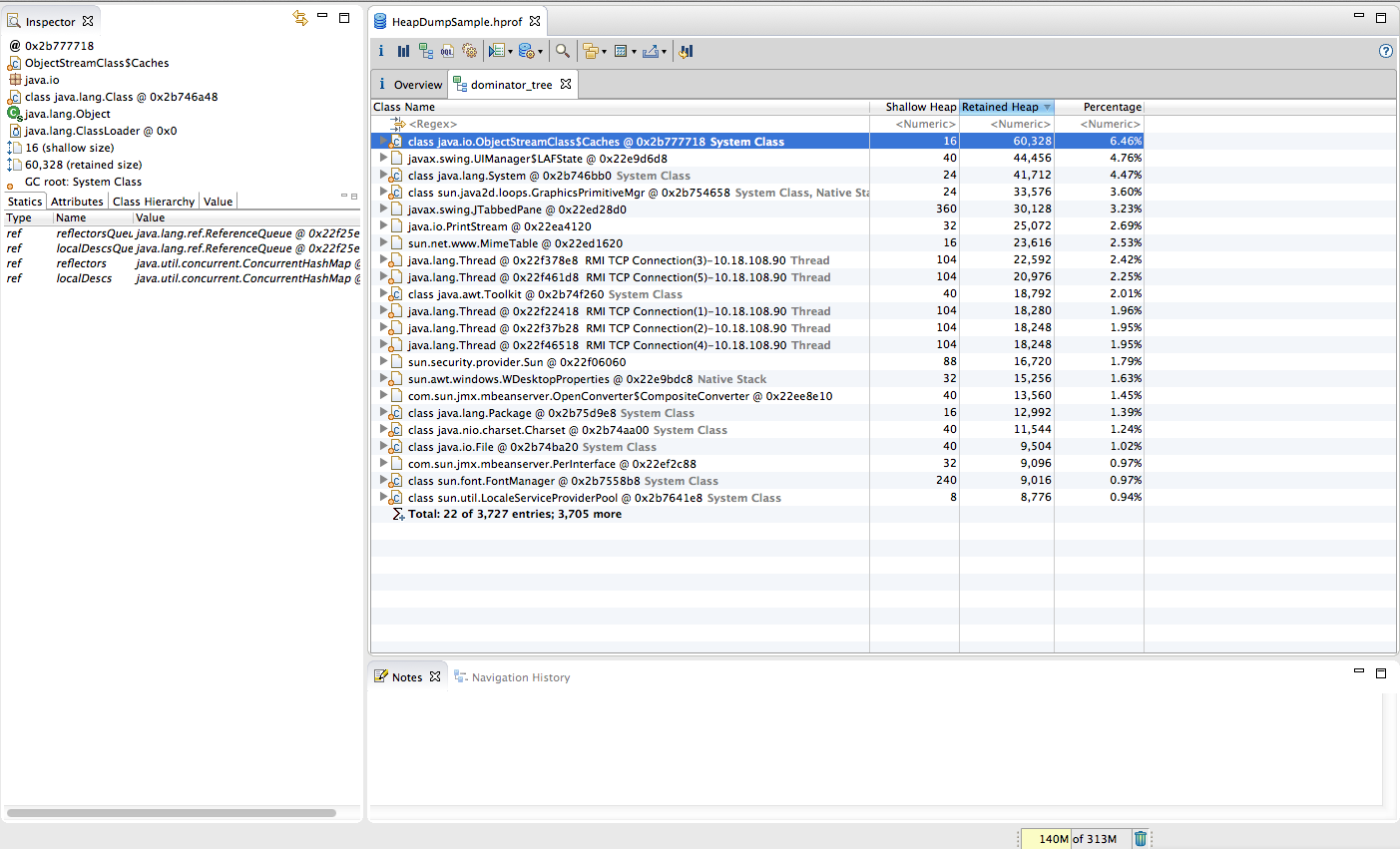
Eclipse MAT では、もっとも大量のヒープを使用しているスレッドの dominator tree (スレッドで右クリックして [Java Basics] > [Thread Stacks] を選択) を確認することで、そのスレッドのスタック トレースをすばやく簡単に参照できます。詳細情報については MAT のドキュメントをご参照ください。
ガベージ コレクション (GC) のログ
GC ログを生成すべきタイミング
Is Confluence becoming completely unresponsive for a while, and then recovering without any changes being made? General slowness that hasn't been attributed to the code itself (via thread dumps)? Perhaps the instance is consuming too much memory. If any of the above, you may be experiencing garbage collection problems. Our Garbage Collection (GC) Tuning Guide provides expansive detail on this, but in brief, the three performance goals of garbage collection is to affect the following:
- 遅延の軽減 - GC の実行に伴う、JVM による停止
- スループットの改善 - JVM が実際のアプリケーション用に利用可能なクロック時間の割合
- フットプリントの軽減 - ヒープ サイズ
使用すべきツール
To generate GC logs, please follow the instructions in How to Enable Garbage Collection (GC) Logging.
