CSVからのデータのインポート
CSV ファイルの準備
課題をインポートしようとして管理者権限を持っていない場合は、代わりに課題の一括インポートを使用します。
Jira Importers プラグインは、ご利用の CSV ファイルが既定の Microsoft Excel 形式の CSV ファイルに基づいているものと想定します。
- フィールドはカンマで区切られます。
- カンマや改行/キャリッジ リターンなど、文字どおりに扱う必要があるコンテンツは引用符で囲まれます。
Microsoft Excel と OpenOffice の場合、セル内の値を引用符で囲む必要はありません。これらのアプリケーションでは、自動でこの処理が行われます。
CSV ファイルの要件
CSV ファイルは「正しいフォーマット」であることに加えて、次の要件を満たす必要があります。
各 CSV ファイルには、要約列を持つ見出し行が存在する必要がある
CSV ファイル インポート ウィザード (以下の手順を参照) は、CSV ファイルのヘッダー行によって CSV ファイルの 2 行目以降のデータを Jira のフィールドにマッピングする方法を決定します。
各列を区切るカンマを除いて、ヘッダー行には句読点を含めないでください。インポーターが正常に動作しない場合があります。
ヘッダー行には課題の「要約」データの列が含まれている必要があります。
列/フィールドのセパレーターとしてのコンマは省略不可
たとえば次の形式は有効です。
Summary, Assignee, Reporter, Issue Type, Description, Priority
"Test issue", admin, admin, 1, ,次の例は無効となります。
Summary, Assignee, Reporter, Issue Type, Description, Priority
"Test issue", admin, admin, 1CSV ファイルで Jira データ構造をカプセル化する
このセクションでは、次のような問題の解決策を説明します。
複数行にまたがるデータを取得する
複数行にまたがるデータを取り込むには、二重引用符 (") をCSV ファイルで使用します。たとえば、Jira はインポート中に、次のような例を単一レコードの有効な CSV ファイルとして扱います。
Summary, Description, Status
"Login fails", "This is on
a new line", Open特殊文字を文字どおりに扱う
テキスト部分を二重引用符 (") で囲むと、その範囲の特殊文字を文字どおりに扱うように指定できます。このデータが Jira にインポートされると、これらの特殊文字は Jira のフィールド データの一部として保管されます。特殊文字の例としては、キャリッジリターン / 改行文字、コンマなどがあります。
二重引用符をもう 1 つ追加して「エスケープ」すると、二重引用符を文字どおり扱えます。次に例を示します。
- CSV ファイルには
"Clicking the ""Add"" button results in a page not found error"のような値が含まれている場合があります。 - インポート後は
Clicking the "Add" button results in a page not found errorのように Jira に保存されます。
複数の値を単一の Jira フィールドに集約する
複数の値を、複数の値を受け入れる Jira フィールドにインポートできます。たとえば、修正 (対象) バージョン、影響を受けたバージョン、コンポーネント、ラベルなどです。これを行うには、マッピングされる Jira フィールドに集約する各値について、CSV ファイルで同じ列名を指定する必要があります。指定する列名の数は、マッピングされるフィールドに集約される値の最大数と一致している必要があります。次に例を示します。
