Amazon S3 にバックアップを保存する
はじめる前に
Amazon S3 を使用してバックアップを保存することを検討している場合は、まず設定の要件と現在の制限事項を確認して、この保存方法が自社に適していることを確認してください。
Jira で S3 バックアップ ストレージを設定する方法
Amazon S3 のバックアップストレージは、Jira <localhome> にある filestore-config.xml ファイルで設定します。
S3 をバックアップ データの保存先として使用するには、 filestore-config.xml の filestore 属性がs3-filestore ID と一致している必要があります。
すでに S3 にアバターを保存している場合は、バックアップもそこに保存するように filestore-config.xml ファイルを設定できます。 これを行うには、ターゲット backupsを持つ新しい association 要素を追加します。
アバターと同じバケットにバックアップを保存する場合、filestore 属性は、アバターが保存されている同じバケットを指している必要があります。
バックアップとアバターに別々のバケットを使用するには、複数の <s3-filestore> エレメントを定義し、それぞれの関連付けターゲットでそれぞれを参照します。
バックアップの保存に Jira <sharedhome> ディレクトリを使用しつつも、設定ファイルを残したい場合は、target backups で association 要素を削除するだけです。filestore-config.xml Jira で S3 が構成されていない場合、またはこのファイルが <localhome> ディレクトリにない場合は、既定でローカルにバックアップが保存されます。
Amazon S3 のデュアルスタック エンドポイントに接続する
Jira インストール環境が IPv6 のみのネットワーク上にある場合は、Amazon S3 のデュアルスタック エンドポイントに接続する必要があります。Amazon S3 のデュアルスタック エンドポイントの詳細をご確認ください。