GC ログの処理について、アトラシアン サポートでは GCViewer を使用および推奨しています。

GCViewer は起動後の 1 分間のいくつかの部分的 GC を表示します。各行の意味については [View] メニュー ボタンをクリックします。
データベース プロファイリング
データベース プロファイリングを使用すべきタイミング
データベース サーバーの CPU 使用率が高まっているがアプリケーション サーバーは通常どおり実行されている場合や、スレッド ダンプを確認した結果、長期間実行されている多数のスレッドがデータベース接続を待機している場合、データベース プロファイリングを使用して、データベースでのクエリ実行のどの部分で時間がかかっているかを調べることができます。
使用すべきツール
See CPU profiling tools below. Additionally JProfiler can be used as detailed in Use jProfiler to analyse Jira application performance.
CPU プロファイリング
CPU プロファイリングを使用すべきタイミング
"top" コマンドを実行すると、アプリケーション サーバーでの CPU 使用率が高くなっている場合にそれを確認し、Confluence の速度低下を確認できます。スレッド ダンプのどの部分が CPU を消費しているかを検証するため、これは主にスレッド ダンプと組み合わせて使用されます。
使用すべきツール
ここではさまざまなオプションを利用できます。利用するツールは組織で構成済みのものに応じますが、次のものが推奨されます。
For Linux based instances, Troubleshooting Jira performance with Thread dumps includes a method of generating CPU profiling information without any paid tools.

JProfiler の実際の画面 - ここでは、プロファイルされた CPU 操作のうち、権限チェックがもっとも CPU を消費していることを確認できます。
クライアント側の診断
クライアント側の情報を確認すべきタイミング
アプリケーションにパフォーマンスの問題が見られるが、スレッド ダンプなどのツールで確認してもバックエンドには問題が見られない場合、ブラウザから情報を収集することができます。ネットワーク情報やコンソール ログで、フロントエンドのエラーがないかどうかを確認します。
使用すべきツール
Any browser's developer tools are capable of providing the information required, but Atlassian Support prefers Chrome due to the Chrome HAR viewer. This depends upon how the information is generated - different browsers have different means as in Generate HAR files and analyze web requests for Atlassian support.
