Bitbucket Server の拡張
This page discusses performance and hardware considerations when using Bitbucket Server.
Note that Bitbucket Data Center resources, not discussed on this page, uses a cluster of Bitbucket Server nodes to provide Active/Active failover, and is the deployment option of choice for larger enterprises that require high availability and performance at scale.
ハードウェア要件
The type of hardware you require to run Bitbucket Server depends on a number of factors:
- The count and concurrency of clone operations, which are the most resource-intensive operation Bitbucket Server performs. One major source of clone operations is continuous integration. When your CI builds involve multiple parallel stages, Bitbucket Server will be asked to perform multiple clones concurrently, putting significant load on your system.
- The size of your repositories. There are many operations in Bitbucket Server that require more CPU, memory and I/O when working with very large repositories. Furthermore, huge Git repositories (larger than a few GBs) are likely to impact the performance of Git clients as well as Bitbucket Server.
- ユーザーの数。
Here are some rough guidelines for choosing your hardware:
- Estimate the number of concurrent clones that are expected to happen regularly (look at continuous integration). Add one CPU for every 2 concurrent clone operations.
- Estimate or calculate the average repository size and allocate 1.5 x number of concurrent clone operations x min(repository size, 700MB) of memory.
If you’re running Bitbucket Data Center, check your size using the Bitbucket Data Center load profiles. If your instance is Large or XLarge, take a look at our infrastructure recommendations for Bitbucket Data Center AWS deployments.
See Scaling Bitbucket Server for Continuous Integration performance for some additional information about how Bitbucket Server's SCM cache can help the system scale.
Understanding Bitbucket Server's resource usage
Most of the things you do in Bitbucket Server involve both the Bitbucket Server instance and one or more Git processes. For instance, when you view a file in the web application, Bitbucket Server processes the incoming request, performs permission checks, creates a Git process to retrieve the file contents and formats the resulting webpage. The same is true for the 'hosting' operations like pushing commits, cloning a repository, or fetching the latest changes.
As a result, when configuring Bitbucket Server for performance, CPU and memory consumption for both Bitbucket Server and Git should be taken into account.

CPU
In Bitbucket Server, much of the heavy lifting is delegated to Git. As a result, when deciding on the required hardware to run Bitbucket Server, the CPU usage of the Git processes is the most important factor to consider. Cloning repositories is the most CPU intensive Git operation. When you clone a repository, Git on the server side will create a pack file (a compressed file containing all the commits and file versions in the repository) that is sent to the client. Git can use multiple CPUs while compressing objects to generate a pack, resulting in spikes of very high CPU usage. Other phases of the cloning process are single-threaded and will, at most, max out a single CPU.
Encryption (either SSH or HTTPS) may impose a significant CPU overhead if enabled. As for whether SSH or HTTPS should be preferred, there's no clear winner. Each has advantages and disadvantages as described in the following table:
| http | HTTPS | ssh | |
|---|---|---|---|
| Encryption | No CPU overhead for encryption, but plain-text transfer and basic authentication may be unacceptable for security. | Encryption has CPU overhead, but this can be offloaded to a separate proxy server (if the SSL/TLS is terminated there). | Encryption has CPU overhead. |
| 認証 | Authentication is slower – it requires remote authentication with the LDAP or Crowd server. | Authentication is generally faster, but may still require an LDAP or Crowd request to verify the connecting user is still active. | |
| Cloning | Cloning a repository is slightly slower over HTTP. It requires at least 2 separate requests–and potentially significantly more–each performing its own authentication and permission checks. The extra overhead is typically small, but depends heavily on the latency between client and server. | Cloning a repository takes only a single request. | |
メモリ
When deciding on how much memory to allocate for Bitbucket Server, the most important factor to consider is the amount of memory required for Git. Some Git operations are fairly expensive in terms of memory consumption, most notably the initial push of a large repository to Bitbucket Server and cloning large repositories from Bitbucket Server. For large repositories, it is not uncommon for Git to use hundreds of megabytes, or even multiple gigabytes, of memory during the clone process. The numbers vary from repository to repository, but as a rule of thumb 1.5x the repository size on disk (contents of the .git/objects directory) is a reasonable initial estimate of the required memory for a single clone operation. For large repositories, or repositories that contain large files, memory usage is effectively only bounded by the amount of RAM in the system.
In addition to being the most CPU-intensive, cloning repositories is also the most memory intensive Git operation. Most other Git operations, such as viewing file history, file contents and commit lists are lightweight by comparison. Clone operations also tend to retain their memory for significantly longer than other operations.
Bitbucket Server has been designed to have fairly stable memory usage. Pages that could show large amounts of data (e.g. viewing the source of a multi-megabyte file) perform incremental loading or have hard limits in place to prevent Bitbucket Server from holding on to large amounts of memory at any time. In general, the default memory settings (-Xmx1g) should be sufficient to run Bitbucket Server. Installing third-party apps may increase the system's memory usage. The maximum amount of memory available to Bitbucket Server can be configured in _start-webapp.sh.
The memory consumption of Git is not managed by the memory settings in _start-webapp.sh. Git processes are executed outside the Java virtual machine, so JVM memory settings do not apply.
Allocating a large heap for Bitbucket Server's JVM may constrain the amount of memory available for Git processes, which may result in poor performance. A heap of 1-2GB is generally sufficient for Bitbucket Server's JVM.
ディスク
Git repository data is stored entirely on the filesystem. Storage with low latency/high IOPS will result in significantly better repository performance, which translates to faster overall performance and improved scaling. Storage with high latency is generally unsuitable for Git operations, even if it can provide high throughput, and will result in poor repository performance. Filesystems like Amazon EFS are not recommended for Bitbucket Server's home or shared home due to their high latency.
