Jira Data Center: AWS でのエンタープライズ インスタンスの推奨インフラストラクチャ
このページの内容
デプロイ方法としての AWS クイック スタート テンプレートはアトラシアンではサポートされなくなりました。テンプレートは今後も利用できますが、保守や更新は行われません。
より効率的で堅牢なインフラストラクチャと運用のセットアップのために、Helm チャートを使用して Data Center 製品を Kubernetes クラスターにデプロイすることをお勧めします。Kubernetes へのデプロイに関する詳細はこちらをご確認ください。
AWS は、現在、AWS クイック スタート テンプレートで使用される起動設定を起動テンプレートに切り替えることを推奨していますが、AWS クイック スタート テンプレートのサポートは終了しているため、アトラシアンではこの切り替えを行う予定はありません。そのため、このテンプレートを使用して起動設定を作成することはできません。
「Jira Data Center のサイズ プロファイル」では、インスタンスが "Small"、"Medium"、"Large"、または "XLarge" のどれに該当するかを確認するためのシンプルなガイドラインを示しています。これらのサイズ プロファイルはさまざまな Server および Data Center のケース スタディに基づいており、あらゆるインフラストラクチャ サイズおよび構成のインスタンスを網羅しています。負荷プロファイルを把握しておくことは、企業の成長を計画したり、メトリクスの増長を確認したり、インフラストラクチャの適合性を簡単に確認したりするのに役立ちます。
負荷が増加して "Large" または "XLarge" サイズに近づいてきたら、定期的にインフラストラクチャを評価する必要ががあります。環境内でパフォーマンスや安定性の問題が発生し始めたら、クラスタ (またはクラスタ対応) インフラストラクチャへの移行を検討します。これを行う際は、効果的に行うための方法は常に明確であるとは限らないということに注意します。たとえば、成長しつつある "Medium" サイズのインスタンスにアプリケーション ノードを追加してもパフォーマンスが向上するとは限りません (低下する場合もあります)。
アトラシアンではお客様によるインフラストラクチャの設定または成長の計画立案をサポートするため、一般的な "Medium"、"Large" および "XLarge" サイズのインスタンスで一連のパフォーマンス テストを実施しました。これらのテストは、ご利用のクラスタ化されたデプロイメントのアプリケーションおよびデータベース ノードに有用なデータ主導の推奨事項を確認できるように設計されています。これらの推奨設定は、プロジェクト化されたコンテンツおよびトラフィックのサイズに合った適切なクラスタ化環境の計画に役立てることができます。
新しい AWS Compute テンプレート
この記事では、以前にテストした AWS テンプレート (c5、c4、m4) について説明しています。m6i などの類似する認定エンタープライズグレードのテンプレートは、新しいバージョンの Jira に対して内部的に実行されていますが、新しいテンプレートのパフォーマンスと時間あたりのコストはこのページで数値化されていません。
このページの推奨事項は古いバージョンの Jira (8.5) をベースにしています。
パフォーマンスの結果は、サードパーティ製アプリ、データ、トラフィック、インスタンス タイプなどの多くの要因によって異なります。このため、弊社で実現したパフォーマンスをご利用の環境では再現できない可能性があります。
これらの推奨設定の詳細を確認するため、テストの方法論を必ずお読みください。
パフォーマンスの監視の詳細については、「Jira Data Center のサンプル デプロイと監視戦略」を参照してください。
推奨設定の概要
アトラシアンで実行したテストから得られたベンチマークおよび構成の分析に基づき、Jira Large および Jira XL のアプリケーション ノードとデータベース ノードに対して、次のような費用対効果とフォールト トレラントの推奨設定を導きました。
テスト方法の詳細をお読みください。
ベスト パフォーマンスと信頼性のための推奨設定 - Jira L
Large サイズのプロファイルのお客様には、最高のパフォーマンスとフォールト トレランスを保証する Jira 用 c4.8xlarge 3 ノード8.5 をおすすめします。テスト結果により、少ないノード数で強力なハードウェアを使用すると、最適なパフォーマンスを実現できることが示されています。
Jira 8.13 の場合、最高のパフォーマンスとフォールト トレランスを保証する c5.9xlarge 3ノードをおすすめします。テスト結果により、少ないノード数で比較的強力なハードウェアを使用すると、最適なパフォーマンスを実現できることが示されています。
また、目的のスループットを実現する最小データベース要件として、m4.2xlarge (8.13) または m4.4xlarge (8.5) をおすすめします。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.9xlarge x 3 | m4.2xlarge | 0.859 | 4.99 |
| Jira 8.5 | c4.8xlarge x 3 | m4.4xlarge | 0.742 | 7.16 |
インスタンスの詳細:
- m4.2xlarge = 8 vCPU および 32 GiB RAM
- c4.8xlarge = 36 vCPU および 60 GiB RAM
- c5.9xlarge = 36 vCPU および 72 GiB RAM
- m4.4xlarge = 16 vCPU および 64 GiB RAM
費用対効果および最適なパフォーマンスのための推奨設定 - Jira L
Jira 8.5 の場合、テスト結果は、少ないノード数で強力なハードウェアを使用すると、最適なパフォーマンスを実現できることを示しています。使用したインスタンス タイプ (c4.8xlarge) の仕様は 36 CPU、60 GB RAM でした。このタイプのノードを 2 つまたは 3 つ使用することで、妥当なコストで優れたパフォーマンスを確保できます。また、目的のスループットを実現する最小データベース要件として、m4.xlargeをおすすめします。
Jira 8.13の場合、テスト結果により、性能の少し低いハードウェアを使用すると、低コストで最適なパフォーマンスを実現できることが示されています。使用したインスタンス タイプ (c5.2xlarge) の仕様は 8 CPU、16 GB RAM でした。このタイプのノードを 3 つまたは 4 つ使用することで、妥当なコストで優れたパフォーマンスを確保できます。また、目的のスループットを実現する最小データベース要件として、m4.xlarge をおすすめします。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.841 | 1.22 |
| Jira 8.5 | c4.8xlarge x 2 | m4.xlarge | 0.742 | 4.97 |
インスタンスの詳細:
- c4.8xlarge = 36 vCPU および 60 GiB RAM
- c5.2xlarge = 8 vCPU および 16 GiB RAM
- m4.xlarge = 4 vCPU および 16 GiB RAM
ベスト パフォーマンスと信頼性のための推奨設定 - Jira XLarge
テスト結果により、優れた性能のハードウェアを使用すると、最適なパフォーマンスを実現できることが示されています。そのため、コストよりもパフォーマンスを優先する XLarge プロファイルのお客様には、Jira 用 c5.9xlarge 6 ノード8.5 をおすすめします。このノード数を使用することで、最高のパフォーマンス、スループット、およびフォールト トレランスを保証できます。使用するインスタンス タイプ (c5.9xlarge) の仕様は 36 CPU、72 GB RAM でした。また、目的のスループットを実現する最小データベース要件として、m4.4xlarge をおすすめします。