接続をセットアップするには、次のように既定のエンドポイントをデュアルスタック エンドポイントでオーバーライドする必要があります。
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="backupBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<endpoint-override>https://s3.dualstack.us-east-1.amazonaws.com</endpoint-override>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="backups" file-store="backupBucket" />
</associations>
</filestore-config>この設定オプションを使用して、S3 互換 API を公開しているサードパーティのオブジェクトストアにバックアップを保存することもできます。 ただし、アトラシアンでは、Amazon S3 以外のオブジェクトストアに保存されているバックアップに対する直接的なサポートは提供していません。
Amazon S3 を設定してバックアップを保存する
Amazon S3 の設定に進む準備ができたら、「 Amazon S3 をデータストレージとして設定する」の手順に従ってください。
S3 バケットを Jira に接続する
S3 オブジェクト ストレージを設定したら、作成した S3 バケットを Jira インスタンスに接続する必要があります。
Jira インストール ノードのいずれかの Jira アプリケーション ホーム ディレクトリで、
filestore-config.xmlファイルを作成します。Jira アプリケーションホームディレクトリは、JIRA_HOME環境変数の値に設定する必要があります。
Jira アプリケーション ホーム ディレクトリのコンテンツをご確認ください。filestore-config.xmlファイルで、バックアップとアバターを保存するために Jira が使用する S3 バケットを定義します。
