Amazon S3 オブジェクト ストレージを設定する
チームのデータ セットが大きい、または増加している場合は、スケーラビリティを高めるためにアバターを Amazon S3 オブジェクト ストレージに保存することを検討してください。このタイプのストレージは、従来のファイル システムとは異なり、データの保存用に適切に設計され、最適化されています。Amazon S3 とその仕組みの詳細をご確認ください。
次を保存するために、Amazon S3 をサポートしています。
- アバター (ユーザー アバター、課題タイプ アイコン、プロジェクト アイコン。Jira Service Management では、リクエスト タイプのアイコンも含まれます)。アバター データの保存用に S3 バケットを設定する方法をご確認ください。
添付ファイル (Amazon S3 に添付ファイルを保存するように Jira を構成する方法についてはこちらのリンク先を参照)
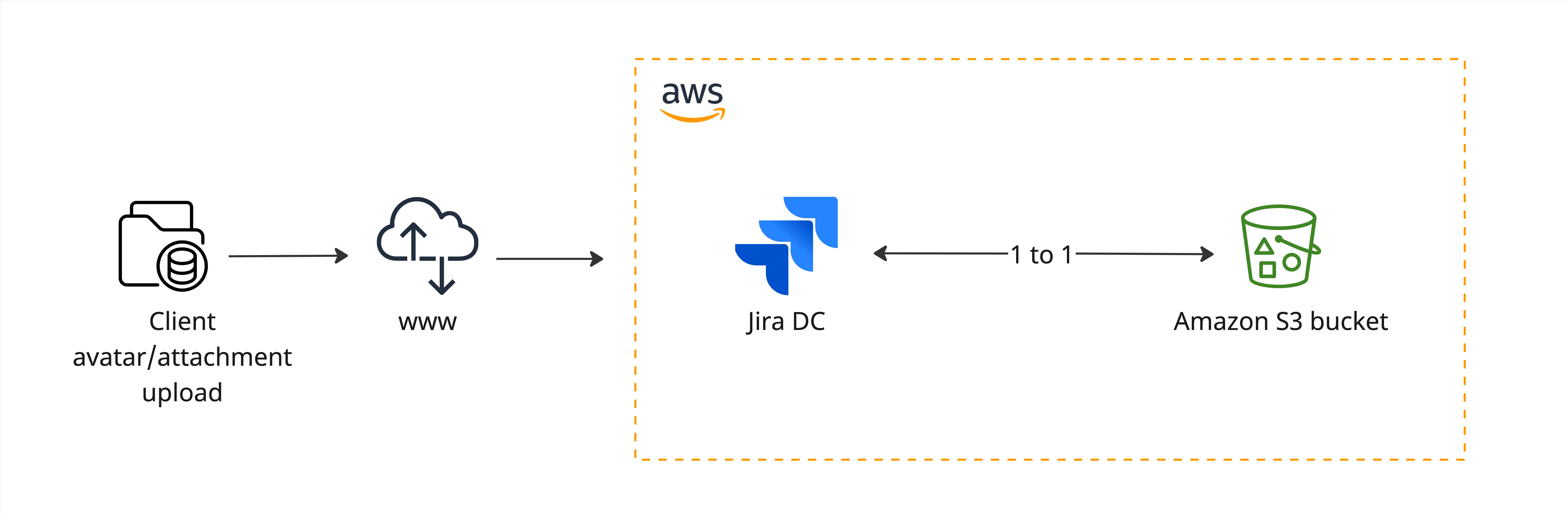
次の図は、オブジェクト ストレージの仕組みを示しています。Jira にアップロードされたアバターは、Amazon S3 バケットに保存され、そこから取得されます。
Amazon S3 が自社に最適かどうかを確認する
Amazon S3 を使用してアバターまたは添付ファイルを保存することを検討している場合は、次のいくつかのセクションを読んで、この保存方法が自社に適しているかどうかを確認してください。
Amazon S3 の要件
Amazon S3 オブジェクト ストレージを使用するための要件は次のとおりです。
Jira Data Center ライセンスを保有していること。
AWS で Jira をホストすることを計画しているか、すでに AWS で Jira を実行していること。この機能は、オンプレミス デプロイまたは AWS で Jira を実行していないお客様に対してはサポートされていません。AWS での Jira Data Center の管理の詳細をご確認ください。
アバターや添付ファイルを保存するための専用の Amazon S3 バケットを 1 つ以上用意すること。S3 バケットを作成して設定し、Jira に接続する方法をご確認ください。
Amazon S3 の制限事項
Amazon S3 をデータ ストレージ ソリューションとして検討する場合は、S3 オブジェクト ストレージをアバターと添付ファイルの保存に使用できる点に留意してください。ただし、プラグインやインデックス スナップショット データなど、他のタイプのデータについては、依然としてファイル システム ストレージを利用する必要があります。
Amazon S3 をデータ ストレージとして設定する
Amazon S3 のセットアップを開始する前に、設定の要件と現在の制限事項を必ずお読みください。
アバターと添付ファイルを S3 に保存する場合は、それぞれに別々のバケットを使用することも、両方に 1 つの共有バケットを使用することもできます。
1 つのバケットを複数の Jira インスタンス間で共有しないでください。データが失われる可能性があります。
1. Amazon S3 バケットを作成する
Amazon S3 の使用を開始するには、まずアバター データ用の S3 バケットを作成する必要があります。その方法については、Amazon から公式ガイドが公開されています。
バケットが正しく保護され、公開されていないことをご確認ください。
Amazon S3 バケットの設定とセキュリティ確保はユーザーの責任であり、アトラシアンは S3 のセットアップに関連する問題に対する直接的なサポートは提供していません。
バケット権限をセットアップする
S3 バケットに対する読み取り / 書き込みに必要な権限を Jira に付与してください。
s3:ListBuckets3:PutObjects3:GetObjects3:DeleteObject
バケットの認証方法によっては、これらの権限は EC2 のバケット ポリシーと IAM ロールを通じてバケット レベルで適用できます。詳細については、次のリソースをご確認ください。
下記は、(最小権限モデルに基づいて) 適切な権限を提供する Identity and Access Management (IAM) ポリシーの例です。
{
"Version": "2012-10-17",
"Id": "PolicyForS3Access",
"Statement": [
{
"Sid": "StatementForS3Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/JiraS3"
},
"Action": [
"s3:ListBucket",
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::jira-avatar-data/*",
"arn:aws:s3:::jira-avatar-data"
]
}
]
}Amazon S3 の機能との互換性
Jira では Amazon S3 のほとんどの機能がサポートされていますが、特定の機能の設定に対しては互換性がありません。次の表はそれらをまとめたものです。