Jira 8.13 の場合、c5.4xlarge 2 ノードをおすすめします。このノード数を使用することで、最高のパフォーマンス、スループット、およびフォールト トレランスを保証できます。使用するインスタンス タイプ (c5.4xlarge) の仕様は 16 CPU、32 GB RAM でした。また、目的のスループットを実現する最小データベース要件として、m4.4xlarge をおすすめします。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.4xlarge x 2 | m4.4xlarge | 0.918 | 2.16 |
| Jira 8.5 | c5.9xlarge x 6 | m4.4xlarge | 0.803 | 11.51 |
インスタンスの詳細:
- m4.4xlarge = 16 vCPU および 64 GiB RAM
- c5.9xlarge = 36 vCPU および 72 GiB RAM
- c5.4xlarge = 16 vCPU および 32 GiB RAM
費用対効果および最適なパフォーマンスのための推奨設定 - Jira XLarge
興味深いことに、Jira 8.13 では、c5.2xlarge インスタンス (8 CPU および 16 GB RAM) を 3 ノードで使用した場合、パフォーマンスは c5.4xlarge の場合よりわずかに低下しましたが、Apdex は引き続き 0.70 を超えました。この動作は、テスト全体を通じて一貫していました。したがって、費用対効果を重視する XLarge プロファイルのお客様には、c5.2xlarge 3 または 4 ノード (より優れたフォールト トレランスを実現する場合は 4 ノード) をおすすめします。
また、この動作は Jira 8.5 でも見られ、c5.4xlarge を使用したときに優れた Apdex およひスループットが確認されています。このため、Jira 8.5 の場合は、c5.4xlarge 6 または 7 ノード (より優れたフォールト トレランスを希望する場合は 7 ノード) をおすすめします。なお、c5.9xlarge 3 ノードで同様の Apdex が得られました。これは c5.4xlarge の場合よりもわずかに高額です。
Jira 8.5 と Jira 8.13 の目的のスループットを実現する最小データベース要件として、m4.xlarge をおすすめします。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.905 | 1.22 |
| Jira 8.5 | c5.4xlarge x 6 | m4.xlarge | 0.720 | 4.96 |
インスタンスの詳細:
- m4.xlarge = 4 vCPU および 16 GiB RAM
- c5.4xlarge = 16 vCPU および 32 GiB RAM
- c5.2xlarge = 8 vCPU および 16 GiB RAM
1 時間あたりのコスト
1 アトラシアンの推奨設定では、各構成の相対的な価格を比較できるよう、1 時間当たりのコストを見積もっています。アプリケーション ロード バランサなどのすべてのサブコンポーネントを含めた、Jira インスタンス全体のコストを計算しています。
これらの金額は USD で、リージョンはオハイオであり、2020 年 10 月時点の値です。
アプローチ
すべてのテストを AWS (Amazon Web Services) 環境で実施しました。これにより、多くのテストを簡単に定義および自動化し、大規模で信頼性の高いテスト結果のサンプルを取得することができます。
テスト インフラストラクチャの各部分は、すべての AWS ユーザーが利用できる標準の AWS コンポーネントです。つまり、お客様はアトラシアンの推奨設定を簡単にデプロイできます。これを実現するために、Jira Data Center のデプロイに AWS クイック スタートを使用することもできます。
標準の AWS コンポーネントを使用したため、お客様は AWS ドキュメントでそれらの仕様を確認できます。お客様が別のクラウド プラットフォームまたは特注のクラスタ ソリューションを使用することを希望している場合、ここで同等のコンポーネントや構成を見つけることができます。
Considerations
分析用に大量のベンチマーク サンプルを収集するため、テストは簡単にセットアップしてレプリケートできるよう設計されています。このため、お客様のインフラストラクチャ計画でベンチマークや推奨設定を参照する際には、以下を考慮してください。
コア製品に最適な設定を見つけることに焦点を当てていたため、テスト インスタンスへのアプリのインストールは行っていません。お客様のインフラストラクチャを設計する際には、インストールしたいアプリがパフォーマンスに与える影響を考慮する必要があります。
Large のテストでは、MySQL 5.6.42 をデフォルト設定で使用しました (ただし接続の最大数を 151 接続に増やしました)。XLarge のテストでは、バッファ プールを 40 G に、ログ ファイルのサイズを 2 GB に増やしました。
アトラシアンのテスト環境では、同じサブネット上でホストされている専用の AWS インフラストラクチャを使用しています。これによりネットワーク遅延が短縮されます。
テスト手法
各テストでは、異なる AWS 環境にある Jira データ セットに同じ量のトラフィックを適用しました。Jira アプリケーション ノードとデータベース ノードのそれぞれに最適な推奨設定を見つける、2 種類のテストを実施しました。
テスト シリーズ 1: 最初のテスト シリーズでは、アプリケーション ノードに使用する AWS 仮想マシン タイプ (およびその数) を見つけようとしました。
Large インスタンスのテストでは、Jira バージョンに応じて、データベースに 1 つの m4.2xlarge、m4.4xlarge、および m4.xlargeノードを使用しました。
XLarge の場合、Jira バージョンに応じて、データベースに m4.4xlarge / m4.xlarge ノードを使用しました。
テスト シリーズ 2: 2 番目のテスト シリーズでは、データベース用の異なる仮想マシン タイプのベンチマークを評価しました。ここでは、テスト シリーズ 1 で最高のパフォーマンスを示した 2 つのアプリケーション ノード構成に対して異なる仮想マシン タイプをテストしました。
L では、これらは 2 つと 3 つの c4.8xlarge (Jira 8.5)、3 つの c5.2xlarge、c5.9xlarge (Jira 8.13) でした。
XLarge 8.13 の場合、これらは 3 つの c5.2xlarge と 2 つの c5.4xlarge でした。これらのアプリケーション ノード構成が最高の Apdex スコアを示しました。XLarge 8.5 の場合、これらは 6 つの c5.9xlarge でした。
ベンチマークの信頼性を確保するため、それぞれの構成を 2 回ずつテストしました。アトラシアンでは、1 番目と 2 番目のテスト シリーズを、その時点で利用可能な長期サポート リリースだった Jira Data Center 8.13 と Jira Data Center 8.5 で実行しました。
Large インスタンス テストのデータ セット
Large インスタンス テストの負荷プロファイル
XLarge インスタンス テストのデータ セット
XLarge インスタンス テストの負荷プロファイル
ベンチマーク
各テストで、許容可能なパフォーマンスのしきい値として Apdex のスコア 0.7 を使用しました。この Apdex では、1 秒の応答時間が許容可能なしきい値であるのに対し、4 秒を超える場合はすべて不満を表すしきい値とみなします。
ここに表示される Apdex は、本番環境と直接一致しない場合があることにご注意ください。テスト環境には一貫性のあるピーク負荷を持つアプリやカスタム連携は含まれていなかったため、お客様の環境で実行中の本番環境インスタンスとは異なる場合があります。
アーキテクチャ
各構成は、AWS 上に新しくデプロイされた Jira Data Center インスタンスでテストされました。
| "Large" サイズのインスタンス | "XLarge" サイズのインスタンス |
|---|---|
|
|