S3 にアバターを保存する方法の詳細をご確認ください
サンプルfilestore-config.xmlファイル:<?xml version="1.1" ?> <filestore-config> <filestores> <s3-filestore id="backupBucket"> <config> <bucket-name>example-co-jira-backup-bucket</bucket-name> <region>ap-southeast-4</region> </config> </s3-filestore> </filestores> <associations> <association target="backups" file-store="backupBucket" /> </associations> </filestore-config>クラスタ インストールを実行している場合は、
filestore-config.xmlファイルを他のノードの Jira アプリケーション ホーム ディレクトリにコピーします。すべての Jira ノードを起動または再起動します。
Jira が起動すると、バケット接続、名前とリージョンの妥当性、バケットの権限などのバケット設定がチェックされます。潜在的なエラーとその修正方法をご確認ください。
Jira で Amazon S3 オブジェクト ストレージが使用されていることを確認するには、次の手順に従います。
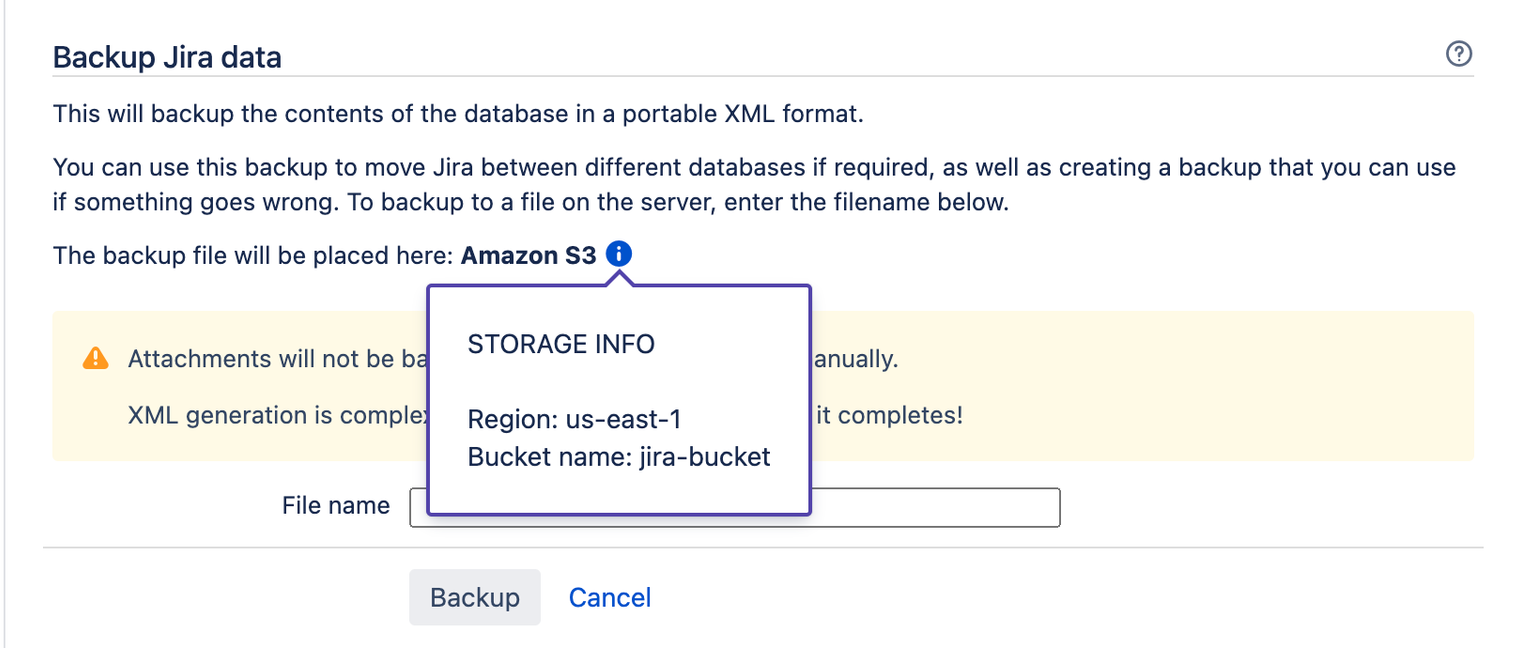
画面右上で [管理] > [システム] の順に選択します。
[ インポートとエクスポート ] 設定 (左側のパネル) で、[ システムをバックアップ] を選択します。
[ バックアップ ファイルはここに配置されます] の横に 、バックアップが S3 に保存されていることがわかります 。ここでは、S3 バケットの名前とリージョンを確認することもできます。\
復元プロセス
