Confluence Data Center でのクラスタ化
Confluence Data Center では複数の Confluence ノードのクラスタを実行して、高可用性、拡張のためのキャパシティ、および大規模環境でのパフォーマンスを実現できます。
このガイドでは、クラスタ化のメリットについて説明し、クラスタ化された環境で Confluence を実行するために必要なインフラストラクチャやハードウェア要件などの概要を提供します。
準備はよろしいですか? 「Confluence Data Center クラスタのセットアップ」をご確認ください。
On this page
クラスタ化は私の組織に適していますか?
クラスタリングは、連続アップタイム、すぐに利用できる拡張性、および高負荷下でのパフォーマンスを必要とする、大規模およびミッションクリティカルな Data Center デプロイメントを使用しているエンタープライズ向けに設計されています。
Confluence をクラスタで実行すると、次のようなメリットがあります。
- 高可用性とフェイルオーバー: クラスタのいずれかのノードがダウンした場合、他のノードが負荷を引き受け、ユーザーは中断されることなく Confluence にアクセスできます。
- 大規模環境でのパフォーマンス - クラスタにノードを追加すると、許容される同時ユーザー接続数が増え、ユーザーのアクティビティが増えた場合の応答時間が改善されます。
- 即時に拡張可能: ダウンタイムや追加のライセンス料金なしでクラスタに新しいノードを追加できます。インデックスとアプリは自動的に同期されます。
- ディザスタ リカバリ: オフサイトでのディザスタ リカバリ システムをデプロイして、完全なシステム停止の場合にもビジネス継続性を実現します。共有アプリケーション インデックスにより、素早く元の状態に戻って製品を実行することができます。
- ローリング アップグレード: ダウンタイムなしの機能リリースの最新のバグ修正更新へのアップグレード。Confluence への中断のないアクセスをユーザーに提供しつつ、重大なバグ修正とセキュリティ更新をサイトに適用します。
クラスタ化は Data Center でのみ利用できます。「Data Center へのアップグレード」の詳細をご覧ください。
クラスタリング アーキテクチャ
基本
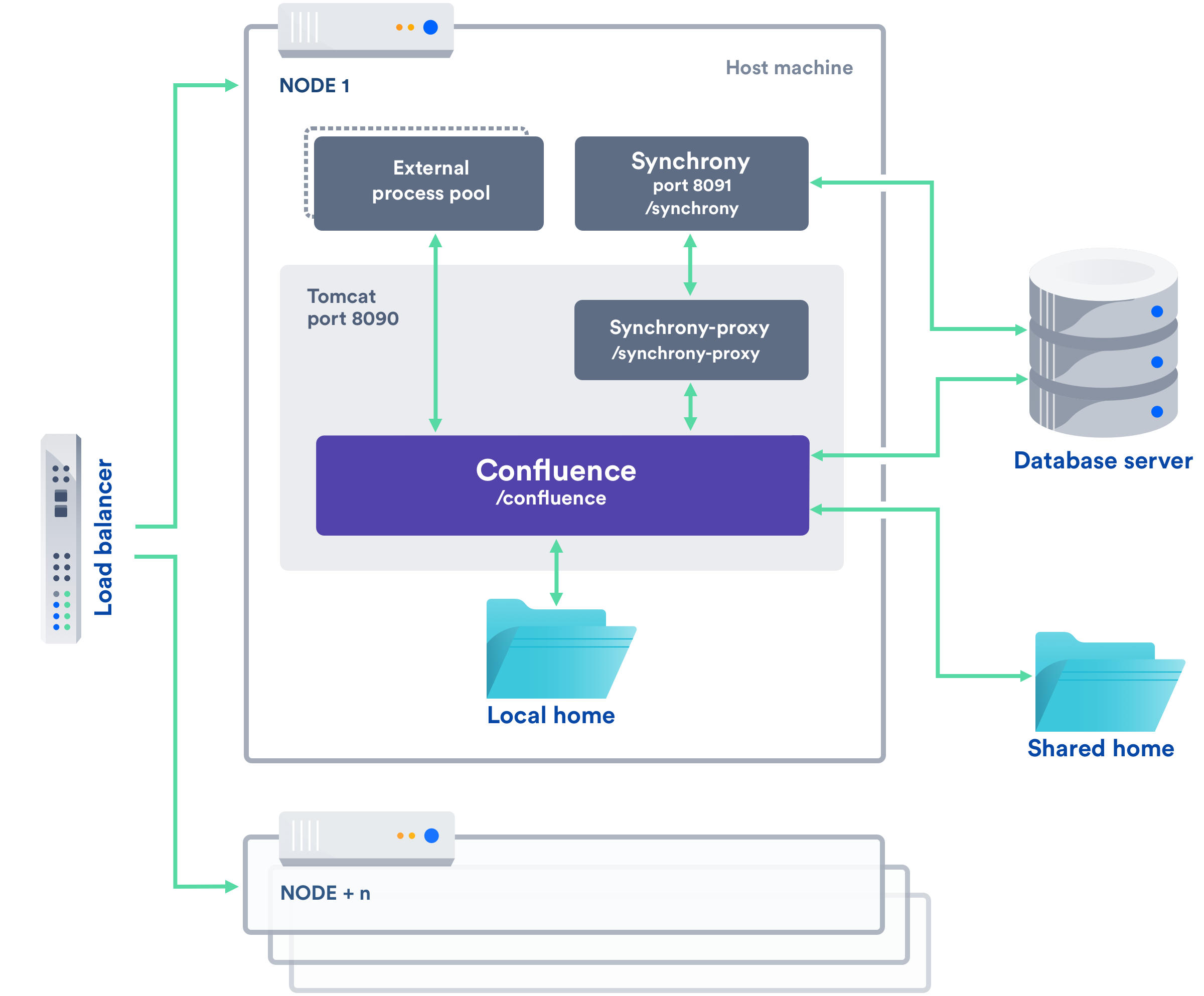
Confluence Data Center クラスタは以下で構成されます。
- Confluence Data Center を実行する複数の同一のアプリケーション ノード。
- トラフィックをすべてのアプリケーション ノードに分散するロード バランサ。
- 添付ファイルやその他の共有ファイルを保存する共有ファイル システム。
- すべてのノードが読み取るおよび書き込むデータベース
すべてのアプリケーション ノードがアクティブ状態にあり、リクエストを処理します。ユーザーは、セッションのタイム アウト、ログアウト、またはクラスタからノードが削除されるまで、すべてのリクエストで同じ Confluence ノードにアクセスします。
次の画像は、一般的な構成を示しています。
ライセンス
Data Center ライセンスは、ノードの数ではなくクラスタのユーザー数に基づきます。つまり、新しいサーバーや CPU に追加のライセンス料金は発生せず、いつでも環境を拡張できます。
管理コンソールのライセンス詳細ページで利用可能なライセンス数を監視できます。
このプロセスを自動化する(たとえば、割り当て限界に近づいた場合にアラートを送信する)場合は、REST API を使用することができます。
