Confluence のインデックス作成のトラブルシューティング ガイド
プラットフォームについて: Server および Data Center のみ。この記事は、Server および Data Center プラットフォームのアトラシアン製品にのみ適用されます。
サーバー*製品のサポートは 2024 年 2 月 15 日に終了しました。サーバー製品を利用している場合は、アトラシアンのサーバー製品のサポート終了のお知らせページにて移行オプションをご確認ください。
*Fisheye および Crucible は除く
Confluence Data Center および Server のインデックス機能は、Confluence 内の検索、ダッシュボード、一部のマクロ、ユーザー メンションなど、コンテンツについての情報や参照が必要な場所で利用されます。Confluence Data Center および Server のインデックス機能は Apache Lucene エンジン上で実行されており、次の要素で構成されます。
- ページ、ブログ投稿、コメントのテキストなどのコンテンツを含むコンテンツ インデックス
- a change index which contains data about each change, such as when a page was last edited.

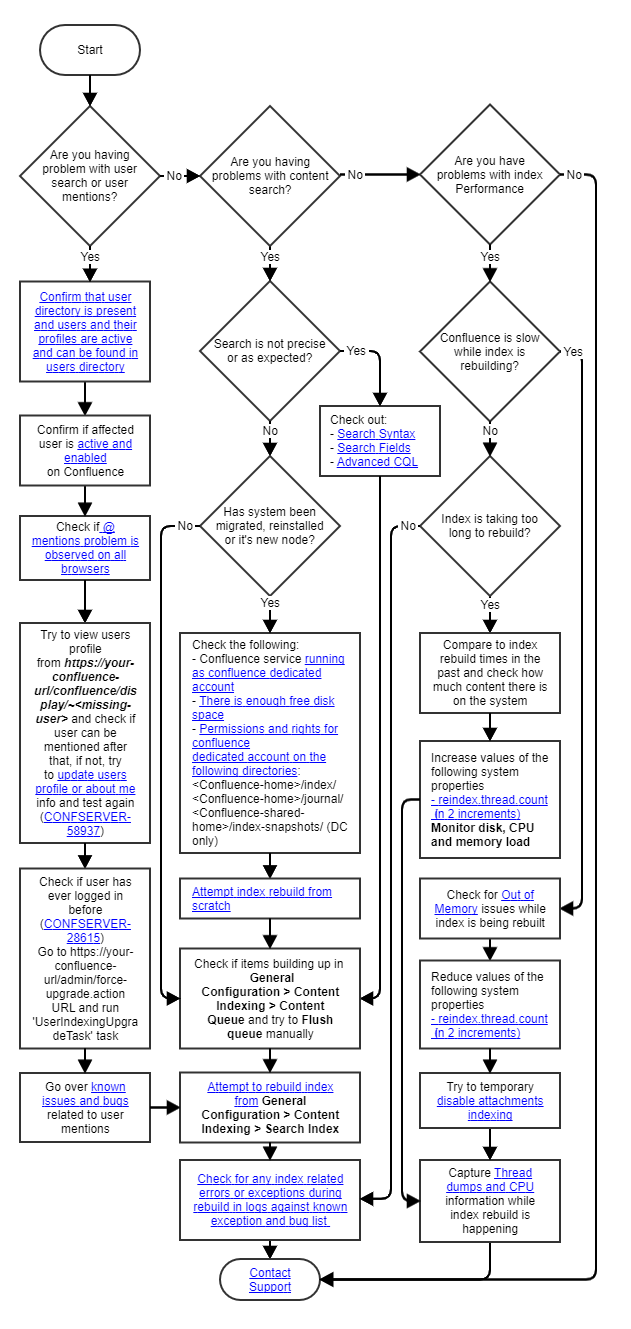
インデックスのトラブルシューティングのフローチャート
インデックスの問題に対応する際、問題の原因を判断するために次のフローチャートを利用できます。
用語
- 「インデックスの再構築」または「再インデックス」は、
 > [一般設定] > [コンテンツ インデックス] で既存のインデックス ファイルを利用してインデックスの再構築を行う操作を指します。
> [一般設定] > [コンテンツ インデックス] で既存のインデックス ファイルを利用してインデックスの再構築を行う操作を指します。 - 「インデックスのゼロからの再構築」は、ファイル システムから既存のインデックス ファイルを削除し、新しいファイルを利用して新しいインデックスを構築する操作を指します。
- 「インデックスの構築」または「インデックス作成」は、既存および新規コンテンツについてのインデックスの構築および維持を行う、Confluence の日次処理を指します。
ユーザーのメンション、プロフィール、インデックス
ユーザーが追加されたあとにインデックスされない、いくつかの既知の問題があります。これらのほとんどは「Confluence で特定のユーザーを @ メンションできない」ナレッジベースに記載されたいずれかの操作で対応できます。
Go to <Confluence URL>/confluence/display/~<不足しているユーザー> に移動してユーザー プロフィールを表示します
<Confluence URL>/admin/force-upgrade.action URL に移動して 'UserIndexingUpgradeTask' タスクを実行します
<Confluence URL>/confluence/admin/users/edituser.action?username=<不足しているユーザー> に移動し、自己紹介や他の任意の情報を更新します
- 新しいユーザーが単純に未インデックスである可能性があるため、 > [一般設定] > [コンテンツ インデックス] に移動し、そこからインデックスを再構築します
- 可能であればインデックスをゼロから再構築します。この方法でほとんどの問題を解決できます
ブラウザのローカル ストレージやキャッシュもユーザー メンションに影響します。これらはユーザーが頻繁にメンションする人を素早く表示できるよう保管しています。このため、別のブラウザでのテストも重要です。
便利なナレッジベース記事
コンテンツのインデックス、検索、マクロ
再構築、ロギング、内部
インデックスと Confluence 検索はコンテンツの権限に依存します。Confluence で特定のキーワードを検索すると、 Confluence のインデックス全体が検索され、コンテンツの権限に基づいて検索結果に制限が適用されます。このため、ancestor テーブルの問題はインデックスやインデックスの再構築に影響します。再構築の問題が発生している場合はこれらをご確認ください。