IssueType, Summary, FixVersion, FixVersion, FixVersion, Component, Component
bug, "First issue", v1, , , Component1,
bug, "Second issue", v2, , , Component1, Component2
bug, "Third issue", v1, v2, v3, Component1,
上の例では、2 番目の課題の [コンポーネント] と 3 番目の課題の [修正バージョン] の各フィールドが、複数の値をインポート時に該当する Jira フィールドに生成します。
複数の値をサポートしている Jira フィールドの数には限りがあるため、ご注意ください。CSV インポーターでは、単一の値のみをサポートしている Jira フィールドに集約データをインポートできません。
添付ファイルをインポートする
ファイルを CSV ファイルから作成された課題に添付できます。これを行うには、添付ファイルの URL を CSV ファイルにある [添付ファイル] 列で指定します。
Assignee, Summary, Description, Attachment, Comment
Admin, "Issue demonstrating the CSV attachment import", "Please check the attached image below.", "https://jira-server:8080/secure/attachment/image-name.png", "01/01/2012 10:10;Admin; This comment works"
Admin, "CSV attachment import with timestamp,author and filename", "Please check the attached image below.", "01/01/2012 13:10;Admin;image.png;file://image-name.png", "01/01/2012 10:10;Admin; This comment works"添付ファイルの URL は HTTP と HTTPS の各プロトコルをサポートしています。Jira Server がアクセスできる場所に配置できます。また、FILE プロトコルによって、Jira ホーム ディレクトリの import/attachments サブディレクトリにあるファイルにアクセスできます。
サブタスクの作成
CSV ファイルを使用してサブタスクをインポートすると、Jira は"External issue ID (外部課題 ID)"という新しいカスタム フィールドを作成することに注意してください。既存の外部課題 ID の値と重複する課題 ID を持つ課題はインポートされません。
この構造を CSV ファイルでカプセル化することで、CSV ファイルのインポートを通して課題のサブタスクを作成できます。これを行うには、次の操作を実行します。
CSV ファイルには追加の列が 2 つ必要です。これらの列の見出しには、課題 ID と親 ID に類似した名前を付けます。
それぞれの標準 (非サブタスク) 課題で、"課題 ID" 列に固有の通し番号が付けられていることを確認します。標準課題の "親 ID" フィールドには値を設定しないでください。
標準課題のサブタスクを CSV ファイルに作成するには、標準課題に設定された固有の課題 ID 番号を "親 ID" 列で参照します。サブタスクの "課題 ID" フィールドには値を設定しないでください。
例:
IssueType, Summary, FixVersion, FixVersion, FixVersion, Component, Component, Issue ID, Parent ID, Reporter
Bug, "First issue", v1, , , Component1, , 1, , jbloggs
