High availability for Bitbucket
This page describes how to set up a single Bitbucket Data Center instance in a highly available configuration.
For production installs, we highly recommend that you first read Use Bitbucket in the enterprise.
For Active/Active high availability with Bitbucket Data Center, see Bitbucket Data Center resources instead.
For guidance on using Bitbucket Data Center as part of your disaster recovery strategy, see the Disaster recovery guide for Bitbucket Data Center.
If Bitbucket Data Center is a critical part of your development workflow, maximizing application availability becomes an important consideration. There are many possible configurations for setting up a HA environment for Bitbucket Data Center, depending on the infrastructure components and software (SAN, etc.) you have at your disposal. This guide provides a high-level overview and the background information you need to be able to set up a single Bitbucket Data Center instance in a highly available configuration.
Note that Atlassian's Bitbucket Data Center resources product uses a cluster of Bitbucket Data Center nodes to provide Active/Active failover. It is the deployment option of choice for larger enterprises that require high availability and performance at scale, and is fully supported by Atlassian. Read about Failover for Bitbucket Data Center.
高可用性
High availability describes a set of practices aimed at delivering a specific level of "availability" by eliminating and/or mitigating failure through redundancy. Failure can result from unscheduled down-time due to network errors, hardware failures or application failures, but can also result from failed application upgrades. Setting up a highly available system involves:
Proactive Concerns
- Change management (including staging and production instances for change implementation)
- Redundancy of network, application, storage and databases
- Monitoring system(s) for both the network and applications
Reactive Concerns
- Technical failover mechanisms, either automatic or scripted semi-automatic with manual switchover
- Standard Operating Procedure for guided actions during crisis situations
This guide assumes that processes such as change management are already covered and will focus on redundancy / replication and failover procedures. When it comes to setting up your infrastructure to quickly recover from system or application failure, you have different options. These options vary in the level of uptime they can provide. In general, as the required uptime increases, the complexity of the infrastructure and the knowledge required to administer the environment increases as well (and by extension the cost goes up as well).
Understanding the availability requirements for Bitbucket Data Center
Central version control systems such as Subversion, CVS, ClearCase and many others require the central server to be available for any operation that involves the version control system. Committing code, fetching the latest changes from the repository, switching branches or retrieving a diff all require access to the central version control system. If that server goes down, developers are severely limited in what they can do. They can continue coding until they're ready to commit, but then they're blocked.
Git is a distributed version control system and developers have a full clone of the repository on their machines. As a result, most operations that involve the version control system don't require access to the central repository. When Bitbucket Data Center is unavailable developers are not blocked to the same extent as with a central version control system.
As a result, the availability requirements for Bitbucket Data Center may be less strict than the requirements for say Subversion.
Consequences of Bitbucket Data Center unavailability | |
|---|---|
Developer:
| Developer:
Build server:
Continuous Deployment:
|
Failover options
High availability and recovery solutions can be categorized as follows:
Failover option | Recovery time | 説明 | Possible with Bitbucket Data Center |
|---|---|---|---|
| Automatic correction / restart | 2-10 min (application failure) hours-days (system failure) |
| |
| Cold standby | 2-10 min |
| |
| Warm standby | 0-30 sec |
| |
| Active/Active | < 5 sec |
|
Automatic correction
Before implementing failover solutions for your Bitbucket Data Center instance consider evaluating and leveraging automatic correction measures. These can be implemented through a monitoring service that watches your application and performs scripts to start, stop, kill or restart services.
- A Monitoring Service detects that the system has failed.
- A correction script attempts to gracefully shut down the failed system.
- If the system does not properly shut down after a defined period of time, the correction script kills the process.
- After it is confirmed that the process is not running anymore, it is started again.
- If this restart solved the failure, the mechanism ends.
- If the correction attempts are not or only partially successful a failover mechanism should be triggered, if one was implemented.
Cold standby
The cold standby (also called Active/Passive) configuration consists of two identical Bitbucket Data Center instances, where only one server is ever running at a time. The Bitbucket home directory on each of the servers is replicated from the active to the standby Bitbucket Data Center instance. When a system failure is detected, Bitbucket Data Center is restarted on the active server. If the system failure persists, a failover mechanism is started that shuts down Bitbucket Data Center on the active server and starts Bitbucket Data Center on the standby server, which is promoted to 'active'. At this time, all requests should be routed to the newly active server.
For each component in the chain of high availability measures, there are various implementation alternatives. Although Atlassian does not recommend any particular technology or product, this guide gives options for each step.
System setup
This section describes one possible configuration for how to set up a single instance of Bitbucket Data Center for high availability.
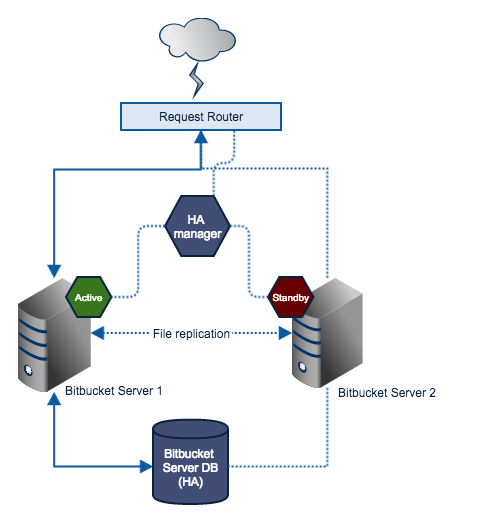
コンポーネント
Request Router
Forwards traffic from users to the active Bitbucket Data Center instance.
High Availability Manager
- Tracks the health of the application servers and decides when to fail over to a standby server and designate it as active.
- Manages failover mechanisms and sends notifications on system failure.
Bitbucket Data Center instance
- Each server hosts an identical Bitbucket Data Center installation (identical versions).
- Only one server is ever running a Bitbucket Data Center instance at any one time (know as the active server). All others are considered as standbys.
- Resides on a replicated or shared file system visible to all application servers.
- Must never be modified when the server is in standby mode.
Bitbucket Data Center database
The production database, which should be highly available. How this is achieved is not explored in this document. See the following database vendor-specific information on the HA options available to you:
- Postgres
http://www.postgresql.org/docs/9.2/static/high-availability.htm - MySQL
http://dev.mysql.com/doc/refman/5.5/en/ha-overview.html - Oracle
http://www.oracle.com/technetwork/database/features/availability/index.html - SQLServer
http://technet.microsoft.com/en-us/library/ms190202.aspx
ライセンス
Developer licenses can be used for non-production installations of Bitbucket Data Center deployed on a cold stand-by server. For more information see developer licenses.