| 機能 | 説明 |
|---|---|
| バケットのバージョニング | Jira はバージョニングが有効になっている S3 バケットにデータを保存できます。ただし、Jira データにはバージョニングを使用しないことを強くお勧めします。 Jira ではアバターまたは添付ファイルを更新する際にオブジェクト キーは再利用されません。そのため、同じバケットにオブジェクトの複数のバージョンを保持するメリットは最小限に抑制されます。バケット バージョニングを有効にすると、削除されたアバターも保持されるようになるため、GDPR などのプライバシー規制に対するコンプライアンス上の問題が生じる可能性があります。 |
| Amazon S3 Intelligent-Tiering | Jira では、Intelligent-Tiering ストレージ クラスへのアバターの保存がサポートされています。ただし、オプションのアーカイブ アクセス階層とディープ アーカイブ アクセス階層はサポートされていません。 |
Amazon S3 Glacier | Jira では、S3 Glacier ストレージ クラスを使用したアバターのアーカイブや復元はサポートされていません。 |
2. Amazon S3 バケットを認証する
Jira では、Amazon S3 との通信に Java 2.x 用 AWS SDK が使用されます。Java 2.x 用 AWS SDK の設定の詳細をご確認ください。
SDK を認証する際には、Jira 環境内の認証情報が次の順序で検索されます。
Java システムのプロパティ
環境変数
AWS セキュリティ トークン サービス (AWS STS) の Web ID トークン
共有認証情報と
configファイル(~/.aws/credentials)Amazon ECS コンテナーの認証情報
Amazon EC2 インスタンス プロファイルの認証情報
ご使用の環境に対する認証情報を設定する方法については、次の Amazon ガイドをご確認ください。
Amazon は、Amazon S3 アクセスを必要とするアプリや AWS サービスに IAM ロールを使用することを推奨しています。
バケット接続をテストする
AWS S3 CLI を使用して、バケットが適切にセットアップされていることを確認する必要があります。Amazon S3 API をご確認ください。
バケットが正常に認証され、正しい権限が設定されていることを確認するには、次の手順に従います。
テスト ファイルを作成します。
touch /tmp/test.txtファイルをターゲット バケットに書き込むことで、
S3:PutObject権限を確認します。aws s3api put-object --bucket <bucket_name> --key conn-test/test.txt --body /tmp/test.txtS3:ListBucket権限を確認します。aws s3api list-objects --bucket <bucket_name> --query 'Contents[].{Key: Key, Size: Size}'S3:GetObject権限を確認します。aws s3api get-object --bucket <bucket_name> --key conn-test/test.txt /tmp/test.txtS3: DeleteObject権限を確認します。aws s3api delete-object --bucket <bucket_name> --key conn-test/test.txt元のテスト ファイルを削除します。
rm /tmp/test.txt
3.推奨: 不完全なファイルのアップロードを取り消す
より信頼性の高い方法で複数の部分にわたるファイルのアップロードとダウンロードを非同期的に実行するために、Amazon S3 クライアントを CRT ベースの非同期バージョンに変更しました。
ただし、システムに障害が発生したり接続が切断されたりすると、アップロード プロセスが正常に完了せず、不完全なファイル チャンクが S3 に保存されることがあります。 不完全なファイル パーツが長期にわたって残ってしまう問題を解決するための、推奨されている解決策があります。
Amazon S3 バケットで AbortIncompleteMultipartUpload ライフサイクル ルールを有効にすることを AWS では推奨しています。
このルールでは、開始後指定された日数以内に完了しないマルチパート アップロードを中止するよう Amazon S3 に指示します。 設定した制限時間を超えると、Amazon S3 はアップロードを中止し、不完全なアップロード データを削除します。
詳細については、「バージョン対応バケットのライフサイクル設定」を参照してください。
Amazon S3 バケットを Jira に接続する
アバター データの保存用に Amazon S3 を設定したら、S3 バケットを Jira に接続する必要があります。これらのガイドの指示に従ってください。
Amazon S3 をトラブルシューティングする
Amazon S3 の設定後に問題が発生することもあります。ヘルプについては、次のトラブルシューティング ガイドをご確認ください。