Bug, "Second issue", v2, , , Component1, Component2, 2, , fferdinando
Bug, "Third issue", v1, v2, v3, Component1, , 3, , fferdinando
Sub-task, "Fourth issue", v1, v2, , Component2, , , 2, jbloggs上の例では、CSV ファイル インポート ウィザードの実行時に、CSV ファイルの "課題 ID" と "親 ID" の各フィールドが、それぞれ Jira の "課題 ID" と "親 ID" の各フィールドに一致している場合は、4 番目の課題が 2 番目の課題のサブタスクとしてインポートされます。
複数の Jira プロジェクトに課題をインポートする
CSV ファイルのインポートを通じて、1 つの CSV ファイルから複数の Jira プロジェクトにインポートできます。この場合、次の点に留意します。
- CSV ファイルには他に 2 つの列が必要です。これらの列の見出しには、プロジェクト名やプロジェクト キーに類似した名前を付ける必要があります。
CSV ファイルにあるすべての課題で、インポート先の Jira プロジェクト用の列に適切な名前とキーが含まれていることをご確認ください。
プロジェクト名とキーのデータは、課題を CSV から特定の Jira プロジェクトにインポートするための最小限の Jira プロジェクト データとなります。
IssueType, Summary, Project Name, Project Key
bug, "First issue", Sample, SAMP
bug, "Second issue", Sample, SAMP
task, "Third issue", Example, EXAMこの例では、CSV ファイル インポート ウィザードの実行中に、CSV ファイルの [プロジェクト名] と [プロジェクト キー] の各フィールドを Jira の [プロジェクト名] と [プロジェクト キー] の各フィールドに一致させている場合は、1 番目と 2 番目の課題が "Sample" プロジェクト (プロジェクト キー "SAMP") に、3 番目の課題が "Example" プロジェクト (プロジェクト キー "EXAM") にインポートされます。
未解決の課題を処理する
"解決状況"、"優先度"、"課題タイプ" へのフィールド マッピングについては、Jira で利用可能な値が入った選択リストが提供されます。また、緑色のプラス記号をクリックすれば、Jira に存在しない値をすぐに作成できます。
ステータスへのフィールド マッピングについては、Jira で利用可能な値が入った選択リストが提供されますが、新しいステータス値を作成するプラス記号は提供されません。
これらの 4 つのフィールドについては、Jira で使用可能な値のほかに、次の 2 つの特別なオプションが選択リストに用意されます。
- 空としてインポート: 選択すると、そのフィールドの Jira 値は空になります。未解決の課題をインポートする場合は、[解決状況] フィールドをマッピングするフィールドを作成して、値を「未解決」から「空としてインポート」に変更する必要があります。
- マッピングなし: CSV ファイルの値をそのままインポートしようとするものです。フィールド値に「マッピングなし」を使用する場合は、値がその Jira フィールドで有効でないとインポートが失敗します。[ステータス] と [課題タイプ] にマッピングされたフィールドについては「空としてインポート」オプションを選択すると既定値が使用されます。
作業ログ エントリのインポート
CSV ファイルには作業ログ エントリを含めることができます。例:
Summary,Worklog
Only time spent (one hour),3600
With a date and an author,2012-02-10 12:30:10;wseliga;120