利用可能な機能やインフラストラクチャは、Confluence ライセンスによって決定されます。Server ライセンスと Data Center ライセンスの違いの完全な一覧については、「Confluence Server と Data Center の機能の比較」を参照してください。
ホーム ディレクトリ
Confluence をクラスタで実行するには、追加のホーム ディレクトリである "共有ホーム" が必要です。
各 Confluence ノードには、ログ、キャッシュ、Lucene インデックス、および設定ファイルを含むローカル ホームがあります。他のすべてのデータは共有ホームに格納され、クラスタ内の各 Confluence ノードからアクセスすることができます。Marketplace アプリについては、アプリのニーズに応じて、データをローカル ホームに格納するか共有ホームに格納するかを選択することができます。
ローカル ホームと共有ホームの内容の概要は次のとおりです。
| ローカル ホーム | 共有ホーム |
|---|---|
|
|
現在添付ファイルをデータベースに保存している場合、そのまま保存し続けることができますが、新しいインストールでは利用できません。
キャッシング
クラスター化されると、Confluence はローカル キャッシュ、分散型キャッシュ、Hazelcast で管理されるハイブリッド キャッシュの組み合わせを使用します。これにより、完全に複製されたキャッシュを使用するよりも水平方向のスケーラビリティが拡張され、必要なストレージと処理能力を削減できます。詳細は、「キャッシュ統計」をご覧ください。
このキャッシュ ソリューションのため、遅延を最小化するには、ノードが物理的に同じ場所またはリージョン (AWS や Azure の場合) にある必要があります。
インデックス
個々の Confluence アプリケーション ノードは、インデックスの完全なコピーを自身で保存します。ジャーナル サービスが各インデックスの同期状態を保持します。
初めてクラスタをセットアップする場合、インデックスを含むローカル ホーム ディレクトリを1つ目のノードから新しい各ノードにコピーします。
既存のクラスタに新しいConfluenceのノードを追加するときは、新しいノードに既存のノードのローカルホームディレクトリをコピーします。新しいノードを起動すると、Confluenceは、インデックスが最新のものかチェックします。そうでない場合、共有ホームディレクトリから、あるいはを実行しているノード(マッチングビルド番号付き)からインデックスの回復スナップショットを要求し、起動プロセスを続行する前にインデックスディレクトリに展開します。スナップショットを生成することができないか、時間内に新しいノードによって受信されない場合は、既存のインデックスファイルが削除され、Confluenceは完全な再インデックスを実行します。
Confluence ノードが短時間(数時間)クラスタから切断された場合、クラスタに再接続した際に、ジャーナル サービスを使用して、最新のインデックスのコピーを取得することができます。ノードが長時間(数日)ダウンした場合、Lucene インデックスは失効してしまい、既存のノードからノードの起動プロセスの一部として、スナップショットの復旧をリクエストします。
インデックスに問題がある可能性がある場合、1 つのノード上でインデックスを再構築すると、Confluence によって新しいインデックス ファイルがクラスタの各ノードに自動的に反映されます。
再インデックスとインデックス復元の詳細については、コンテンツ インデックス管理を参照してください。
クラスタの安全なメカニズム