Jira Large の設定の詳細
Jira XLarge の設定の詳細
テストの詳細: "Large" インスタンス
最初のテスト シリーズでは、アプリケーション ノードに使用する AWS 仮想マシン タイプ (およびその数) を見つけようとしました。このテスト シリーズでは、Jira アプリケーション ノードで、次の仮想マシン タイプのベンチマークを確認しました。
c5.2xlarge
c5.4xlarge
c4.8xlarge
c5.18xlarge
Jira のバージョンに応じて、データベースに 1 つの m4.2xlarge、m4.4xlarge または m4.xlarge ノードを使用しました。
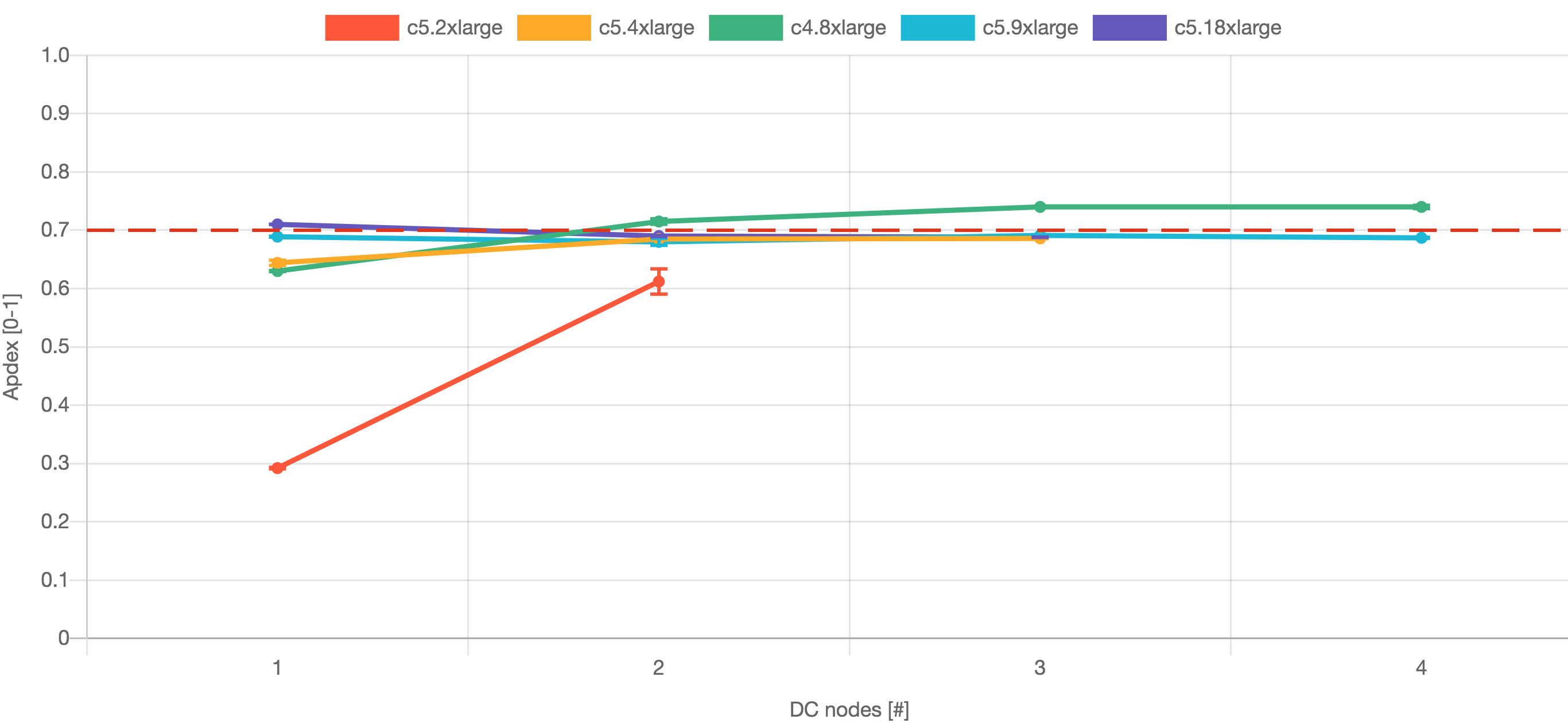
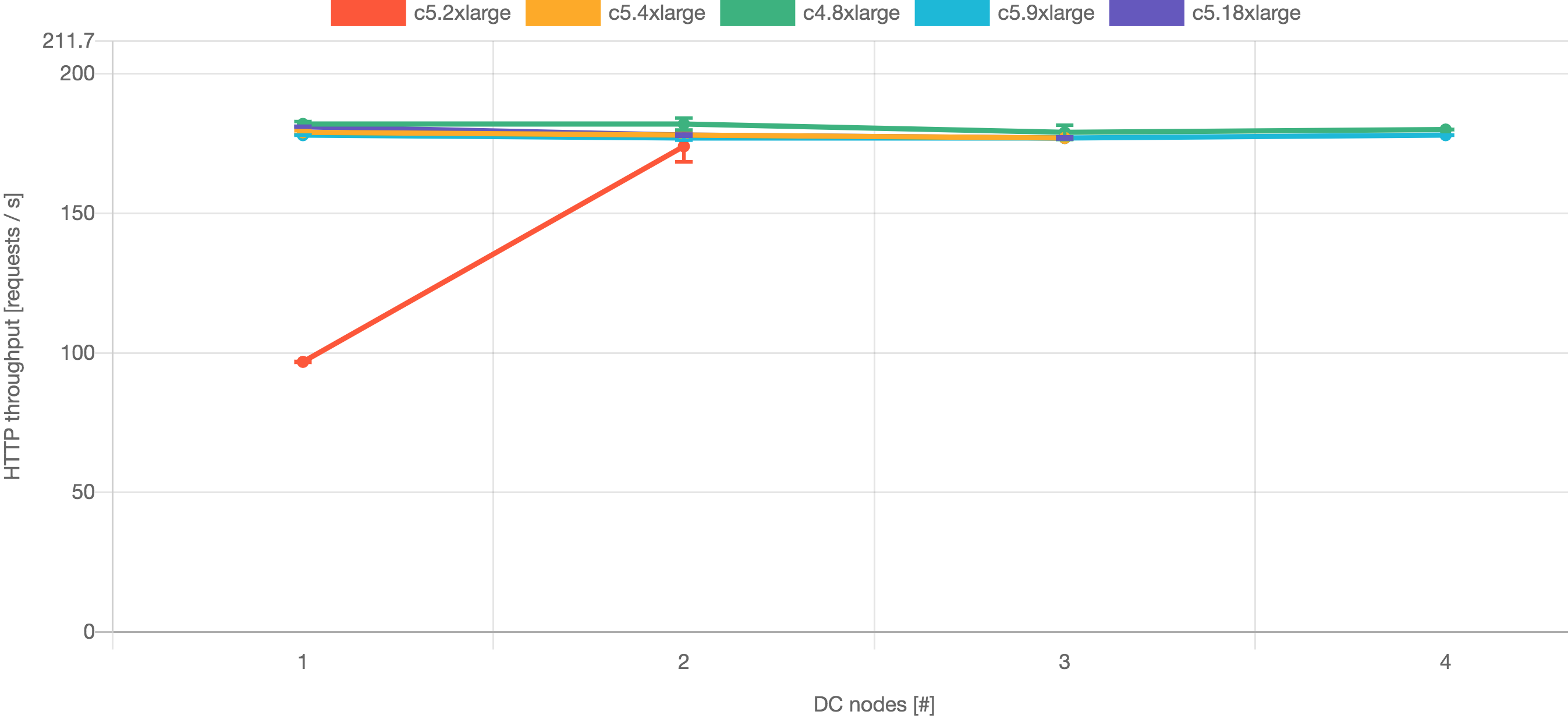
次のグラフは、各テストでの実際の Apdex ベンチマークを示しています。
| Jira 8.13 – Apdex |
|---|
|