With an additional comment,Testing took me 3 days;2012-02-10 12:30:10;wseliga;259200
消費時間を追跡するには、秒単位を使用する必要があります。
複数選択カスタム フィールドへのインポート
CSV ファイルには、1 つの複数選択カスタムフィールドへの複数のエントリを含めることができます。例:
Summary,Multi Select,Multi Select,Multi Select
Sample issue,Value 1,Value 2,Value 3これは、複数の値を持つ複数選択カスタムフィールドにデータを追加します。
カスケード選択カスタム フィールドへのインポート
次の構文を使用して、カスケード選択カスタム フィールドに値をインポートできます。
Summary, My Cascading Custom Field
Example Summary, Parent Value -> Child Value"->" セパレーターを使用すると、 階層をインポートできます。
現在、Jira は CSV を経由したマルチレベルのカスケード選択フィールドのインポートをサポートしていません ( JRA-34202 - 課題詳細の取得… ステータス )。
既存の課題の更新
Jira Importers プラグインのバージョン 4.3 以降は、既存の課題を更新できます。インポート中、CSV ファイルには課題キーにマッピングされる列が含まれている必要があります。所定のキーに対応する課題が存在する場合は、その課題が更新されます。次に例を示します。
issue key,summary,votes,labels,labels
TT-1,Original summary,1,label1,label2
TT-1,,7,label-1,label-2
TT-1,Changed summary,,,
TT-2,Original summary 2,1,label-1,label-2
TT-2,,<<!clear!>>,<<!clear!>>,最初の行では課題を作成して 2 行目では投票を 7 に設定し、2 つのラベルを追加します。その次の行では要約が変更されます。課題 TT- 2 は 2 つのラベルと併せて作成されますが、2 行目は特殊なマーカー <<!clear!>> によってこれらのラベルを削除します。
CSV をインポートして既存の課題を更新する場合、CSV で指定されていない列は既定値にリセットされます。
CSV ファイル インポート ウィザードを実行する
まずは Jira データをバックアップする必要があります。
外部システム インポートを使用して課題を Jira にインポートするには、次のステップを実行します。
- Jira 管理者グローバル権限を持つユーザーとしてログインします。
- [管理] > [システム] > [インポートとエクスポート] > [外部システム インポート] の順に選択します。
- [CSV] を選択して [CSV ファイルのインポート] ページを開きます。
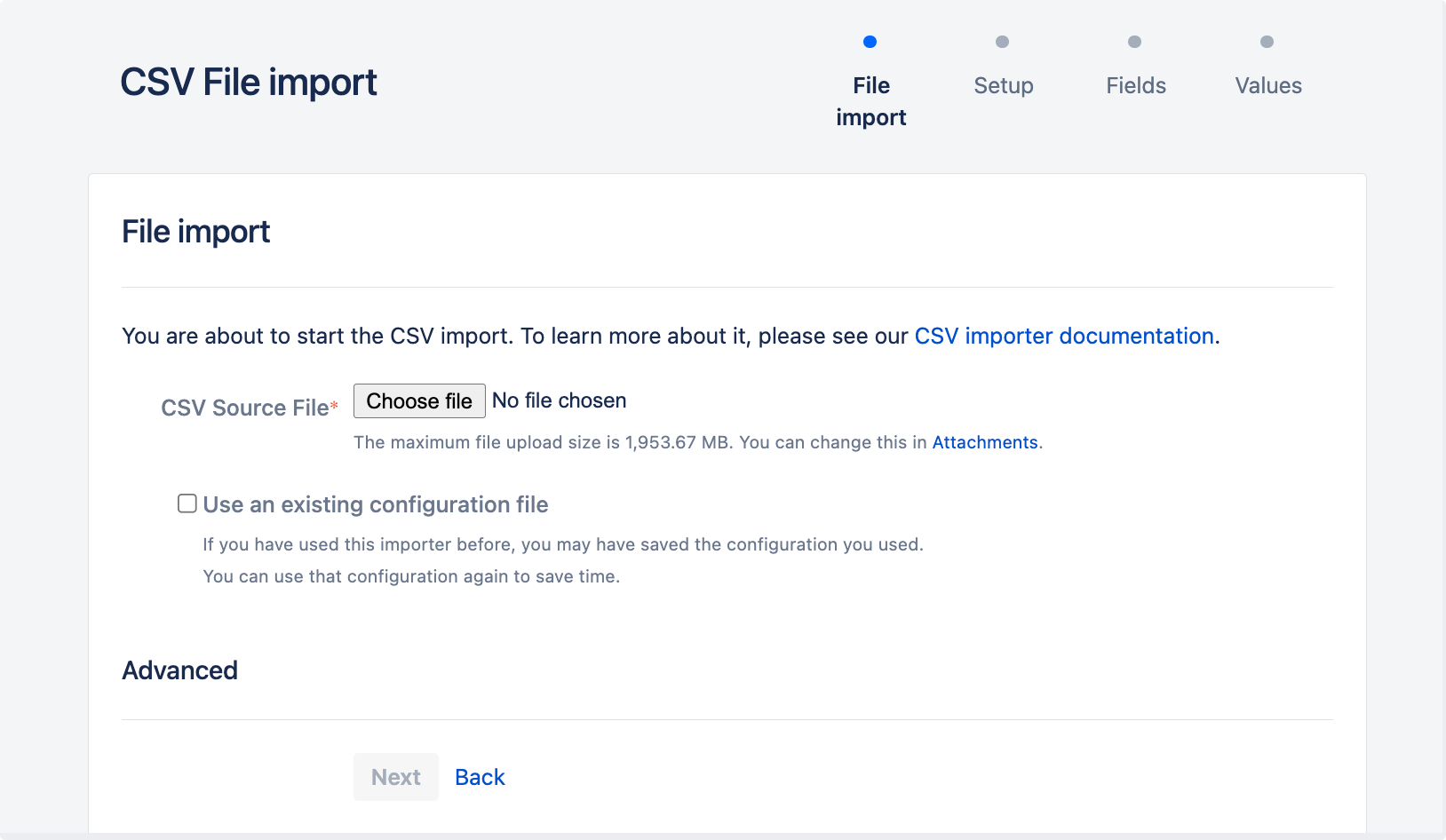
"CSV ファイルのインポート" ページで、CSV ソース ファイルを選択します。ファイルのエンコードと CSV 区切り文字のフォーマットを変更する場合は、[詳細] 見出しを選択して、このオプションを表示します。
- このファイルは、ここで指定するファイル エンコード タイプによってインポートされます。既定のファイル タイプは UTF-8 です。
- CSV ファイルでコンマ以外の別の区切り文字を使用する場合、[CSV 区切り記号] フィールドでその文字を指定します。
設定ファイルがない、または新しい設定ファイルを作成する場合は、[既存の設定ファイルを使用] チェックボックスを空のままにしておきます。設定ファイルは、CSV ファイルのヘッダー行の列名と Jira インストールのフィールド間のマッピングを指定します。
