Amazon S3 にアバターを保存する
Jira インスタンスに多数のユーザーがいて、アバターの提供に Gravatar を使用していない場合は、Amazon S3 にアバター ファイルを保存することをお勧めします。
Amazon S3 をストレージとして使用すると、バックアップとデータ復旧の手順が簡単になり、スケーラビリティも向上します。
アトラシアンでは、現在、ユーザー アバター、課題タイプ アイコン、プロジェクト アイコンの保存用に Amazon S3 をサポートしています。Jira Service Management では、リクエスト タイプ アイコンも対象となります。
はじめる前に
Amazon S3 を使用してアバター データを保存することを検討している場合は、まず設定の要件と現在の制限事項を確認して、この保存方法が自社に適していることを確認してください。Amazon S3 の設定の詳細をご確認ください。
Jira で S3 アバター ストレージをセットアップする方法
Amazon S3 のアバター ストレージは、Jira の <localhome> にある filestore-config.xml ファイルで設定します。
S3 をアバター データの保存先として使用するには、filestore-config.xml の filestore 属性が s3-filestore id と一致する必要があります。
ファイルを適切に設定したにもかかわらず、Amazon S3 との接続を確立できない場合は、Jira の起動時に S3 をアバター ファイルの保存先として再接続が試みられます。
アバターの保存に Jira の <sharedhome> ディレクトリを使用しつつも、設定ファイルを残す場合は、S3 との関連付けの定義をすべて削除してください。filestore-config.xml で S3 が設定されていない場合、またはファイルが <localhome> ディレクトリにない場合、Jira では既定でローカルにアバターが保存されます。
Amazon S3 のデュアルスタック エンドポイントに接続する
Jira インストール環境が IPv6 のみのネットワーク上にある場合は、Amazon S3 のデュアルスタック エンドポイントに接続する必要があります。Amazon S3 のデュアルスタック エンドポイントの詳細をご確認ください。
接続をセットアップするには、次のように既定のエンドポイントをデュアルスタック エンドポイントでオーバーライドする必要があります。
<?xml version="1.1" ?>
<filestore-config>
<filestores>
<s3-filestore id="avatarBucket">
<config>
<bucket-name>dualstack-bucket</bucket-name>
<region>us-east-1</region>
<endpoint-override>https://s3.dualstack.us-east-1.amazonaws.com</endpoint-override>
</config>
</s3-filestore>
</filestores>
<associations>
<association target="avatars" file-store="avatarBucket" />
</associations>
</filestore-config>この設定オプションを使用して、S3 互換の API を公開しているサードパーティのオブジェクト ストアにアバター ファイルを保存することもできます。ただし、アトラシアンでは、Amazon S3 以外のオブジェクト ストアに保存されているアバター ファイルに対する直接的なサポートは提供していません。
アバター データを Amazon S3 に移行する
ファイル システムに既存のアバター データがある場合に、Amazon S3 を使用するには、Jira で利用できるようにすべてのアバター データを S3 バケットに移行する必要があります。