ClusterSafetyJob は、Confluence でタスクを30秒ごとに実行するようにスケジュールされています。クラスタでは、このジョブは1つの Confluence ノードでのみ実行されます。スケジュールされたタスクは安全番号で動作します。安全番号はクラスタ全体で使用されるデータベースと分散キャッシュの両方に格納されているランダムに生成された番号です。ClusterSafetyJob はデータベースの値とキャッシュの値を比較し、値が異なる場合は、Confluence はノードをシャット ダウンします。これはクラスタ スプリット ブレインと呼ばれています。この安全性のメカニズムは、クラスタ ノードが矛盾した状態にならないようにするために使用されます。
クラスタ スプリット ブレインが発生した場合、クラスタ化されているノード間の適切なネットワーク接続を確認する必要があります。ほとんどのマルチキャスト トラフィックはブロックされているか、正しくルーティングされません。
稼働時間とデータの整合性のバランス
クラスタ セーフティなスケジュールされたジョブが実行される頻度と Hazelcast ハートビートの期間を変更する(クラスタからノードが削除されるまでのノードの通信不能期間を制御)ことで、クラスタの稼働時間とデータ整合性のバランスを微調整することができます。ほとんどの場合、デフォルト値が適切ですが、場合によっては、たとえば、稼働時間の増加のためにデータ整合性をトレード オフするように決定することができます。
クラスタ ロックとイベント ハンドリング
アクションが1つのノードでだけ実行される場合、たとえば、スケジュールされたジョブまたは日次のメール通知の送信の場合、Confluence はクラスタ ロックを使用して、アクションが1つのノードでだけ実行されることを保証します。
同様に、一部のアクションは 1 つのノードで実行してから、他のノードに発行する必要があります。イベント ハンドリングは、現在のトランザクションがコミットおよび完了されたときにのみ、Confluence がクラスタ イベントを発行することを保証します。これにより、イベントが受信および処理されたときに、データベースに格納された任意のデータをクラスタ内の他のインスタンスから利用できるようになります。イベント ブロードキャストはアプリの有効化や無効化などの特定のイベントに対してのみ実行されます。
クラスタ ノード検出
クラスタ ノードを設定する場合、各クラスタノードの IP アドレスかマルチキャスト アドレスのいずれかを指定します。
マルチキャストを使用する場合:
Confluence はマルチキャスト ネットワーク アドレスにジョイン リクエストをブロードキャストします。Confluence はマルチキャスト アドレスの UDP ポートを開くことができる必要があり、それができない場合、他のクラスタノードを検出できません。ノードが検出されたら、それぞれキャッシュ更新のために接続できるユニキャスト(通常の) IP アドレスとポートで応答します。Confluence は他のノードとの通常の通信のために、UDP ポートを開くことができる必要があります。
マルチキャスト アドレスはクラスタ名から自動生成されるか、最初のノードのセットアップ時に自分で入力することができます。
インフラストラクチャとハードウェアの要件
ハードウェアやインフラの選択はあなた次第です。以下はハードウェアおよびインフラストラクチャ要件を計画するときに考える必要がある領域です。
AWS EKS デプロイ オプション
Confluence Data Center を AWS で実行する予定の場合は、管理対象の Kubernetes クラスター サービスで Helm チャートを使用してデプロイできます。「Confluence Data Center を AWS で実行する」を参照してください。