- このオプションを選択すると、既存の設定ファイルを指定するかどうか尋ねられます。
- このオプションを選択しない場合、CSV ファイル インポート ウィザードの最後に、以降の CSV インポート (CSV ファイル インポート ウィザードの本ステップ) で使用できる設定ファイルが作成されます。
- [次へ] を選択して、CSV ファイル インポート ウィザードの「プロジェクト マッピングをセットアップする」ステップに進みます。
「プロジェクト マッピングをセットアップする」ページでは、すべての課題を 1 つの Jira プロジェクト (新規または既存) または複数の Jira プロジェクトにインポートするかを選択できます。複数のプロジェクトにインポートする場合は、CSV ファイルに必要最小限の Jira プロジェクト データ (Jira プロジェクト名とキー) が含まれていることをご確認ください。次のフィールド/オプションを入力します。
Jira プロジェクトへのインポート 以下のいずれかを選択します。
- プロジェクトを選択します。このオプションによって、既存の Jira プロジェクトに課題をインポートするか、新しいプロジェクトを作成して課題をインポートします。
- Jira に存在するプロジェクトの名前 (またはキー) を入力するか、ドロップダウン メニューを使用して既存の Jira プロジェクトを選択します。
- ドロップダウン メニューから [新規作成] を選択して、そこに表示される [新規プロジェクトを追加] ダイアログ ボックスで次のフィールドに入力します。
- プロジェクトの名前を入力する
プロジェクト キーを入力する
これは、JIRA プロジェクトにあるすべての課題 ID のプレフィックスとして使用されます。
- プロジェクト リードを指定する
- [CSVで定義済み] オプションによって、課題を複数の Jira プロジェクトにインポートします。CSV ファイルにあるすべての課題に Jira プロジェクト名とプロジェクト キー用のデータが含まれていることをご確認ください。詳細は「課題を複数の Jira プロジェクトにインポートする」をご参照ください。
新規ユーザー用のメール識別子 CSV ファイルで指定している、インポート中に Jira に追加される新規ユーザー用のメール アドレス ドメインを入力します。 インポートファイルの日付形式 CSV ファイルで使用する日付形式を指定します。Java SimpleDateFormat に準拠した構文を使用します。 課題のインポート先のプロジェクトのキーが課題キーと同じであることを確認します。同じではない場合、Jira は課題をプロジェクトにインポートしますが、新しい課題キーが与えられます。
- プロジェクトを選択します。このオプションによって、既存の Jira プロジェクトに課題をインポートするか、新しいプロジェクトを作成して課題をインポートします。
[次へ] を選択して、CSV ファイル インポート ウィザードの「フィールド マッピングをセットアップする」ステップに進みます。
「フィールド マッピングをセットアップする」ページで、CSV ファイルのフィールドを選択したプロジェクトの課題フィールドにマッピングします。[Jira フィールド] 列で、CSV ファイルからフィールドにマッピングする Jira フィールドを選択します。CSV と Jira の各フィールドの一致に関する詳細については、次の「CSV データを Jira フィールドにインポートするためのヒント」をご参照ください。
- Jira フィールドのいずれかとして要約フィールドを指定する必要があります。これを行うまで、[次へ] ボタンを利用することはできません。
CSV ファイルにそのヘッダー行で指定された同名のフィールドが複数含まれている場合は、CSV ファイル インポート ウィザードによってこれらのフィールドが単一のフィールドに集約にされます。ウィザードのこのステップでは
 アイコンのマークが付きます。