| Jira 8.5 – Apdex |
|---|
|
| Jira 8.13 – スループット |
|---|
|

| Jira 8.5 – スループット |
|---|
|
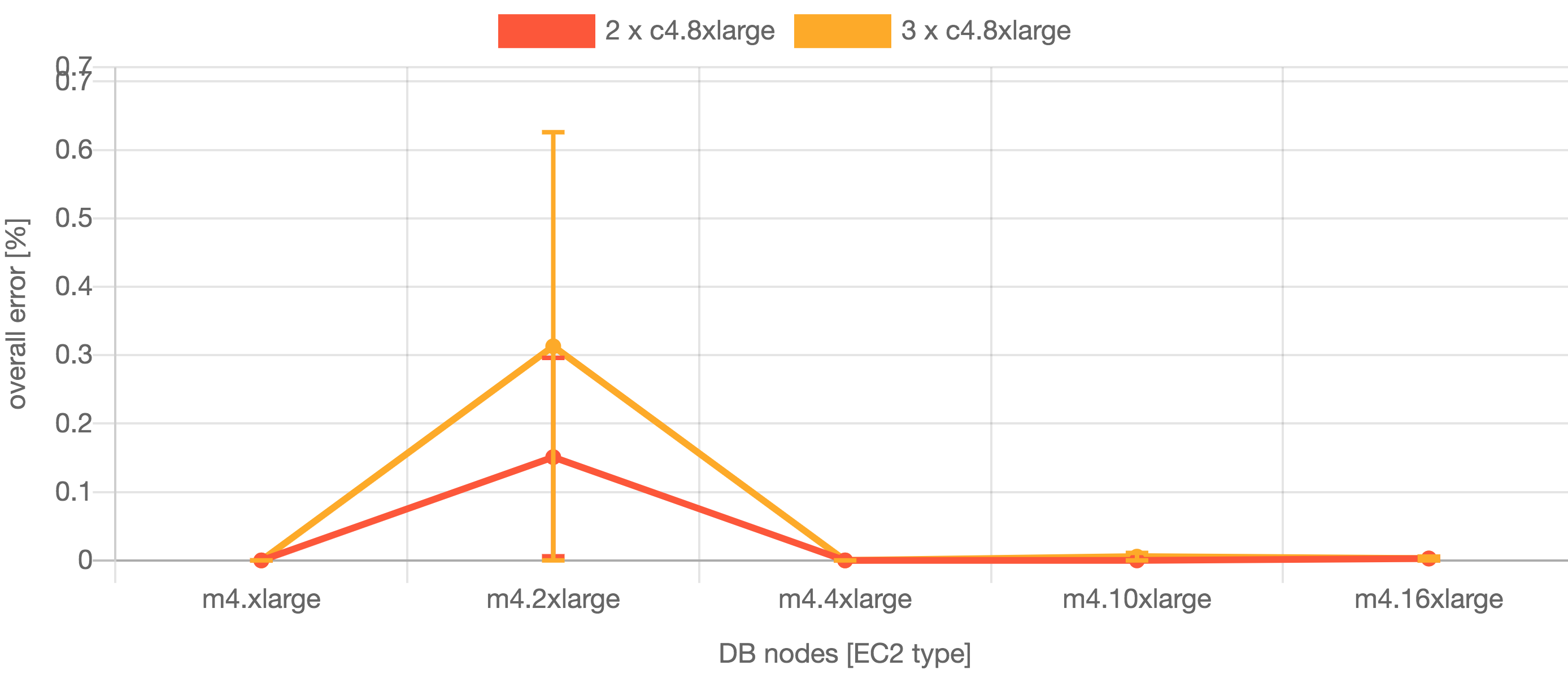
| Jira 8.13 – アクションの失敗がユーザーに確認される頻度 |
|---|
|

| Jira 8.5 – アクションの失敗がユーザーに確認される頻度 |
|---|
|
| Jira 8.13 – アクションのエラーの最大数 |
|---|
|