復元するには、バックアップ ファイルを S3 バケットから手動でダウンロードし、<sharedhome>/import ディレクトリに配置する必要があります。 XML バックアップからデータを復元する方法をご確認ください。
書き込み専用モード
S3 バケットへのアクセスを書き込み専用モード (アプリケーションには S3 ストレージへの新しいファイルの書き込み専用のアクセス権しかない状態) で許可することをお勧めします。
Identity and Access Management (IAM) ポリシーが適切なアクセス許可を提供する方法の例を次に示します。
{
"Version": "2012-10-17",
"Id": "PolicyForS3Access",
"Statement": [
{
"Sid": "StatementForS3Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:user/JiraS3"
},
"Action": [
"s3:PutObject"さらに、 バックアップ ファイルの上書きを回避するために、このバケットでバージョニングを有効にすることをお勧めします。
すべてのノードが毎時Jira、接続を確認するために小さなファイル (~60 バイト) を作成、読み取り、最後に S3 ストレージから削除します。書き込み専用モードではファイルを削除できないためJira、データが蓄積されます (ノードあたり年間 1 MiB 未満)。
これを回避するには、次の手順に従います。
- 次のロケーション (
{backupBucket}/backups/Healtcheck) から定期的にすべてのファイルを削除します。 オブジェクト ライフサイクル設定を追加します。
<LifecycleConfiguration> <Rule> <ID>Remove Health checks files</ID> <Filter> <Prefix>backups/Healthcheck/</Prefix> </Filter> <Status>Enabled</Status> <Expiration> <Days>5</Days> </Expiration> </Rule> </LifecycleConfiguration>