アイコンのマークが付きます。CSV ファイル インポート ウィザードで集約した CSV フィールドに対しては、複数の値をサポートする Jira フィールドのみ選択できます。
- サブタスクをインポートする場合、Jira の "課題 ID" フィールドと "親 ID" フィールドを CSV ファイルの対応するフィールドに一致させる必要があります。
- 複数のプロジェクトに課題をインポートする場合は「プロジェクト マッピングをセットアップする」ステップで [CSVで定義済み] を選択していることをご確認ください。Jira の [プロジェクト名] と [プロジェクトキー] の各フィールドを、CSV ファイルのフィールドと必ず一致させてください。
- CSV ファイルのフィールドのデータの値を Jira にインポートされる前に変更する場合、該当のフィールドの横にある [フィールドの値のマッピング] チェックボックスを選択します。
- [次へ] を選択して、CSV ファイル インポート ウィザードの「値のマッピングをセットアップする」ステップに進みます。
「値のマッピングをセットアップする」ページで、CSV ファイル インポート ウィザードで検出された各 CSV ファイルのフィールド値に対応する Jira フィールド値を指定します。
- CSV ファイル インポート ウィザードの前のステップで [フィールド値をマッピング] チェックボックスにチェックをつけたフィールドが、このページに表示されます。
値を現状のままインポートする場合は、フィールドを空欄のままにしておくかフィールド内のコンテンツを消去します。
適切なフィールドの横にある [Add new (新規追加)] リンクを選択すると、Jira で (CSV ファイルのデータに基づいて) 優先度、解決状況、課題タイプのそれぞれの値を新しく作成できます。
ユーザー名ベースの CSV フィールド (報告者または担当者など) をインポートしていて、CSV ファイル インポート ウィザードの前のステップでこのフィールドの [フィールド値をマッピング] チェックボックスをチェックしていなかった場合、インポーターは CSV ファイルからインポートされるユーザー名を (小文字の) Jira ユーザー名に自動でマッピングします。
Jira でユーザー名をまだ定義していない場合は、[フィールド値をマッピング] チェックボックスをチェックしているかどうかにかかわらず、Jira は CSV ファイルのデータに基づいてユーザー名を自動で作成します。
CSV データを Jira にインポートする準備が整ったら、[インポート開始] ボタンを選択します。インポーターはインポートの進行に合わせて更新状況を、インポートが完了すると正常に完了したことを示すメッセージを表示します。
- インポートで問題が生じた (または確認したい) 場合は、[download a detailed log (詳細ログをダウンロード)] リンクを選択して CSV ファイルのインポート処理に関する詳細を表示します。
- 別の CSV ファイルをこの手順で使用した設定と同じ (または類似の) 設定でインポートする必要がある場合は、[設定を保存] リンクを選択して CSV 設定ファイルをダウンロードします。この設定ファイルは、CSV ファイル インポート ウィザードの最初のステップで使用できます。
これで、CSV データを Jira に正常にインポートできました。ご不明な点や、問題が生じた場合は、アトラシアン サポートにご連絡ください。
CSV データを Jira フィールドにインポートするためのヒント
データを CSV ファイルから特定の Jira フィールドにインポートする際に役立つヒントをご紹介します。
CSV ファイルのフィールドが Jira の課題画面に表示されていない場合、そのフィールドはフィールド マッピングのドロップダウン リストにも表示されません。解決策については、ナレッジ ベース記事「Jira Server / Data Center で CSV により課題をインポートする際にマッピング対象のフィールドが不足している」をご確認ください。