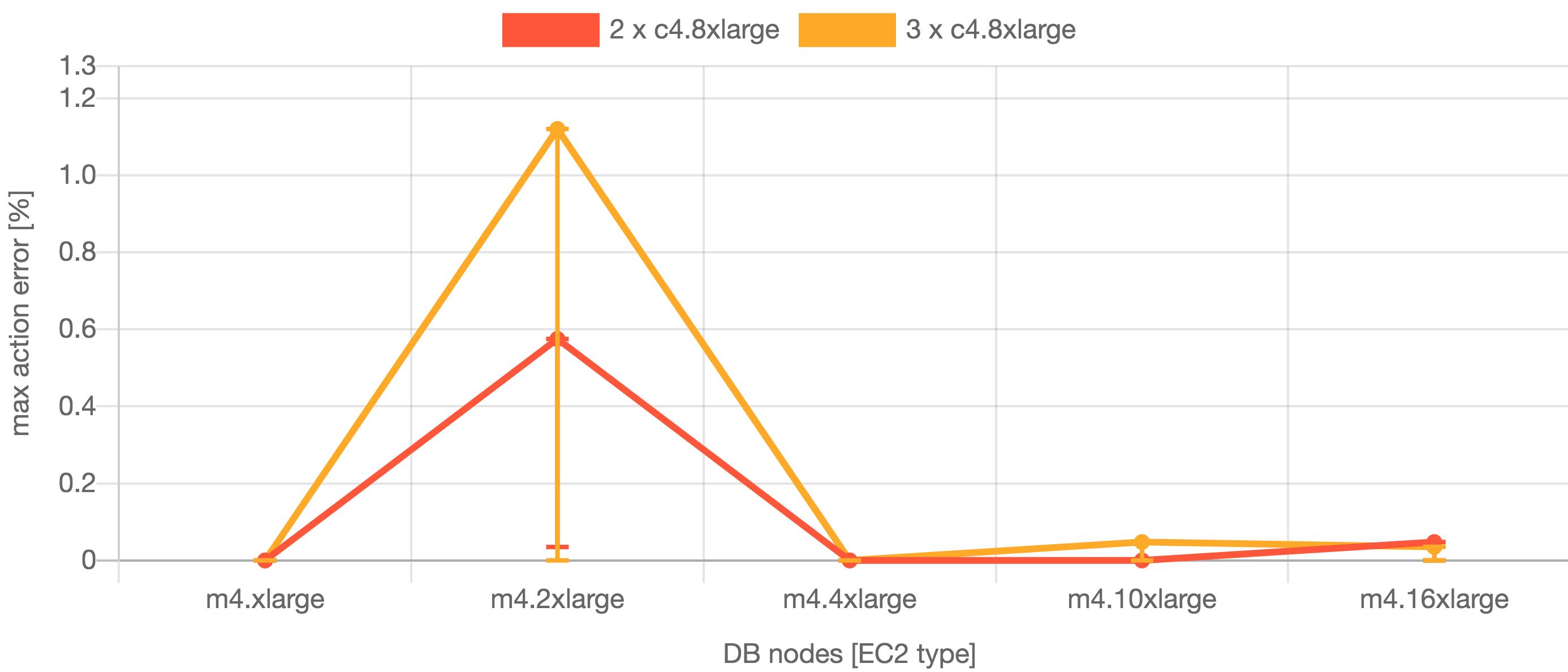
| Jira 8.5 – アクションのエラーの最大数 |
|---|
|

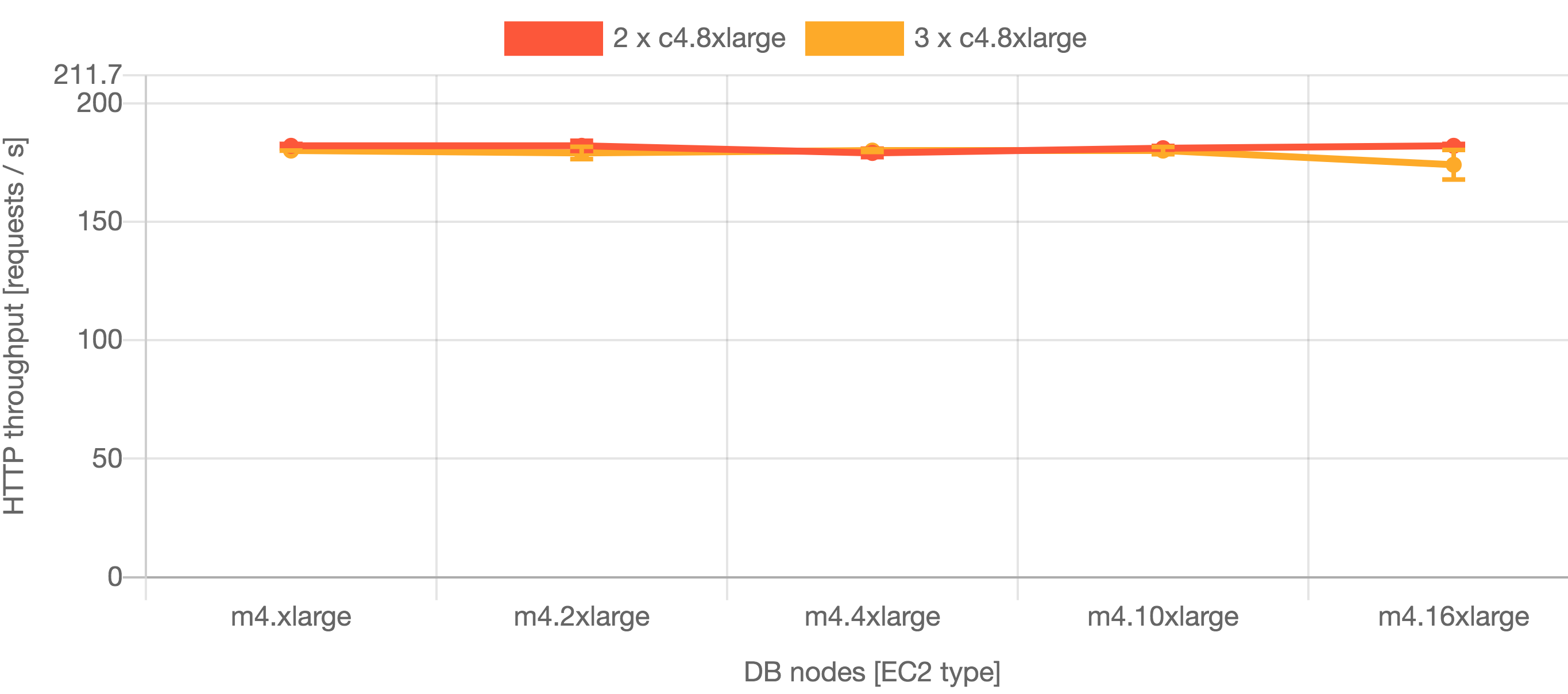
これらの結果は、c4.8xlarge ノードからの Jira 8.5 で最高のパフォーマンスが得られたことを示しています。Jira 8.5 で高可用性を確保するには 3 つ以上のノードが必要となります。Jira 8.13 の場合、最高のパフォーマンスは c5.9xlarge ノードから得られます。Jira 8.13 で高可用性を確保するには 2 つ以上のノードが必要となります。
c4.8xlarge のハードウェア仕様は 36 CPU および 60 GB RAM です。より大きなハードウェアを使用したテスト (c5.18xlarge) では、Jira 8.5 のパフォーマンスは改善しませんでした。また、ノードを追加してもパフォーマンスの改善は見られませんでした。
c5.9xlarge のハードウェア仕様は 36 CPU および 72 GB RAM です。より大きなハードウェアを使用したテスト (c5.18xlarge)では、Jira 8.13 のパフォーマンスは改善しませんでした。ノードを追加してもわずかなパフォーマンスの改善しか見られませんでした。
結論として、Large プロファイルのお客様には、c4.8xlarge 3 または 4 ノード (Jira 8.5)、c5.9xlarge 2 または 3 ノード (Jira 8.13) をおすすめします。
これらのノードの詳細については、「Amazon EC2 C4 インスタンス」を参照してください。
テスト シリーズから、Jira アプリケーションでは、c4.8xlarge 3 または 4 ノードを使用すると Apdex 結果が最高になることを確認しました。この情報を使用して次のテスト段階に移行し、データベース ノードに最適な構成をテストしました。
ここでは、両方の Jira アプリケーション ノード構成に対して、データベース ノードの次の仮想マシン タイプのベンチマークを確認しました。
m4.16xlarge
m4.xlarge
m4.2xlarge
- m4.4xlarge
- m4.10xlarge
| Jira 8.13 – Apex |
|---|
|
| Jira 8.5 – Apdex |
|---|
|