アバター データを移行するには、次の手順に従います。
- Jira のバージョンをチェックし、Jira 9.9 以降を使用していることを確認します。
Jira 用の新しい Amazon S3 バケットを作成してセットアップします。Amazon S3 をデータ ストレージとして設定する方法をご確認ください。
アバター データを
<sharedhome>/data/avatars内の物理的な保存場所から S3 バケットのルート プレフィックスavatars/に移行します。アバター データの物理的な保存場所は、お使いの環境によって異なります。たとえば、クラスタ環境では、通常、このデータを共有マウントとしてネットワーク ファイル システム (NFS) でホストします。
現在のセットアップと移行対象データの量を検討する必要があります。一般的に、移行には Amazon DataSync を使用することをお勧めします。
移行が完了するまで待ちます。
Jira クラスタの各ノードの
<localhome>に有効な S3 バケット情報を含む filestore-config.xml ファイルを作成して、Jira ノードを 1 つずつ設定します。適切な設定を指定したら、各ノードを再起動する必要があります。このプロセス中に、S3 用にまだ設定されていないノードでアバター ファイルが作成された場合、すでに設定済みのノードではアバター データを使用できなくなります。同様に、これらのノードは、すでに S3 を使用するように設定されているノードで作成されたアバターにはアクセスできなくなります。
Jira で S3 オブジェクト ストレージが使用されていることを確認します。
画面右上で
 (管理) > [システム] の順に選択します。
(管理) > [システム] の順に選択します。[詳細] (左側のパネル) で、[アバター] を選択します。ページに直接アクセスするには、
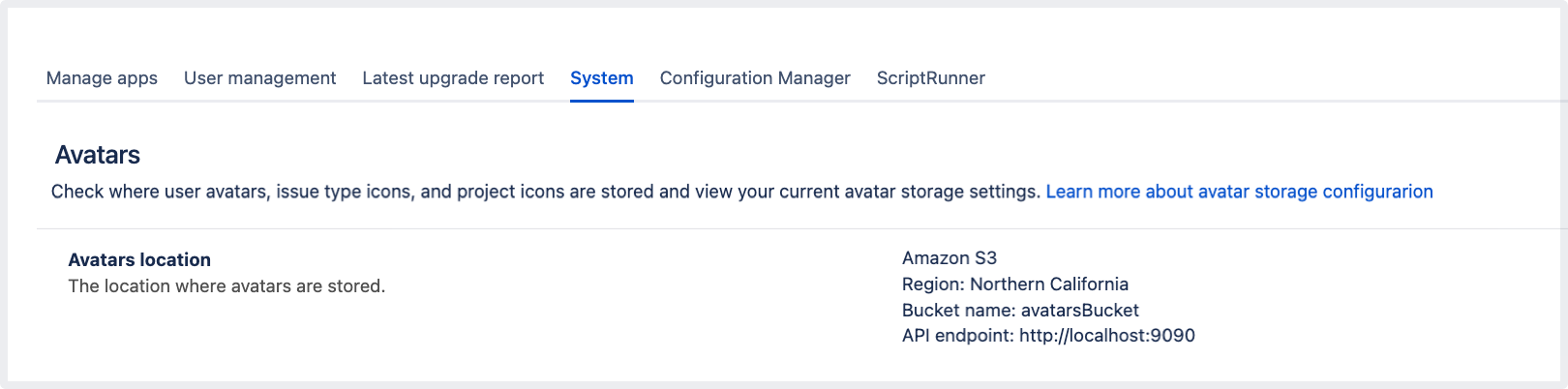
ggショートカットを使用するか、ピリオド (.) を押して「アバター」を検索します。[アバターの場所] の横に、Amazon S3 のほか、filestore-config.xml で指定したリージョンとバケットが表示されるはずです。
すべてのノードが設定され、すべてのアバターが移行されていることを確認してから、元の DataSync ジョブを再実行して最終同期を行います。
これで、すべてのアバターの読み取り / 書き込みが Amazon S3 で行われるようになったはずです。
DataSync では、ソース ファイル システムのデータは変更または削除されません。そのファイル システムにあるアバターが不要になった場合は、このデータを手動で削除する必要があります。
ローカルのアバター ストレージに戻す
ソース ファイル システムのデータは DataSync によって変更または削除されないため、そのファイル システムに対してアバター データの読み取り / 書き込みを行うように戻すことができます。そのためには、<localhome> ディレクトリから filestore-config.xml ファイルを削除し、Jira を再起動します。アバターをターゲットとする <association> 要素を削除することもできます。
元のファイル システムに戻す場合は、S3 に書き込まれたすべてのデータについて、Jira 管理者が手動で元のファイル システムに同期させる必要があります。
Amazon S3 をアバター データの保存用に設定する
Amazon S3 の設定に進む準備ができたら、「Amazon S3 をデータ ストレージとして設定する」の手順に従ってください。
S3 バケットを Jira に接続する
S3 オブジェクト ストレージを設定したら、作成した S3 バケットを Jira インスタンスに接続する必要があります。