AWSクイック・スタート・デプロイメントオプション
デプロイ方法としての AWS クイック スタート テンプレートはアトラシアンではサポートされなくなりました。テンプレートは今後も利用できますが、保守や更新は行われません。
Confluence Data Center を AWS で実行する予定の場合は、クイック スタートを利用して、新規または既存の仮想プライベート クラウド (VPC) に Confluence Data Center をデプロイできます。Confluence ノードと Synchrony ノード、Amazon RDS PostgreSQL データベース、アプリケーション ロード バランサーの設定をすべて数分で完了し、使用できるようになります。AWS を初めて使用する場合は、ステップバイステップのクイック スタート ガイドがプロセス全体で役立ちます。
Confluence は、Amazon Elastic File System (EFS) をサポートする地域でのみデプロイできます。詳細は、「AWS で Confluence Data Center を実行する」を参照してください。
クイック スタートを使用して Confluence をデプロイしている場合、EC2 インスタンスにインストールされている Java Runtime Engine (JRE) (/usr/lib/jvm/jre/) ではなく、Confluence にバンドルされている JRE (/opt/atlassian/confluence/jre/) が使用されている点にご注意ください。
サーバー要件
Confluence と同じサーバーで他のアプリケーション (コア オペレーティング システム サービスを除く) を実行しないでください。アトラシアン ソフトウェアの専用サーバーでの Confluence、Jira、および Bamboo の実行は、小規模なインストールではうまく動作しますが、大規模に実行する場合はうまくいきません。
Confluence Data Center は仮想マシンで正常に実行できます。マルチキャストを使用する予定がある場合、Amazon Web Service (AWS) はマルチキャスト トラフィックをサポートしていないため、AWS 環境では Confluence Data Center を実行できません。
クラスタノード
各ノードはまったく同じである必要はありませんが、一貫性のあるパフォーマンスのために、可能な限り同質になるようにします。すべてのクラスタ ノードは以下を満たす必要があります。
- 同じデータ センターまたはリージョン内にあること (AWS と Azure の場合)
- 各 Confluence ノードで同じ Confluence バージョンを実行します ( ローリング アップグレード中を除く)
- 各 Synchrony ノードで同じ Synchrony バージョンを実行します (管理された Synchrony を使用していない場合)
- 同じ OS、Java、およびアプリケーション サーバー バージョン
- 同じメモリ設定(JVM と物理メモリの両方)(推奨)
- 同じタイムゾーンで設定されている(および現在の同期された時間を維持する)。これを保証するには ntpd または同様なサービスを使用することをお勧めします。
![]() クラスタでさまざまな問題が発生する可能性があるため、ノードのクロックが逸脱していないことを確認する必要があります。
クラスタでさまざまな問題が発生する可能性があるため、ノードのクロックが逸脱していないことを確認する必要があります。
いくつのノードが必要ですか?
