コンテンツ インデックス管理
検索インデックスは、検索、ダッシュボード、一部のマクロなど、Confluence サイト内のコンテンツに関する情報を表示するすべての場所で使用されます。検索インデックスは、次のもので構成されています。
- ページのテキスト、ブログ投稿、コメントなどのコンテンツを含むコンテンツ インデックス
- ページが最後に編集された日時など、各変更に関するデータを含む変更インデックス
これらのインデックスは、ユーザーがサイトで作業を完了すると自動的に更新されます。新しいページ、コメント、既存のページの編集などの変更は、各インデックスで即座に更新されるわけではありません。キューに入れられ、定期的にバッチで処理されます (5 秒に 1 回の頻度)。
インデックス キューの表示
短期間にサイトに多数の変更を加えた場合、キューの処理に時間がかかる場合があります。
キューの内容を確認するには、次の手順を実行します。
 > [一般設定] > [コンテンツ インデックス] に移動します。
> [一般設定] > [コンテンツ インデックス] に移動します。 - [Content queue (コンテンツ キュー)] タブまたは [Change queue (キューの変更)] タブを選択します。
ここでは、キューに入っているアイテムの数、キューが最後に処理された時間、処理にかかった時間を見ることができます。この情報は、ユーザーが検索、ダッシュボードのアクティビティ フィードに関する問題を報告した場合のトラブルシューティングに役立ちます。
検索インデックスの再構築
ユーザーが検索、ダッシュボード、アクティビティ フィードを伴う課題をレポートした場合や、アップグレードの一部として求められた場合など、サイトの再インデックスが必要になる場合があります。
検索インデックスの再構築手順
- > [一般設定] > [コンテンツ インデックス] に移動します。
- [再構築] を選択し、プロンプトに従ってインデックスの再構築を確認します。
これにより、コンテンツ インデックスと変更インデックスが再構築され、非常に大規模なサイトでは時間がかかることがあります。
スクリーンショット: インデックスが最後に再構築された時間に関する情報を示す [コンテンツ インデックス] 画面。
![[コンテンツ インデックス] 画面。[再構築] ボタン、インデックスが最後に再構築された日付と、所要時間の 43 分を示す表が表示されている。](https://confluence.atlassian.com/conf714/files/1087525528/1087525529/1/1633995031939/reindex-single-node.png)
検索インデックスをクラスターに伝播する
クラスターで Confluence を実行している場合、インデックスが現在のノードで再構築されると、そのクラスターの他のノードにインデックス ファイルが自動的に伝播されます。
スクリーンショット: クラスター内の各ノードへのインデックスの伝播の進捗状況を示す [コンテンツ インデックス] 画面。
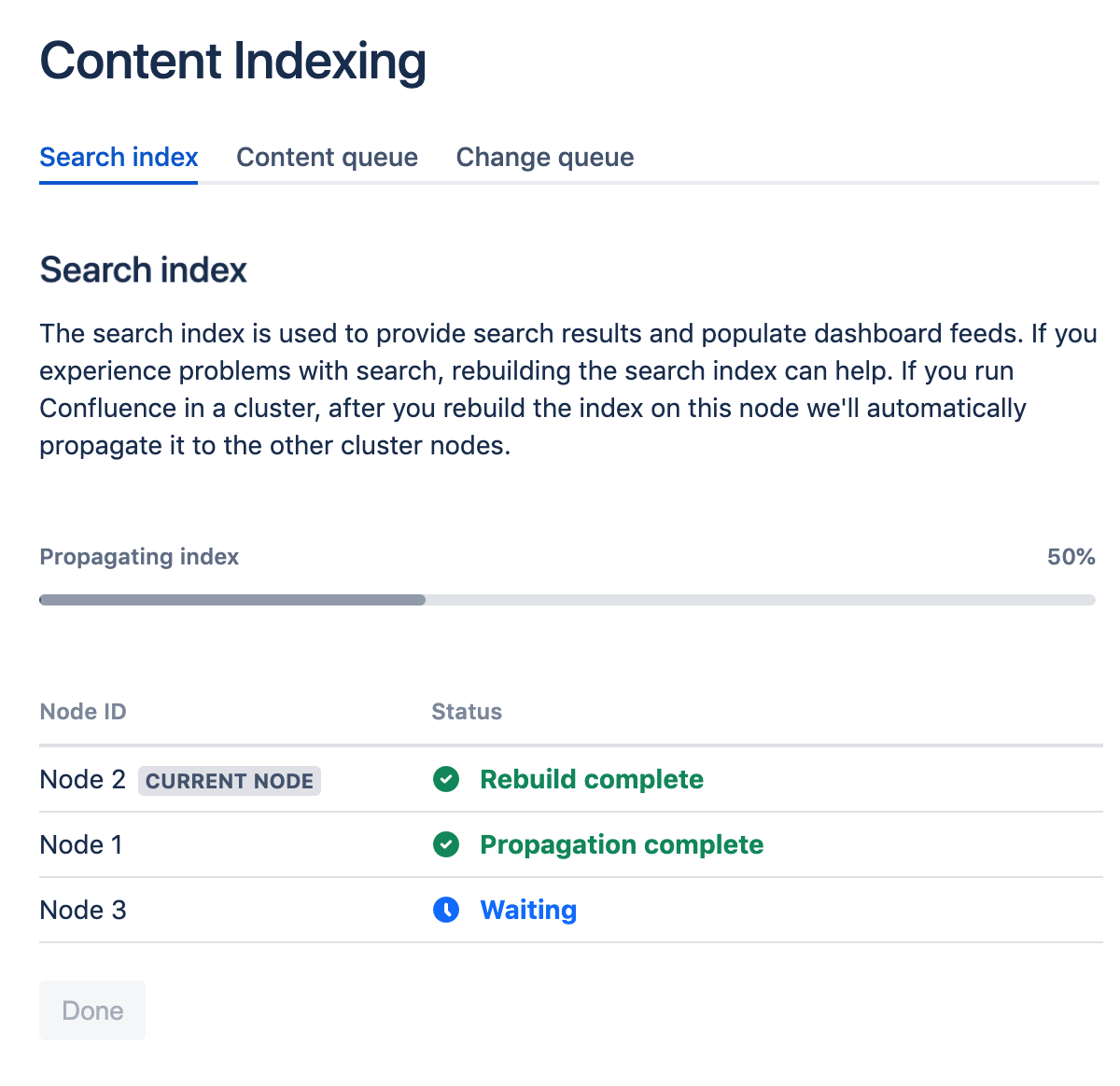
インデックス ファイルはクラスターに結合したノードにのみ伝播されます。Confluence がノードで実行されていない場合、インデックスはノードに伝播できません。