S3 バックアップ ストレージのトラブルシューティング
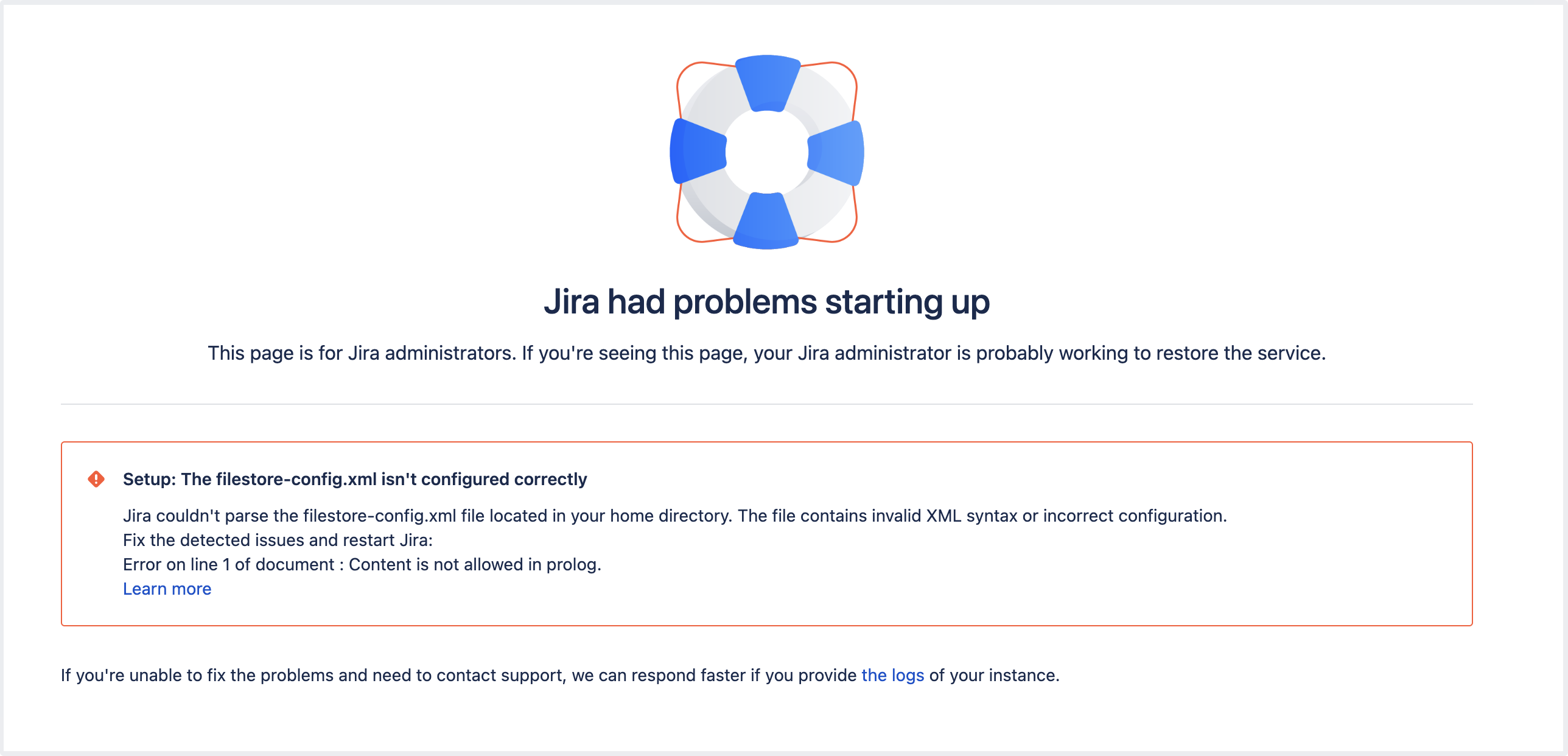
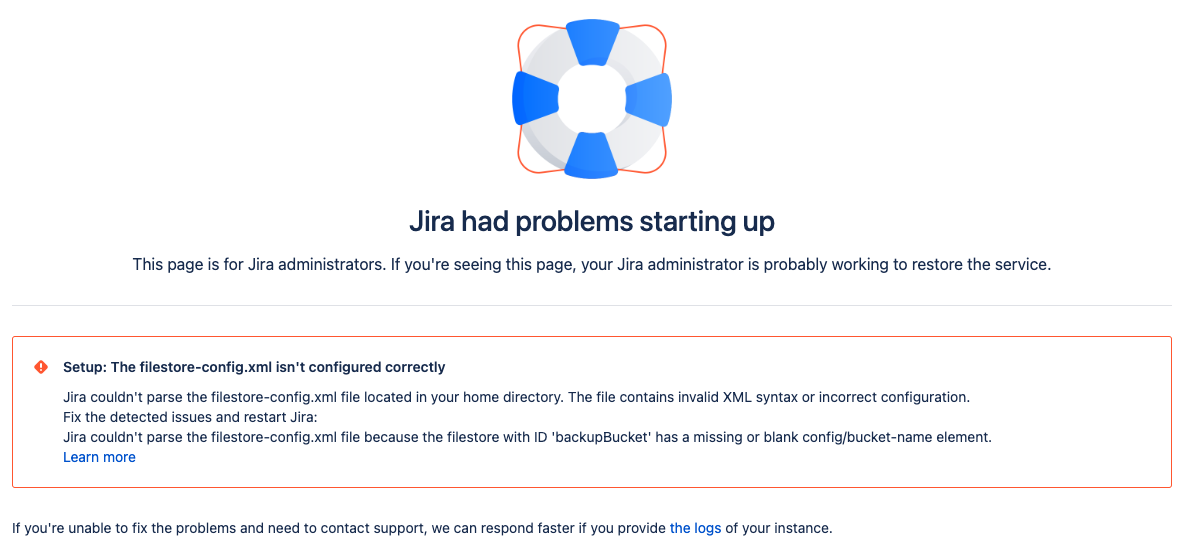
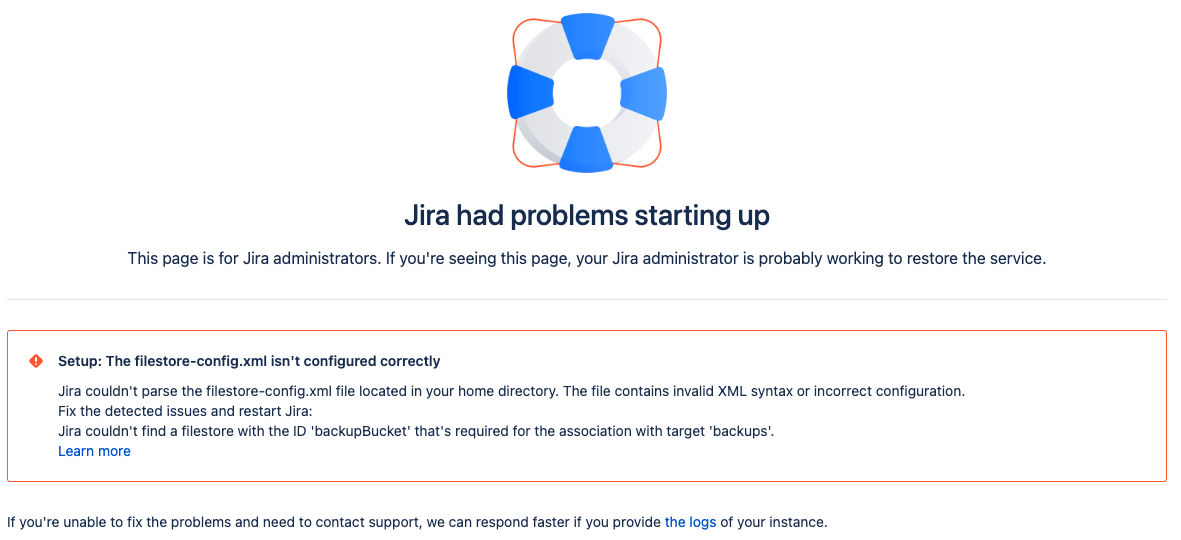
Jira が起動すると、filestore-config.xml ファイルに問題がないことを確認するために一連のチェックが実行されます。ファイルの解析中にエラーが発生した場合、Jira は起動せず、エラー メッセージが表示されます。
S3 への接続や操作で問題が発生した場合は、Jira でもその問題が検出され、バックアップ ファイルストア インスタンスのヘルス チェックが失敗としてフラグ付けされます。
次の各セクションでは、S3 の設定中に発生する可能性のある問題と解決手順を示します。これらの問題は主に不適切な S3 設定、権限、または認証に関連するものです。
Jira の起動の失敗
また、<localhome>/log/atlassian-jira.log でJiraログをチェックして、問題の詳細を確認することもできます。Jira ログにアクセスする方法をご確認ください。
| 問題 | 根本原因と解決方法 |
|---|---|
|
ファイルが有効な XML で構成されていることを確認してください。 |
|
filestore-config.xml で |
| 存在しない |
ヘルス チェックの失敗
インスタンスのヘルス チェックとその実行方法の詳細をご確認ください。
| 問題 | 根本原因と解決方法 |
|---|---|
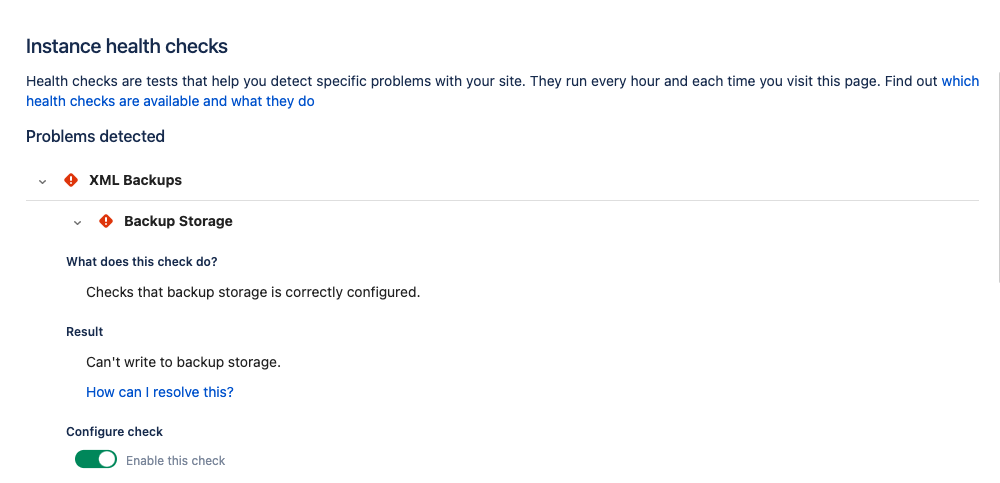
バックアップ ストレージに書き込めない
|
|
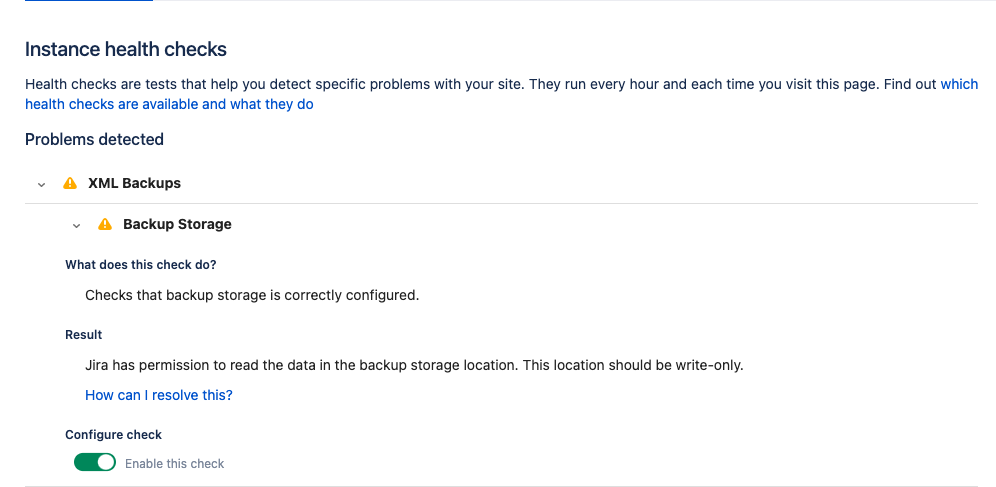
バックアップストレージからデータを読み取ることができる