インデックスに関連するほとんどのエラーや警告は通常記録されますが、デバッグ ロギングを有効化し、検索、インデックスの構築、または再構築中の記録内容を確認すると、調査に非常に役立つ場合があります。
デバッグ ロギング
[管理] > [ロギングとプロファイル] に移動し、次のパッケージを追加して DEBUG に設定します。
com.atlassian.confluence.internal.index.AbstractBatchIndexer
com.atlassian.confluence.search.lucene
com.atlassian.bonnie.search.extractorRefer to Enabling Debug classes for Indexing Troubleshooting KB for details
Confluence 7.11 以降では、インデックスに関連するログ エントリやデバッグ ログは専用の atlassian-confluence-index.log ファイルに格納されます。
Confluence 7.11 未満では、ログ エントリは atlassian-confluence.log に格納されます。
インデックス ジョブと DB
インデックス対象のすべての新規および更新コンテンツはインデックス キューに追加され、これは [管理] > [コンテンツ インデックス] > [キュー コンテンツ] で確認できます。
これらのリクエストの処理のために Flush Edge Index Queue ジョブが 30 秒ごとに実行されているため、確認時点ではエントリが処理済みで、キュー コンテンツの一覧が空に見えることがあります。
インデックス対象のすべてのレコードは JOURNALENTRY DB テーブル内にも格納されており、各 Confluence ノードまたはサーバー インスタンスでは最後に処理されたエントリが <Confluence ホーム>/journal/main_index ファイルに保管されています。JOURNALENTRY DB テーブル内の最後のレコードを確認し、それらを <Confluence ホーム>/journal/main_index ファイルと比較することで、処理済みのコンテンツ インデックス ジョブを判断できます。
Flush Edge Index Queue ジョブのほかに、Clean Journal Entries ジョブが日次で実行されます。これは JOURNALENTRY DB テーブルで 2 日よりも古いエントリをクリーンアップします。このため、特定のノードまたはサーバー インスタンスで数日間適切に実行されなかったジョブがある場合、main_index ファイルに記録されている最後のインデックス対象エントリが JOURNALENTRY DB に存在しなくなっている可能性があります。これに該当する場合はインデックスの再構築が必要です。
インデックスの再構築タスクでは、 "Indexer: <n>" という名前のスレッドが最大 6 つ起動されます。このタスクの実行中に発生したすべてのエラーがこのスレッドのいずれかによって記録されます。
「ERROR java.io.IOException: No space left on device でインデクサーが停止する」ナレッジベースの例です。
ERROR [Indexer: 1] [internal.index.lucene.LuceneBatchIndexer] doIndex Exception indexing document with id: 12345678
│java.io.IOException: No space left on device インデックスの構築は Flush Edge Index Queue ジョブで実行されますが、これは Confluence のジョブ スケジューラーで処理されます。このため、これらのジョブの実行中に発生したすべての関連エラーや警告は基本的に "scheduler_Worker-<n>" スレッドで記録されます。同じナレッジベース内の次の例にあるように、メッセージを確認して警告/エラーの性質を判断する必要があります。
ERROR [scheduler_Worker-10] [org.quartz.core.ErrorLogger] schedulerError Job (DEFAULT.IndexQueueFlusher threw an exception.