Jira フィールド | インポート時の注意 |
|---|---|
プロジェクト | CSV データはプロジェクト単位でインポートされます。既存の Jira プロジェクトを対象として指定できますが、指定しなくてもインポート時にインポーターが新規プロジェクトを自動で作成します。 |
要約 | これは唯一の必須フィールドです。 |
| 課題キー | インポートされた課題の課題キーを設定できます。対象のキーの課題がすでに存在する場合、その課題が更新されます。 |
コンポーネント | 単独の列に各コンポーネントを入力することで、複数のコンポーネントを持つ課題をインポートできます。 |
影響バージョン | 単独の列に各バージョンを入力することで、複数の「影響バージョン」を持つ課題をインポートできます。 |
修正バージョン | 個別の列に各バージョンを入力することで、複数の "修正バージョン" を持つ課題をインポートできます。 |
コメント本文 | 単独の列に各コメントを入力することで、複数のコメントを持つ課題をインポートできます。 |
作成日 | CSV インポート ウィザードの 2 番目の手順で指定した日付形式を使用してください。 |
更新日 | CSV インポート ウィザードの 2 番目の手順で指定した日付形式を使用してください。 |
期限 | CSV インポート ウィザードの 2 番目の手順で指定した日付形式を使用してください。 |
課題タイプ | CSV ファイルで指定されていない場合、インポートされた課題には、Jira システムの課題タイプ フィールド値の定義で指定された既定 (1 番目) の課題タイプが設定されます。インポート処理中に新しい Jira 値を作成することもできます。 |
ラベル | 以下の方法で複数のラベルが付いた課題をインポートできます。
|
Priority | CSV ファイルで指定されていない場合、インポートされた課題には、Jira システムの優先度フィールド値の定義で指定された既定 (1 番目) の優先度が設定されます。インポート処理中に新しい Jira 値を作成することもできます。 |
ソリューション | CSV ファイルで指定されていない場合、インポートされた課題には、Jira システムの解決状況フィールド値の定義で指定された既定 (1 番目) の解決状況が設定されます。インポート処理中に新しい Jira 値を作成することもできます。 役立つヒントとして、未解決の課題を取り扱う方法も参照してください。 |
ステータス | Jira の既存のワークフロー ステータスにのみマッピングできます。CSV ファイルでステータスが指定されていない場合、インポートされた課題には、Jira システムで指定されている既定 (1 番目) のステータスが設定されます。 |
初期見積 | このフィールドの値は、秒数で指定する必要があります。 |
残余見積 | このフィールドの値は、秒数で指定する必要があります。 |
消費時間 | このフィールドの値は、秒数で指定する必要があります。 |
ユーザー | 担当者または報告者フィールドの任意の値から、インポーターに Jira ユーザーを自動で作成させることも可能です。
|
| ウォッチャー | ウォッチャーに指定されたユーザーが CSV ファイルに含まれているが、Jira には存在しない場合、このユーザーはインポートされません。特定の課題のウォッチャーとしてインポートする前に、ユーザーを Jira で利用可能にしておく必要があります。 |
その他のフィールド | 他のフィールドをインポートする場合は、特定の Jira カスタム フィールドへのマッピングを行うことができます。Jira にカスタム フィールドが存在していない場合、インポーターは自動的にカスタム フィールドを作成します。カスタム フィールドが日付フィールドの場合、CSV インポーター ウィザードの 2 番目の手順で指定した日付形式を使用してください。 |
課題の一括インポート