クライアント側の診断情報を生成する方法
- Chrome のデベロッパー ツールバーを開きます (Chrome ウィンドウの空白部分で右クリックして [要素を検証] を選択するか、 ツールを開くためのその他の方法についてこちらのページを確認します)。
- [ネットワーク] タブに移動します (こちらで例を確認できます)。[ネットワーク] タブにテキストが表示されている場合、デベロッパー ツール ウィンドウの右上で、赤い丸のアイコンの横にある削除アイコンをクリックし、すべての既存のテキストを削除します、
- 速度が低下している任意の操作を実行します。
- ネットワーク ウィンドウにいくつかのリクエストが記録されます。この情報を HAR ファイルに保存します。手順についてはこちらをご確認ください。
- また、[コンソール] タブをクリックし、エラーが出力されていないかどうかを確認します (「コンソールで作業する方法」)。
- コンソールで出力されているテキストをファイルに保存します。
ネットワーク リクエストの HAR ファイル 1 つと、コンソール出力のログ ファイル 1 つの、合計 2 つのファイルを作成できていることを確認します。
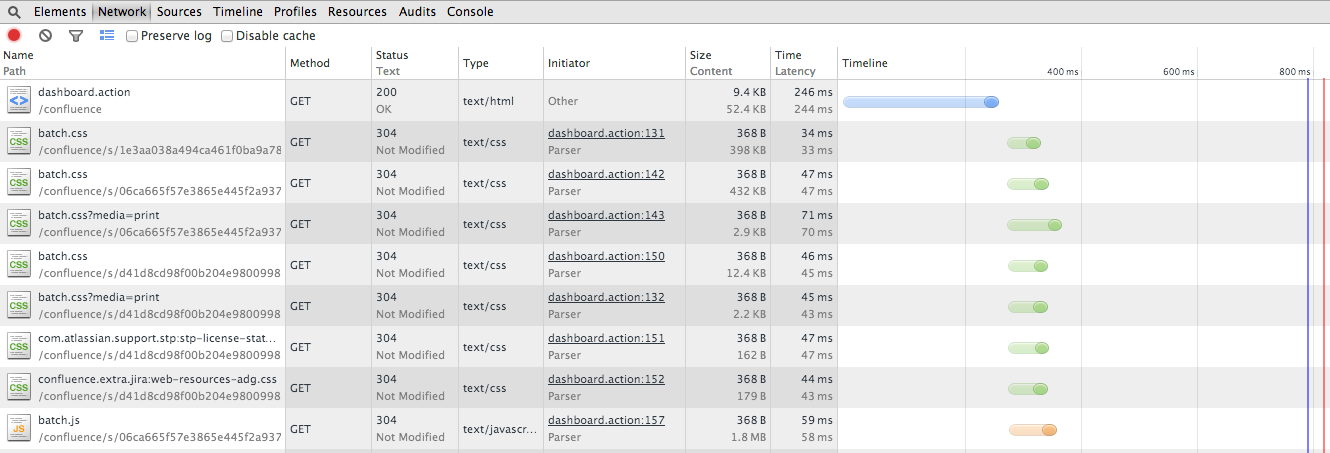
Confluence のダッシュボードを読み込んだ際に Chrome のネットワーク タブで収集された情報です。
Proxy bypassing
Slowness issues with some specific Confluence functionality can sometimes be caused by problems with the instance's configured proxy.
To troubleshoot this, it's recommended to try bypassing the proxy, by accessing Confluence directly through the server's IP address.
This can be done through either of these methods, depending on how the current network structure is configured:
While performing this test, it's often useful to generate another HAR file, as described above, to compare details between the two sets of proxied and non-proxied network requests.
ディスク速度
ディスク速度を確認すべきタイミング
アプリケーションの速度が低下しており、特にアプリケーションの次の領域でパフォーマンスの問題が見られる場合、ディスク速度を確認することをおすすめします。
- 再インデックス
- 検索
- 添付ファイル
- 課題ナビゲーター (Jira)
アクセス ログ
アクセス ログを確認すべきタイミング
アクセス ログは、インスタンスの使用状況の一般的なパターンを確認するための優れた方法です。特定の REST エンドポイントが頻繁にアクセスされていたり、特定の自動化が大量のリクエストを発生させていたりする状況を見つけることができます。
アクセス ログの有効化
For JIRA: User Access Logging
Fisheye/Crucible: Fisheye でアクセス ロギングを有効化する
For Confluence: How to Enable User Access Logging
Bitbucket Server: なし (常に有効)
使用すべきツール
For JIRA: Jira Access Log Analyzer
For Bitbucket Server (formerly known as Stash): Atlassian Stash and Bitbucket Server access log parser
ページのプロファイリング
ページ プロファイリングを使用すべきタイミング
特定のページや一部分でパフォーマンスの問題が発生している場合、ページ プロファイリングを使用して各メソッドの実行にかかる時間を表示することで、速度低下の原因になっているメソッドの特定に役立てることができます。速度低下が全体的に見られる場合、ほかの手段を利用することをおすすめします。
使用すべきツール
Jira と Confluence では組み込みのツールが提供されています。
- Confluence: ページ リクエスト プロファイリングを使用した、パフォーマンス低下のトラブルシューティング
- For JIRA: JIRA - Profiling

Confluence 管理領域の一般設定ページ