| セキュリティを強化するため、書き込み専用モードの使用をお勧めします。
|
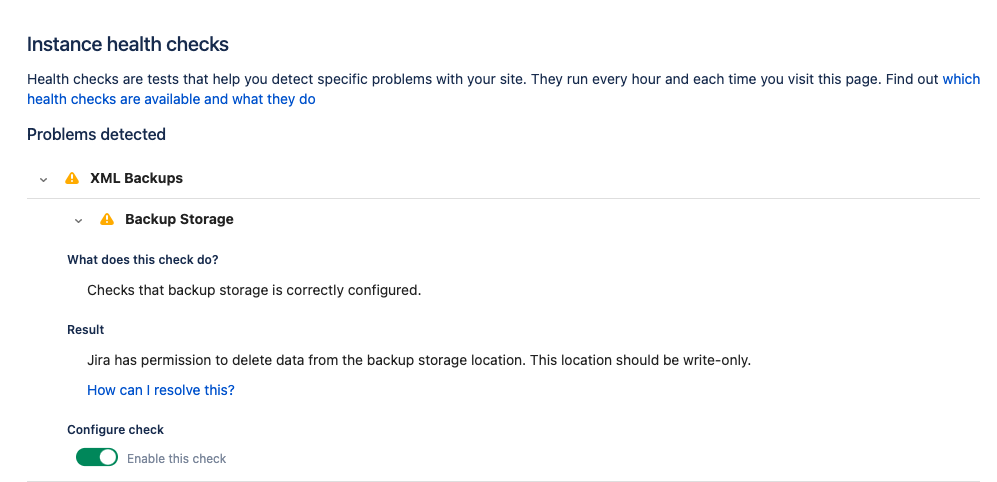
バックアップストレージからデータを削除できる
| セキュリティを強化するため、書き込み専用モードの使用をお勧めします。
|
低速または信頼性の低いネットワークにおける S3 接続の問題を軽減する
Jira は、Amazon S3 CRT 非同期クライアントを使用して Amazon S3 に接続します。
Amazon S3 CRT ベースのクライアントでは、1 つの接続で複数の同時スレッドを制御して、読み取り操作と書き込み操作を行うことができます。 Jira サーバーのインターネット接続が不安定または低速な場合、Jira 管理者はアップロードとダウンロードの失敗を軽減するようにクライアント設定を構成できます。
Amazon S3 CRT ベースのクライアントでは、いくつかのパラメーターを調整できますが、その中でも最も重要なのは max-concurrency です。 既定では、max-concurrency は 100 スレッドに設定されています。 これは、Jira ファイルストア設定filestore-configに導入されています。
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="backupBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<max-concurrency>100</max-concurrency>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="backups" file-store="backupBucket" />
</associations>
</filestore-config>同時接続の数が増えると、クライアントのスループットが向上する可能性があります。 これは、アプリでより多くのリソースを同時に管理しなければならないことも意味します。