課題の一括インポート機能では、管理者以外のユーザーが課題を Jira にインポートできます。上述の外部システム インポートは、Jira 管理者のみが利用できます。
課題の一括インポートでは、CSV ファイルからも課題をインポートする必要があります。ただし、課題の一括インポートを実行するエントリ ポイントとステップは、外部システム インポートとは異なります。
課題の一括インポート機能には、次のような制限があります。
- 新しいユーザーは作成されません。
- 新しいプロジェクトはインポートされません。課題は既存のプロジェクトにのみインポートする必要があります。
- カスタム フィールドと解決状況の値は課題内で作成されません。
- 課題の一部のフィールドが欠落する場合があります。こうしたフィールドの完全なリストは「Jira で CSV を使用して課題をインポートする際のマッピング用の欠落フィールド」をご参照ください。
こちらに記載されているように、Jira 課題を含む CSV ファイルを準備します。ファイルをインポートするには、次の手順に従います。
- [課題] > [CSV から課題をインポート] の順に選択します。
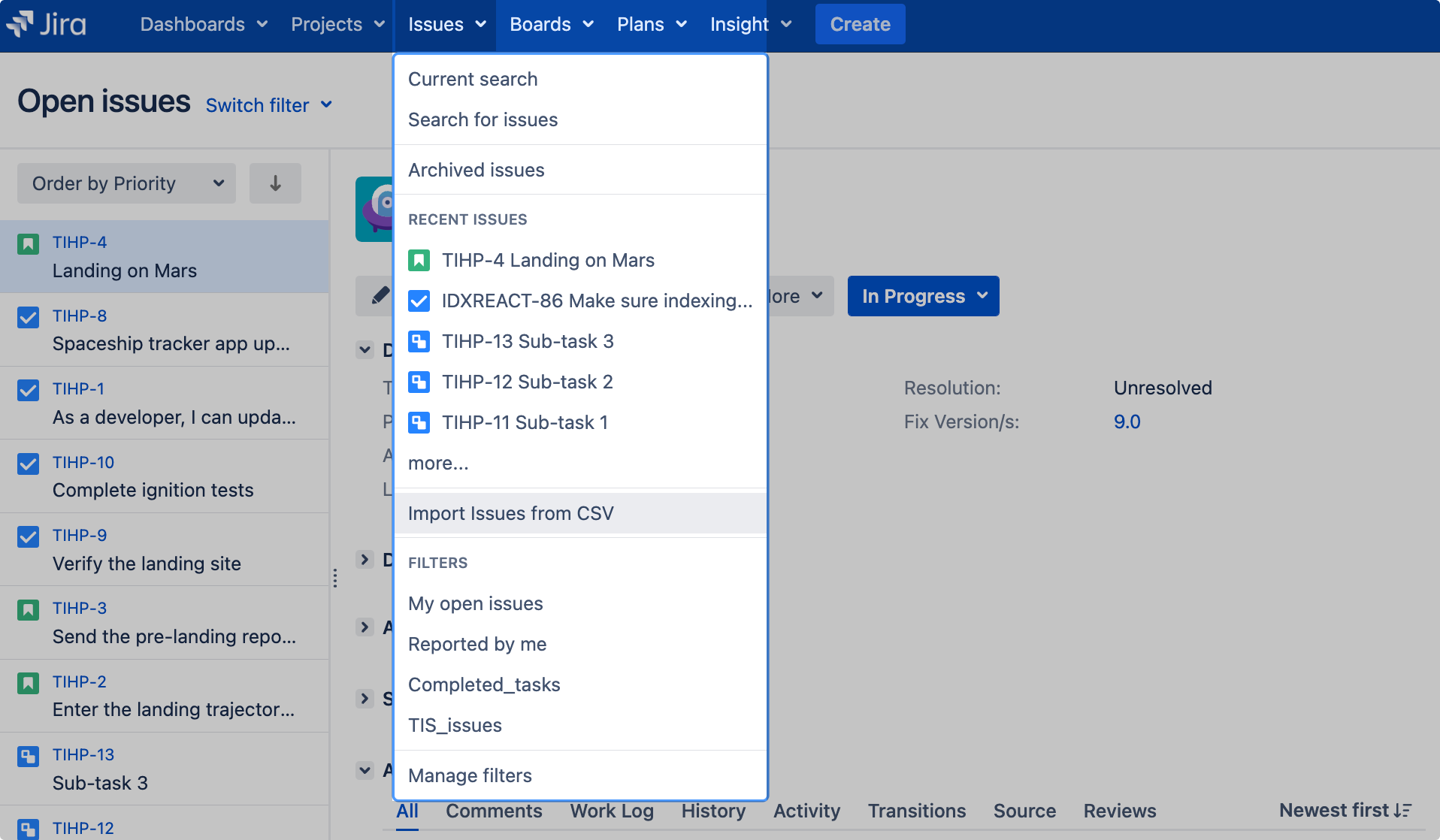
- インポートする CSV ファイルを選択します。
- 設定ファイルがない、または新しい設定ファイルを作成する場合は、[既存の設定ファイルを使用] チェックボックスを空のままにします。この場合、Jira はそれ以降のインポートに使用できる設定ファイルを作成します。このチェックボックスをチェックした場合は、既存の設定ファイルをアップロードする必要があります。
- [次へ] ボタンを選択します。
- フィールドに入力します。課題をインポートするプロジェクト、ファイル エンコード タイプ、区切り文字、日付形式を選択します。CSV ファイルで別の区切り文字が使用されている場合は、文字を [区切り文字] フィールドでカンマの代わりに指定します。区切り文字がタブの場合は、/t として指定します。
- [次へ] ボタンを選択します。
CSV ファイルのフィールドを、選択したプロジェクトの課題フィールドにマッピングします。CSV ファイルにある特定のフィールド値を特定の Jira フィールド値にマッピングする場合は、[フィールド値をマッピング] チェックボックスを選択します。
それぞれの Jira 課題に要約が必要なため、CSV ファイルの少なくとも 1 つのフィールドを Jira の "要約" フィールドにマッピングする必要があります。マッピング用の Jira フィールドである "4 番目の課題" ではなく、"このフィールドをマッピングしない" というメモが表示される場合は、Jira が CSV ファイルからフィールドに対して適切なマッピングを提供できないことを意味します。この問題を解決するには「Jira で CSV によって課題をインポートする際にマッピングするフィールドがない」をご参照ください。
[次へ] ボタンを選択します。
一部のフィールドで [フィールド値のマッピング] チェックボックスをチェックした場合は、CSV ファイルのこれらのフィールド値から対応する Jira 課題フィールドの特定の値にマッピングする必要があります。たとえば、CSV フィールド値「機能リクエスト」は Jira 課題タイプのフィールド値「新機能」にマッピングすることお勧めします。
インポートの実行前に設定にエラーや警告がないかを確認する場合は、[検証] を選択します。必要に応じて、検証の詳細なログをダウンロードできます。
必要に応じて、後で使用できるように設定を保存します。たとえば、次回のインポートでも同じフィールドまたは値のマッピングを使用することをお勧めします。
設定に問題がないことを確認してから [インポートを開始] を選択します。
これで課題が Jira に正常に一括インポートされました。質問や問題がある場合はアトラシアン サポートにお問い合わせください。Jira 管理者の場合は、不整合やエラーを避けるために外部システム インポートのご利用をお勧めします。