Jira 8.13 – スループット |
|---|
|
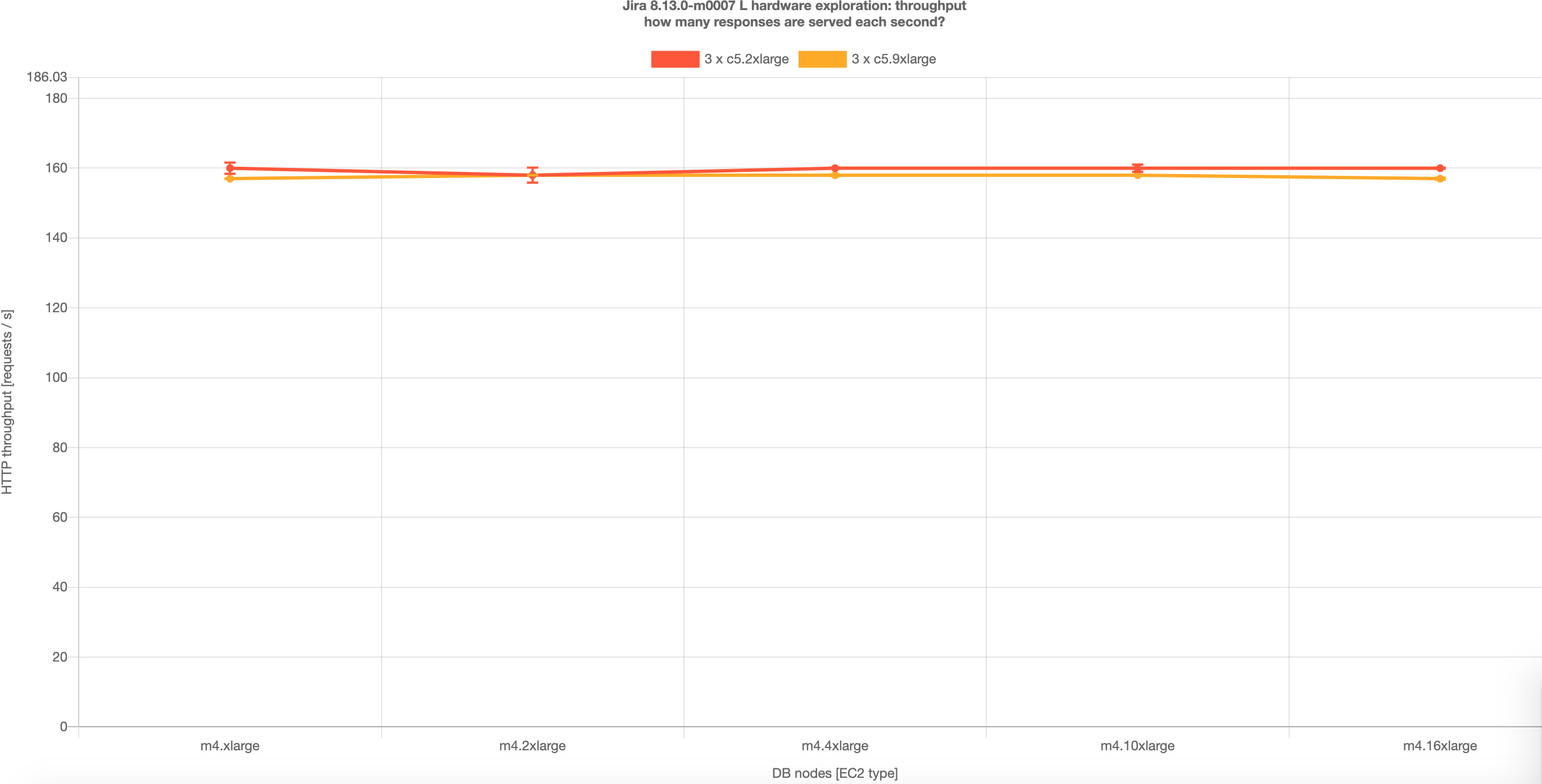
| Jira 8.5 – スループット |
|---|
|
| Jira 8.13 – アクションの失敗がユーザーに確認される頻度 |
|---|
|
| Jira 8.5 – アクションの失敗がユーザーに確認される頻度 |
|---|
|
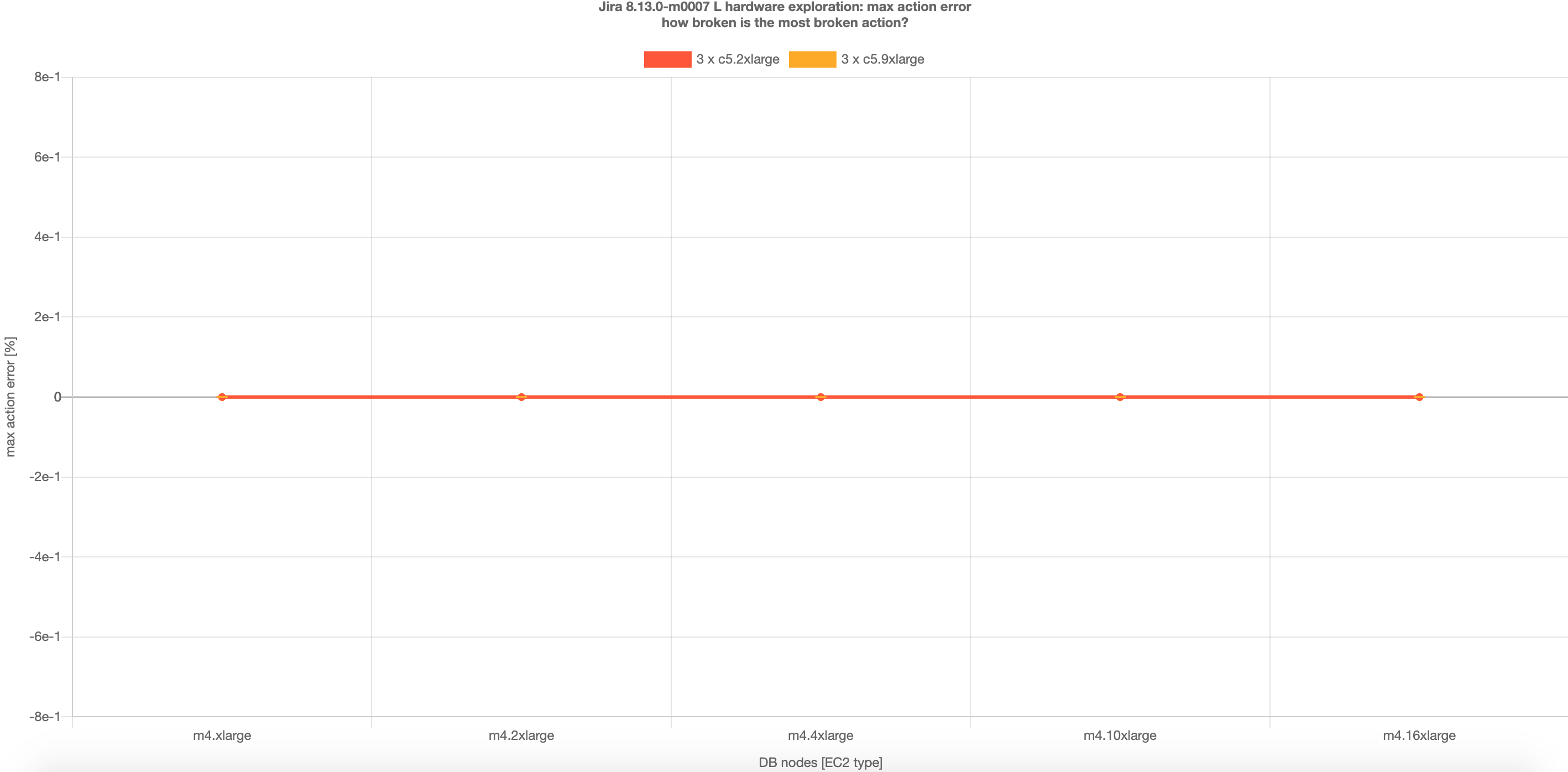
| Jira 8.13 – アクションのエラーの最大数 |
|---|
|
| Jira 8.5 – アクションのエラーの最大数 |
|---|
|
データベース接続プールは、デフォルトの 20 (最小および最大サイズ) を使用するように構成されています。
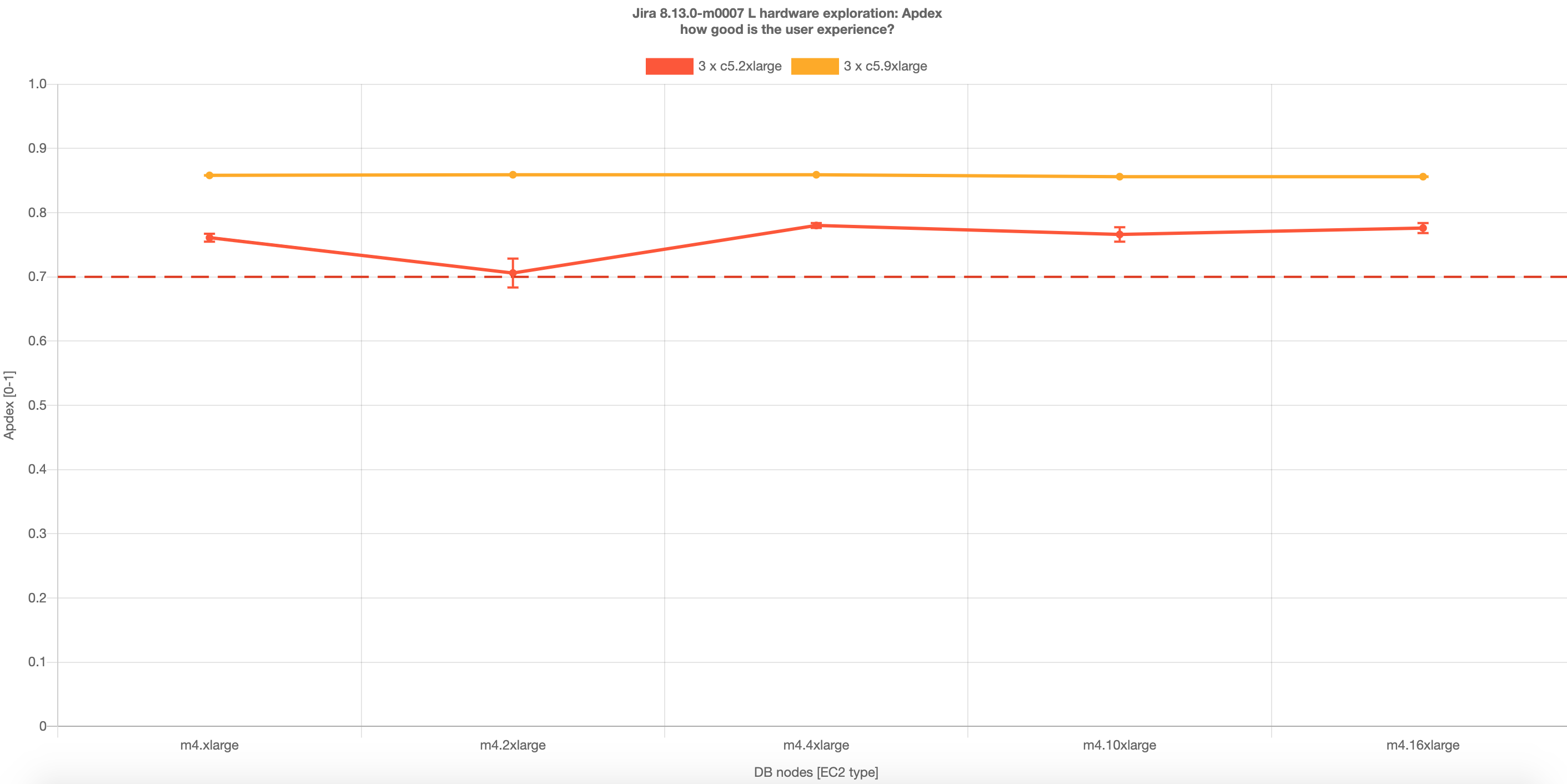
興味深いことに、テストでは、m4.xlarge のデータベースで十分なスループットとパフォーマンスが確認されました。つまり、Large プロファイルの負荷の場合、目的のスループットを実現する最小データベース要件として、m4.xlarge を使用する必要があります。ただし、優れたパフォーマンスを実現する場合、m4.4xlarge または m4.2xlarge をおすすめします。
テストの詳細: "XLarge" インスタンス
最初のテスト シリーズでは、アプリケーション ノードに使用する AWS 仮想マシン タイプ (およびその数) を見つけようとしました。このテスト シリーズでは、Jira アプリケーション ノードで、次の仮想マシン タイプのベンチマークを確認しました。
c5.2xlarge
c5.4xlarge
c4.8xlarge
- c5.9xlarge
c5.18xlarge
1 つの m4.4xlarge ノードを Jira 8.13 のデータベースに使用しました。Jira 8.5 の場合、m.4xlarge および m4.4xlarge を使用しました。m4.xlarge は、Jira 8.5 の XLarge データ セットを処理できる最小のデータベースでした。
次のグラフは、各テストでの実際の Apdex ベンチマークを示しています。
| Jira 8.13 – Apex |
|---|
|