Data Center ライセンスでは、クラスタのノード数は制限されません。ノードの適切な数は、Confluence サイトのサイズや特徴、およびノードのサイズによって異なります。インスタンスのサイズの検討については、「Confluence Data Center の負荷プロファイル」を参照してください。小さく開始し、必要に応じて拡張することをおすすめします。
メモリ要件
Confluence ノード
各 Confluence ノードの RAM は、最小 10 GB にすることをお勧めします。同時接続ユーザー数が増えると、大量の RAM が消費されます。
ここでは、メモリを異なるサイズのマシンに割り当てる方法の例をいくつか紹介します。
| RAM | 各 Confluence ノードの内訳 |
|---|---|
| 10 GB |
|
| 16 GB |
|
Confluence アプリケーションの最大ヒープ (-Xmx) は、setenv.sh または setenv.bat ファイルで設定されます。Data Center の場合、既定値を増やす必要があります。最小ヒープ (Xms) と最大 (Xmx) ヒープを同じ値にすることをお勧めします。
外部プロセス プールは、個々の Confluence ノードの影響を最小化するためにメモリ集約タスクを外部化するのに使用されます。プロセスは Confluence で管理されます。各プロセス (サンドボックス) の最大ヒープ (-Xmx) とサンドボックスの数はシステム プロパティを使用して設定されます。多くの場合、既定の設定が適切であり、変更は不要です。
スタンドアロンの Synchrony クラスタ ノード
Synchrony は共同編集に必要です。Synchrony は既定では Confluence によって管理されていますが、独自のクラスタで Synchrony を実行するようにすることもできます。利用可能な選択肢の詳細については、「Confluence および Synchrony で利用可能な設定」を参照してください。
独自の Synchrony クラスタを実行する場合、スタンドアロン Synchrony に対して 2 GB のメモリを割り当てることをお勧めします。ここでは、専用の Synchrony ノードへのメモリ割り当ての例を示します。
| 物理 RAM | 各 Synchrony ノードの内訳 |
|---|---|
4 GB |
|
データベース
クラスタ データベースについてもっとも重要な要件は、そのノード数をサポートするのに十分なコネクションが利用可能であることです。
例:
- 各 Confluence ノードの最大プールサイズは20コネクションです。
- 各 Synchrony ノードの最大プール サイズは15コネクションです(デフォルト)。
- 3 Confluence ノードおよび 3 Synchrony ノードの実行を計画しています。
データベース サーバーは Confluence データベースに対して最低105コネクションを許可する必要があります。実際には、デバックや管理目的で最大以上のコネクションが必要な場合があります。
目的のデータベースが現在「サポートされているプラットフォーム」に記載されていることも確認する必要があります。平均的なクラスタ ソリューションの負荷はスタンドアロン インストールよりも高くなるため、サポートされているデータベースを使用することが重要です。
また、サポートされているデータベース ドライバを使用する必要があります。サポートされていないドライバやカスタム JDBC ドライバ (または JNDI データソース コネクションで driverClassName を使用している場合)、共同編集でエラーが発生し、失敗します。サポートされているドライバの一覧については、「データベース JDBC ドライバ」を参照してください。
データベースの高可用性のための追加要件
Confluence Data Center をクラスタで実行した場合、アプリケーション サーバーは単一障害点になりません。これは、サポートされている次の構成を使用して、データベースでも実現できます。
Amazon RDS Multi-AZ: このデータベース セットアップは、別のアベイラビリティ ゾーンのスタンバイにレプリケートするプライマリ データベースを備えています。プライマリが停止した場合、スタンバイが代わりになります。
Amazon PostgreSQL 互換 Aurora: 1 つ以上のリーダー (別のアベイラビリティ ゾーンを推奨) にレプリケートするデータベース ノードを備えたクラスターです。ライターが停止した場合、Aurora はライターの 1 つをプロモートしてその代わりにします。既存の Confluence Data Center インスタンスで Amazon Aurora クラスターをセットアップする場合は、「Amazon Aurora を使用するために Confluence Data Center を構成する」をご参照ください。
AWSクイックスタート デプロイ オプションを使用するといずれかの方法で Confluence Data Center を最初からデプロイできます。既存の Confluence Data Center インスタンスで Amazon Aurora クラスタをセットアップする場合、「Amazon Aurora を使用するために Confluence Data Center を構成する」をご参照ください。
共有ホーム ディレクトリおよびストレージ要件