問題が発生した場合は、原因の情報 (ノードが利用できない、インデックスをコピーできるだけのディスク容量がないなど) とともにエラーが表示されます。
エンド ユーザーへの影響
Confluence は、新しいインデックスの構築が完了するまで、既存のインデックスを使用します。ユーザーは引き続き Confluence を使用できますが、パフォーマンスが低下する場合があります。インデックスの再構築によりサーバーに大きな負荷がかかるためです。
インデックスの再構築には、数時間かかる場合があります。所要時間は、サイトのページや添付ファイルの数、種類、およびサイズ、割り当てられたメモリ量、ディスクのスループットによって異なります。
大規模なサイトがある場合、ユーザーへの影響を軽減する方法がいくつかあります。
- Confluence を 1 つのノードで実行している場合は、再構築の開始を週末または予定メンテナンスの時間枠内にします。
- Confluence をクラスターで実行している場合は、インデックスの再構築を行っているノードを、ロード バランサーから削除します。伝播が完了した後に、プールにノードをもう一度追加できます。
ディスク容量の要件
インデックスの完全なコピーを 2 つ、一時的に格納するためには、ホーム ディレクトリ (クラスターで Confluence を実行している場合はローカル ホーム ディレクトリ) に十分な空きディスク容量が必要です。これは、既存のインデックスは、新しいインデックスが利用可能になるまで削除されないことによります。
Confluence をクラスターで実行している場合、追加のインデックス スナップショットを格納するために、共有ホーム ディレクトリに十分な空き容量が必要です。
検索インデックスの場所
Confluence インデックスは <home-directory>/index ディレクトリにあります。
Confluence をクラスターで実行している場合、Confluence インデックスの完全なコピーは各 Confluence ノードの <local-home>/index ディレクトリに格納されます。ジャーナル サービスが各インデックスの同期状態を保持します。
何らかの事情により検索インデックスの内容を確認する必要がある場合は、インデックスを直接確認できるツールがあります。「Confluence Server および Data Center の検索インデックスの内容を表示する方法」を参照してください。
クラスターのインデックス復元
クラスターで Confluence を実行する場合は、検索インデックスのスナップショットが共有ホーム ディレクトリにも保存されます。これらのスナップショットは、既定では 1 日 1 回実行する、Clean Journal Entries スケジュール ジョブで作成されます。
新しいノードを起動すると、Confluence は、インデックスが最新のものかチェックします。そうでない場合、共有ホームディレクトリから、復元スナップショットを要求します。スナップショットを利用できない場合は、実行しているノード (マッチング ビルド番号付き) からスナップショットを生成します。回復スナップショットがインデックス ディレクトリに展開されると、Confluence はスナップショット プロセスを続行します。その後、ジャーナル サービスによって、インデックスを最新の状態にするために必要な追加の更新が行われます。