| Jira 8.5 – Apex |
|---|
|

| Jira 8.13 – アクションの失敗がユーザーに確認される頻度 |
|---|
|

| Jira 8.5 – アクションの失敗がユーザーに確認される頻度 |
|---|
|

| Jira 8.13 – スループット |
|---|
|

| Jira 8.5 – スループット |
|---|
|

| Jira 8.13 – アクションのエラーの最大数 |
|---|
|

| Jira 8.5 – アクションのエラーの最大数 |
|---|
|

これらの結果は、c5.9xlarge ノード (Jira 8.5) および c5.4xlarge (Jira 8.13) で最高のパフォーマンスが得られたことを示しています (ただし、c5.9xlarge と c5.4xlarge 間の差異はわずかです)。これらの結果に基づき、0.7 を超える Apdex を提供するには、Jira 8.5 の場合は 3 つ以上のノード、Jira 8.13 の場合は 1 つのみノードが必要です。Jira 8.13 では 2 ノード、Jira 8.5 では 6 ノードの場合、Apdex スコアは最高になりました。さらに、Jira 8.13 では 2 ノード、Jira 8.5 では 6 ノードの場合、インスタンスは顕著なスループットを達成しました。
Jira 8.13 の場合、3c5.2xlarge ノードが 0.905 の Apdex に到達することも興味深い点です。
このインスタンス タイプ (c5.9xlarge) のハードウェア仕様は 36 CPU および 72 GB RAM です。
このインスタンス タイプ (c5.4xlarge) のハードウェア仕様は 16 CPU および 32 GB RAM です。
このインスタンス タイプ (c5.2xlarge) のハードウェア仕様は 8 CPU および 16 GB RAM です。
Jira 8.13 の場合、小規模なインスタンスの Apdex は、c5.4xlarge で 0.918 (2 ノード) に到達しました。この結果は、c5.9xlarge ノードの結果をわずかに上回っています。HA には少なくとも 3 つのノードが必要です。c5.4xlarge のハードウェア仕様は 16 CPU および 32 GB RAM です。Jira 8.5 の場合、c5.4xlarge は 6 ノードの場合に優れた Apdex スコアを示しました。これは引き続き優れた費用対効果と言えます。この Jira バージョンの場合、c5.9xlarge (3 ノード) を使用すると Apdex は同じになりますが、スループットはわずかに下回るほか、この設定はわずかに高額です。
結論として、コストに問題がない場合、c5.9xlarge (Jira 8.5) では 6 ノード、c5.4xlarge (Jira 8.13) では 2 ノード使用すると、最高のパフォーマンス結果が得られます。
ただし、費用対効果が懸念される場合、Jira 8.5 には 6 ノードの c5.4xlarge を検討することをおすすめします。Jira 8.13 の場合、3 ノードの c5.2xlarge になります。
これらのノードの詳細については、「Amazon EC2 C5 インスタンス」を参照してください。
テスト シリーズから、Jira 8.13 のアプリケーション ノードでは、c5.2xlarge 3 ノードの場合に Apdex が最高となり、2 つの c5.4xlarge ノードを使用すると、最も費用対効果の高いオプションとなることが判明しました。Jira 8.5 の場合、これらは 6 つの c5.9xlarge と 6 つの c5.4xlarge になります。この情報を使用して次のテスト段階に移行し、データベース ノードに最適な構成をテストしました。
ここでは、両方の Jira アプリケーション ノード構成に対して、データベース ノードの次の仮想マシン タイプのベンチマークを確認しました。
m4.xlarge
m4.2xlarge
m4.4xlarge
m4.10xlarge
m4.16xlarge
| Jira 8.13 – Apdex |
|---|
|