org.quartz.SchedulerException: Job threw an unhandled exception. [See nested exception: com.atlassian.bonnie.LuceneException: com.atlassian.confluence.api.service.exceptions.ServiceException: Failed to process entries]
WARN [scheduler_Worker-10] [search.lucene.tasks.AddDocumentIndexTask] perform Error getting document from searchable
java.io.IOException: No space left on device
WARN [scheduler_Worker-1] [search.lucene.tasks.AddDocumentIndexTask] perform Error getting document from searchable
java.io.FileNotFoundException: /opt/confluence/confluence-home/index/_z8ey.fdx (No space left on device) インデックスの確認
In some rare situations you might need to check out what is being stored in Lucene index itself, for example, as part of debugging to verify that certain piece of content actually got indexed. You can refer to this guide on ways to do it. ![]() Index issues or corruption can't be fixed from within and rebuilding corrupt index is best and safest option.
Index issues or corruption can't be fixed from within and rebuilding corrupt index is best and safest option.
パフォーマンスとインデックス
Confluence のパフォーマンスの問題
If Confluence is facing performance problems during index rebuild operations, below are some of the things you should check:
- Check if Confluence Node or instance are facing Out of Memory condition, if yes, then follow Fix java.lang.OutOfMemoryError in Confluence KB to address them
- インデックスが破損していると負荷が高まる可能性があるため、インデックスのゼロからの再構築を試します (まだ行っていない場合)
- reindex.thread.count システム プロパティを 4 に設定することで、Confluence が利用するスレッドの数を一時的に減らしてみます。
- 上記の手順で意図した成果が得られない場合、インデックスの再構築中 (可能であればプロセスの開始時からある程度の時間が経過したあと) のスレッド ダンプ と CPU 情報をアトラシアン サポート用に集めてください。
添付ファイル
Confluence は添付ファイルからテキストを抽出し、検索用のインデックス構築を試みます。実現したい内容に応じ、この機能や潜在的な問題を取り上げたさまざまなナレッジベースを提供しています。
- 添付ファイルのインデックス作成を無効化する方法
- 添付ファイルの再インデックスに利用されるスレッドの数を変更する方法
- Confluence の再インデックスがスタックする
- ドキュメントのコンテンツが検索できない
- 添付ファイルのサイズを設定する
システム プロパティでインデックスを最適化する
If you wish for rebuilding index task to complete faster or if day to day index building is not keeping up with newly generate content rate, below parameters might help.![]() Try to focus on one parameter at a time to keep track of changes and control system load.
Try to focus on one parameter at a time to keep track of changes and control system load.
- -Dreindex.thread.count システム プロパティを 6 に設定し、一定数ずつ (2) 増やしながら、再構築処理中のディスク、CPU、メモリ負荷を監視します。
上記のパラメーターは、Lucene がインデックスの再構築タスク用に開放するスレッドの数を決定します。インデックスの再構築時間を短縮できるかどうかの確認に役立ちます。
- -Dreindex.attachments.thread.count システム プロパティを 6 に設定し、一定数ずつ (2) 増やしながら、再構築処理中のディスク、CPU、メモリ負荷を監視します。
上記のパラメーターは Lucene が添付ファイルのインデックスの再構築用に開放できるスレッドの数を決定します。たくさんの添付ファイルを持つシステムでインデックスの再構築時間を短縮できるかどうかの確認に役立ちます。
- -Dindex.queue.batch.size システム プロパティを 1500 に設定し、一定数ずつ (500) 増やしながら、通常処理中のディスク、CPU、メモリ負荷を監視します。
上記のパラメーターは Flush Edge Index Queue ジョブで毎回処理されるアイテムの数を決定します。ご利用のシステムで大量のコンテンツが生成されていて Lucene で追いつけず、キューが常に積み上がっているような場合に便利です。移行中や大量のコンテンツ生成が予測されるときに一時的に有効化できます。