スナップショットが生成されない場合、あるいは時間内に受信されない場合は、既存のインデックス ファイルは削除され、Confluence はそのノードで再インデックスを実行します。インデックスが非常に大きい場合や、ファイル システムの速度が遅い場合、confluence.cluster.index.recovery.generation.timeout システム プロパティを使用して、Confluence がスナップショットを待機する時間を増やす必要がある場合があります。
インデックス復元はノードの起動時にのみ行われます。そのため、特定のクラスタ ノードのインデックスに問題が疑われる場合、ソノノードを再起動してインデックス復元をトリガーします。
インデックスを UI から手動で再構築する場合、インデックスの復元スナップショットは使用されません。再構築プロセスにおいて、クラスターの他のノードへの伝搬前に新規のスナップショットが生成されます。
トラブルシューティング
検索インデックスの再構築で問題が発生する場合は、以下を参照してください。
インデックスを再構築できない
Confluence UI からインデックスを再構築できない場合や、インデックスを再構築しても検索に問題がある場合は、インデックスの一からの再構築が必要となる場合があります。これを行う方法は、Confluence がクラスターで実行されているかどうかによって異なります
コンテンツのインデックス作成ページにアクセスできない
コンテンツのインデックス作成ページが正しくロードされず、「インデックスの状態を確認できません。接続が切断されている可能性があるため、ページを更新してもう一度お試しください」というエラーが表示される場合、ブラウザを最新バージョンに更新してみてください。
インデックス再構築中のパフォーマンス低下
インデックスの再構築中に安定性の問題が発生した場合は、Confluence がインデックスの再構築に使用するスレッドの数を減らすことができます。reindex.thread.count システム プロパティを設定して、使用できるスレッドの最大数を定義します。
reindex.thread.count と index.queue.thread.count の両方が設定されていない場合、インデックス再作成のスレッド数がその Confluence サーバー上の CPU 数に既定で設定されます。
インデックス再構築中のメモリ不足エラー
インデックスの再構築中にメモリ不足のエラーが発生する場合、Confluence で利用可能なヒープ メモリを増やすことで改善できる可能性があります。「Fix java.lang.OutOfMemoryError in Confluence (Confluence で java.lang.OutOfMemoryError を修正する)」をご覧ください。
インデックスの再構築がクラスターの他のノードに伝播できない
これは通常、各ノードのローカル ホーム ディレクトリにインデックスのコピーを 2 つ格納できるだけの空きディスク容量がない場合に起こります。伝播を再度行う方法については、「 Confluence Data Center 7.7 以降でインデックスの伝播に失敗した場合」を参照してください。