Jira インストール環境のいずれかのノードの Jira アプリケーション ホーム ディレクトリで、
filestore-config.xmlファイルを作成します。Jira アプリケーション ホーム ディレクトリは、JIRA_HOME環境変数の値に設定する必要があります。Jira アプリケーション ホーム ディレクトリのコンテンツをご確認ください。filestore-config.xmlファイルで、アバター (および将来的には添付ファイル) を保存するために Jira で使用される S3 バケットを定義します。サンプル
filestore-config.xml file:<?xml version="1.1" ?> <filestore-config> <filestores> <s3-filestore id="avatarBucket"> <config> <bucket-name>example-co-jira-avatar-bucket</bucket-name> <region>ap-southeast-4</region> </config> </s3-filestore> </filestores> <associations> <association target="avatars" file-store="avatarBucket" /> </associations> </filestore-config>クラスタ インストールを実行している場合は、
filestore-config.xmlファイルを他のノードの Jira アプリケーション ホーム ディレクトリにコピーします。すべての Jira ノードを起動または再起動します。
Jira が起動すると、バケット接続、名前とリージョンの有効性、バケット権限などのバケット設定がチェックされます。潜在的なエラーとその修正方法をご確認ください。
Jira で Amazon S3 オブジェクト ストレージが使用されていることを確認するには、次の手順に従います。
画面右上で
(管理) > [システム] の順に選択します。[詳細] 設定 (左側のパネル) で、[アバター] を選択します。
[アバターの場所] の横に、アバターの保存先として S3 が表示されます。ここでは、S3 バケットの名前とリージョンを確認することもできます。
S3 アバター ストレージをトラブルシューティングする
Jira が起動すると、filestore-config.xml ファイルに問題がないことを確認するために一連のチェックが実行されます。ファイルの解析中にエラーが発生した場合、Jira は起動せず、エラー メッセージが表示されます。
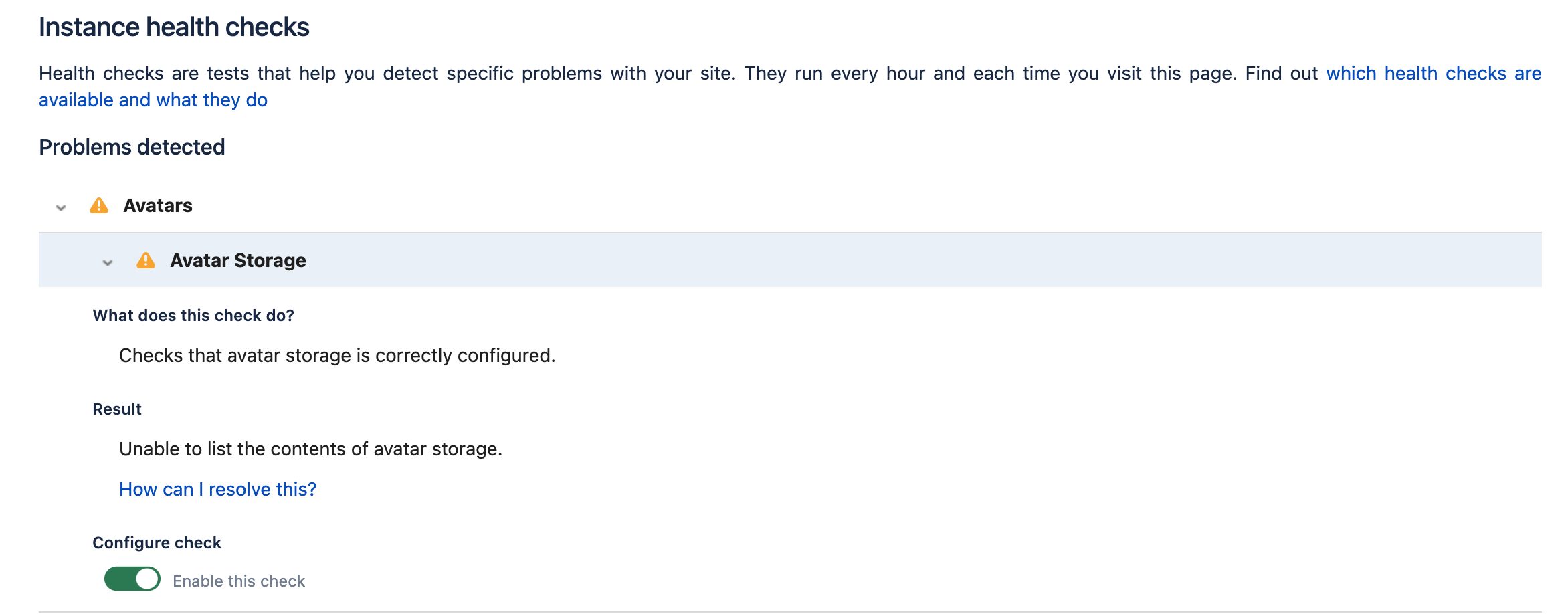
S3 への接続や操作で問題が発生した場合は、Jira でもその問題が検出され、アバター インスタンスのヘルス チェックが失敗としてフラグ付けされます。
次の各セクションでは、S3 の設定中に発生する可能性のある問題と解決手順を示します。これらの問題は主に不適切な S3 設定、権限、または認証に関連するものです。
Jira の起動の失敗
問題の詳細は、Jira ログ (<localhome>/log/atlassian-jira.log) でも確認できます。Jira ログにアクセスする方法をご確認ください。
問題 | 根本原因と解決方法 |
|---|---|
|
filestore-config.xml で |
| 存在しない |


ヘルス チェックの失敗
インスタンスのヘルス チェックとその実行方法の詳細をご確認ください。インスタンスのヘルス チェックの詳細
問題 | 根本原因と解決方法 |
|---|---|
アバター ストレージのコンテンツをリストできない
| このヘルス チェックは、次の理由で失敗する可能性があります。
問題の診断についてサポートが必要な場合は、 |
アバター ストレージからデータを読み取れない
|
|
アバター ストレージに書き込めない
|
|
アバター ストレージからファイルを削除できない
|
|