すべての Confluence クラスタは同じパスの共有ディレクトリへのアクセス権限を持っている必要があります。NFS および SMB/CIFS 共有が共有ディレクトリの場所としてサポートされています。このディレクトリには大量のデータ(添付ファイルやバックアップを含む)が格納されるため、十分なサイズにし、必要に応じて利用可能なディスク領域を増やす方法を計画する必要があります。
ログイン情報とセッションのタイムアウトを保存
[ログイン情報を記憶] オプションは、クラスタではデフォルトで強制設定されています。ユーザーのログイン ページに [ログイン情報を記憶] チェックボックスは表示されず、それぞれのセッションはノード間で共有されます。これを変更する必要がある、またはセッションのタイムアウトを変更する必要がある場合は、次のナレッジ ベース記事をご参照ください。
ロード バランサ
最も慣れ親しんだロード バランサを使用することをお勧めします。ロード バランサは「セッション アフィニティ」と WebSockets をサポートしている必要があります。これは Confluence と Synchrony の両方で必要です。AWS上で展開している場合は、アプリケーションのロードバランサ(ALB)を使用する必要があります。
ロードバランサを設定するときの推奨事項は、次のとおりです。
- キューは、ロード バランサでリクエストします。ノードへの要求の最大数が Tomcat で受け入れ可能な HTTP スレッドの合計数を超えていないことを確認することで、処理可能な数を超える要求がノードに送信されるのを避けることができます。
<install-directory>/conf/server.xmlで maxThreads を確認することができます。 - 非常に迅速に、すべてのノード間での問題を伝播できるため、他のノードに失敗した、べき等の要求を再生しないでください。
- 最小接続 の使用で、ラウンドロビンとしてではなく、 負荷バランスを行う方法はノードがクラスタに参加または削除された後に再結合する際に、よりよい負荷のバランスをとることができます。
多くのロード バランサでは、自動的にプールからバックエンドを削除するため、バックエンドの正常性を常に確認するための URL が必要です。これには安定しており高速であるが不要なリソースを消費しない程度に十分軽量な URL を使用することが重要です。以下の URL は Confluence のステータスを返し、この目的に使用することができます。
URL | 期待される内容 | 予想 HTTP ステータス |
|---|---|---|
| http://<confluenceurl>/status | {"state":"RUNNING"} | 200 OK |
ノードが長いGCの一時停止などの小さな問題を、生き残ることができるよう監視を設定するときは、いくつかの推奨事項は、以下のとおりです。
- ノードを削除する前に2回連続して失敗を待ちます。
- ノードがプールから削除される前に30秒と言うならば、ノードへの既存の接続が終了するのを許可します。
ネットワークアダプタ
サーバー間の通信に個別のネットワーク アダプタを使用します。クラスタ ノードはサーバー間通信用の個別の物理ネットワーク(個別の NIC など)を持っている必要があります。これはクラスタの実行を高速および信頼性を高くするのに最適な方法です。その他のデータ ストリーミングを多数持つネットワークを介してクラスタ ノードに接続する場合、パフォーマンスの問題が発生する可能性があります。
共同編集の追加要件
Confluence 6.0 以降の共同編集は、別のプロセスとして実行される Synchrony で実行されています。
Confluence Data Center ライセンスをお持ちの場合、Synchrony を実行するには 2 つのメソッドを使用できます。
- Confluence で管理 (推奨)
Confluence は同じノードで自動的に Synchrony プロセスを起動して管理します。手動による操作は不要です。 - スタンドアロンの Synchrony クラスタ (ユーザーによる管理)
ユーザーはスタンドアロンな Synchrony を必要なノード数で、独自のクラスタでデプロイおよび管理します。大規模なセットアップが必要です。ローリング アップグレードでは、Confluence クラスタとは別に Synchrony をアップグレードする必要があります。
シンプルなセットアップを実現してメンテナンスの労力を極力減らしたい場合、Synchrony を Confluence で管理することをおすすめします。完全な制御を実現したい場合や、エディタの高い可用性の確保が必須である場合、独自のクラスタで Synchrony を管理することが、組織に最適なソリューションである可能性があります。
アプリの互換性
Confluence クラスタにおける Marketplace アプリ (アドオン、プラグイン) のインストール プロセスは、Confluence のスタンドアロン インスタンスと同じです。アプリのインストールまたは更新の際に、クラスタを停止したり、ノードをダウンさせたりする必要はありません。
Atlassian Marketplace では、各アプリの Confluence Data Center との互換性が表示されます。
独自の Confluence プラグイン (アプリ) を開発している場合、アプリがクラスタ互換であるかどうかを確認する方法について、「アプリがクラスタで適切に動作するかを確認するにはどうしたらよいですか?」の開発者ドキュメントをご参照ください。
準備はよろしいですか?
クラスタを有効化および構成するためのステップ バイ ステップ ガイドについては、「Confluence Data Center クラスタのセットアップ」をご参照ください。