| Jira 8.5 – Apdex |
|---|
|

| Jira 8.13 – アクションの失敗がユーザーに確認される頻度 |
|---|
|

| Jira 8.5 – アクションの失敗がユーザーに確認される頻度 |
|---|
|

| Jira 8.13 – スループット |
|---|
|

| Jira 8.5 – スループット |
|---|
|

| Jira 8.13 – アクションのエラーの最大数 |
|---|
|

| Jira 8.5 – アクションのエラーの最大数 |
|---|
|

"Large" Jira インスタンスの推奨設定
アトラシアンでは "Large" テスト フェーズのベンチマークと構成を分析し、最も費用対効果が高く、フォールト トレラントである以下の推奨設定を導きました。
これらの推奨設定の背後にある詳細については、上記の Large テスト フェーズの「アプリケーション ノード」と「データベース ノード」のセクションを参照してください。
ベスト パフォーマンスと信頼性のための推奨設定
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.9xlarge x 3 | m4.2xlarge | 0.859 | 4.99 |
| Jira 8.5 | c4.8xlarge x 3 | m4.4xlarge | 0.742 | 7.16 |
興味深いことに、c5.18xlarge インスタンス (72 CPU および 144 GB RAM) では、パフォーマンスは c4.8xlarge (Jira 8.5) および c5.9xlarge (Jira 8.13) よりも低下しました。この動作は、テスト全体を通じて一貫していました。Large プロファイルのお客様には、最高のパフォーマンスとフォールト トレランスを保証する c5.9xlarge 3 ノード (Jira 8.13) および c4.8xlarge 3 ノード (8.5)、をおすすめします。また、目的のスループットを実現する最小データベース要件として、m4.2xlarge (Jira 8.13 の場合) または m4.4xlarge (Jira 8.5 の場合) をおすすめします。
費用対効果および最適なパフォーマンスのための推奨設定
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.841 | 1.22 |
| Jira 8.5 | c4.8xlarge x 2 | m4.xlarge | 0.742 | 4.97 |
Jira 8.5 の場合、テスト結果は、少ないノード数で強力なハードウェアを使用すると、最適なパフォーマンスを実現できることを示しています。使用したインスタンス タイプ (c4.8xlarge) の仕様は 36 CPU、60 GB RAM でした。このタイプのノードを 2 つまたは 3 つ使用することで、妥当なコストで優れたパフォーマンスを確保できます。また、目的のスループットを実現する最小データベース要件として、m4.xlarge をおすすめします。
Jira 8.13の場合、テスト結果により、性能の少し低いハードウェアを使用すると、低コストで最適なパフォーマンスを実現できることが示されています。使用したインスタンス タイプ (c5.2xlarge) の仕様は 8 CPU、16 GB RAM でした。このタイプのノードを 3 つまたは 4 つ使用することで、妥当なコストで優れたパフォーマンスを確保できます。また、目的のスループットを実現する最小データベース要件として、m4.xlarge をおすすめします。
"XLarge" Jira インスタンスの推奨設定
アトラシアンでは "XLarge" テスト フェーズのベンチマークと構成を分析し、最も費用対効果が高く、フォールト トレラントである以下の推奨設定を導きました。
これらの推奨設定の背後にある詳細については、上記の XLarge テスト フェーズの「アプリケーション ノード」と「データベース ノード」のセクションを参照してください。
ベスト パフォーマンスと信頼性のための推奨設定
テスト結果により、優れた性能のハードウェアを使用すると、最適なパフォーマンスを実現できることが示されています。使用したインスタンス タイプ (c5.9xlarge) の仕様は 36 CPU、72 GB RAM でした。そのため、コストよりもパフォーマンスを優先する XLarge プロファイルのお客様には、Jira 用 c5.9xlarge 6 ノード8.5をおすすめします。このノード数を使用することで、フォールト トレランスと顕著なスループットも保証できます。また、目的のスループットを実現する最小データベース要件として、m4.4xlarge をおすすめします。
Jira 8.13 の場合、c5.4xlarge 2 ノードをおすすめします。このノード数を使用することで、フォールト トレランスと顕著なスループットも保証できます。また、目的のスループットを実現する最小データベース要件として、4.4xlarge をおすすめします。使用したインスタンス タイプ (c5.4xlarge) の仕様は 16 CPU、32 GB RAM でした。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.4xlarge x 2 | m4.4xlarge | 0.918 | 2.16 |
| Jira 8.5 | c5.9xlarge x 6 | m4.4xlarge | 0.803 | 11.51 |
費用対効果および最適なパフォーマンスのための推奨設定
興味深いことに、Jira 8.13 では、c5.2xlarge インスタンス (8 CPU および 16 GB RAM) を 3 ノードで使用した場合、パフォーマンスは 2 ノードの c5.4xlarge の場合よりわずかに低下しましたが、Apdex は引き続き 0.70 を超えました。この動作は、テスト全体を通じて一貫していました。ただし、Jira 8.13 XLarge プロファイルのお客様で費用対効果を重視する場合には、c5.2xlarge 3 または 4 ノード (より優れたフォールト トレランスを実現する場合は 4 ノード) をおすすめします。
Jira 8.5 の場合、c5.4xlarge は 6 ノードで優れたパフォーマンスを発揮します。このため、Jira 8.5 の場合は、c5.4xlarge 6 または 7 ノード (より優れたフォールト トレランスを希望する場合は 7 ノード) をおすすめします。なお、c5.9xlarge は 0.70 以上の Apdex (3 ノードの場合) を示し、このソリューションは c5.4xlarge (6 ノード) よりもわずかに高額です。
目的のスループットを実現する最小データベース要件として、Jira 8.13 および Jira 8.5 の場合は m4.xlarge をおすすめします。
Application nodes | データベース ノード | Apdex | 1 時間あたりのコスト1 | |
|---|---|---|---|---|
| Jira 8.13 | c5.2xlarge x 3 | m4.xlarge | 0.905 | 1.22 |
| Jira 8.5 | c5.4xlarge x 6 | m4.xlarge | 0.720 | 4.96 |
1 時間あたりのコスト
1 アトラシアンの推奨設定では、各構成の相対的な価格を比較できるよう、1 時間当たりのコストを見積もっています。アプリケーション ロード バランサなどのすべてのサブコンポーネントを含めた、Jira インスタンス全体のコストを計算しています。
これらの金額は USD で、リージョンはオハイオであり、2020 年 10 月時点の値です。
アトラシアンで使用するインスタンス
以下の表は、お客様で参照可能な弊社の本番インスタンスを示しています。
ユースケース | ノード | AWS アプリケーション ノード | 説明 |
|---|---|---|---|
Jira のスケール テスト | 2 | この環境を使用し、異なる Jira バージョンで "Large" サイズ プロファイルに匹敵する負荷をテストします。「Jira の拡張」の各リンクには、特定のユーザー アクションに対する Jira バージョンでの応答時間、および以前のバージョンとの比較が表示されます。 | |
Public-facing Jira Service Desk instance (getsupport.atlassian.com) | 3 | 「Jira Data Center のサンプル デプロイメントと監視戦略」で、アトラシアンが管理している実際の 2 つの Jira Data Center インスタンスについて説明しています。いずれも、公開されたアトラシアン サービスをホストする Large サイズのインスタンスです。どちらも同一のアーキテクチャを備えていますが、異なるアプリケーション ノードとデータベース ノードを使用します。 | |
公開 Jira Software インスタンス | 3 |
Atlassian が提供するサービス
時間の経過とともに、新しいテスト、知見、または Jira Data Center の改善によって、推奨設定が変更されることがあります。そのような場合はこのページをご参照ください。Data Center インスタンスに最適な構成を選択する際にさらなる支援が必要な場合は、アトラシアンのテクニカル アカウント マネージャーにお問い合わせください。
アトラシアンのプレミア サポート チームは、お客様のアプリケーションとログを細かく分析してヘルス チェックを行い、お客様のインフラストラクチャ構成がお使いの Data Center アプリケーションに最適であることを確認します。ヘルス チェックでパフォーマンスのギャップが判明した場合、プレミア サポートは実施可能な変更を提案いたします。