Available disk space in $BITBUCKET_HOME/caches, where Bitbucket Server’s SCM cache stores packs to allow them to be reused to serve subsequent clones, is also important for scaling. The SCM cache allows Bitbucket Server to trade increased disk usage for reduced CPU and memory usage, since streaming a previously-built pack uses almost no resources compared to creating a pack. When possible, $BITBUCKET_HOME/caches should have a similar amount of total disk space to $BITBUCKET_HOME/shared/data/repositories, where the Git repositories are stored.
ネットワーク
Cloning a Git repository, by default, includes the entire history. As a result, Git repositories can become quite large, especially if they’re used to track binary files, and serving clones can use a significant amount of network bandwidth.
There’s no fixed bandwidth threshold we can document for the system since it will depend heavily on things like; repository size, how heavy CI (Bamboo, Jenkins, etc.) load is, and more. However, it’s worth calling out that Bitbucket Server’s network usage will likely far exceed other Atlassian products like Jira or Confluence.
Additionally, when configuring a Data Center cluster, because repository data must be stored on a shared home which is mounted via NFS, Bitbucket Data Center's bandwidth needs are even higher -and its performance is far more sensitive to network latency. Ideally, in a Data Center installation, nodes would use separate NICs and networks for client-facing requests (like hosting) and NFS access to prevent either from starving the other. The NFS network configuration should be as low latency as possible, which excludes using technologies like Amazon EFS.
データベース
The size of the database required for Bitbucket Server primarily depends on the number of repositories the system is hosting and the number of commits in those repositories.
A very rough guideline is: 100 + ((total number of commits across all repositories) / 2500) MB.
So, for example, for 20 repositories with an average of 25,000 commits each, the database would need 100 + (20 * 25,000 / 2500) = 300MB.
Note that repository data is not stored in the database; it’s stored on the filesystem. As a result, having multi-gigabyte repositories does not necessarily mean the system will use dramatically more database space.
Where possible, it is preferable to have Bitbucket Server’s database on a separate machine or VM, so the two are not competing for CPU, memory and disk I/O.
Clones examined
Since cloning a repository is the most demanding operation in terms of CPU and memory, it is worthwhile analyzing the clone operation a bit closer. The following graphs show the CPU and memory usage of a clone of a 220 MB repository:
| Git process (blue line)
Bitbucket Server (red line)
|
| Git process (blue line)
Bitbucket Server (red line)
|
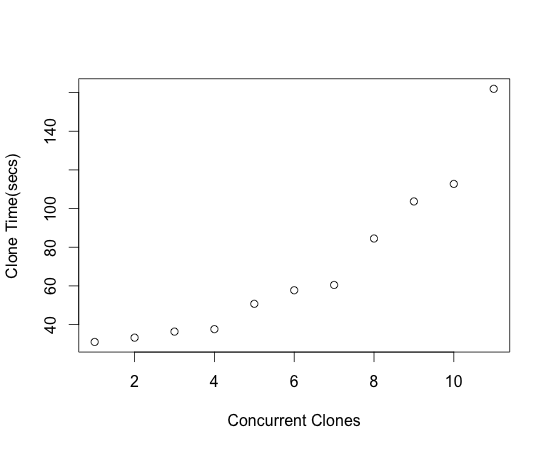
| This graph shows how concurrency affects average response times for clones:
The measurements for this graph were done on a 4 CPU server with 12 GB of memory. Response times become exponentially worse as the number of concurrent clone operations exceed the number of CPUs. |


監視
In order to effectively diagnose performance issues and tune Bitbucket Server’s scaling settings, it is important to configure monitoring. While exactly how to set up monitoring is beyond the scope of this page, there are some guidelines that may be useful:
At a minimum, monitoring should include data about CPU, memory, disk I/O (for any disks where Bitbucket Server is storing data), free disk space, and network I/O
Monitoring free disk space can be very important for detecting when the SCM cache is nearing free space limits, which could result in it being automatically disabled
When Bitbucket Server is used to host large repositories, it can consume a large amount of network bandwidth. If repositories are stored on NFS, for a Data Center cluster, bandwidth requirements are even higher
Bitbucket Server exposes many JMX counters which may be useful for assembling dashboards to monitor overall system performance and utilization
- In particular, tracking used/free tickets for the various buckets, described below, can be very useful for detecting unusual or escalating load
Retaining historical data for monitoring can be very useful for helping to track increases in resource usage over time as well as detecting significant shifts in performance
As users create more repositories, push more commits, open more pull requests and generally just use the system, resource utilization will increase over time
Historical averages can be useful in determining when the system is approaching a point where additional hardware may be required or, for Data Center installations, when it may be time to consider adding another cluster node
Tickets and throttling
Bitbucket Server uses a ticket-based approach to throttling requests. The system uses a limited number of different ticket buckets to throttle different types of requests independently, meaning one request type may be at or near its limit, while another type still has free capacity.
Each ticket bucket has a default size that will be sufficient in many systems, but as usage grows, the sizes may need to be tuned. In addition to a default size, each bucket has a default timeout which defines the longest a client request is allowed to wait to acquire a ticket before the request is rejected. Rejecting requests under heavy load helps prevent cascading failures, like running out of Tomcat request threads because too many requests are waiting for tickets.
Ticket buckets
The following table shows ticket buckets the system uses, the default size and acquisition timeout, and what each is used for:
| バケット | サイズ | タイムアウト | 用途 |
|---|---|---|---|
| scm-command | 50 (Fixed) | 2秒 | “scm-command” is used to throttle most of the day-to-day Git commands the system runs. For example:
“scm-command” tickets are typically directly connected to web UI and REST requests, and generally have very quick turnaround - most commands typically complete in tens to hundreds of milliseconds. Because a user is typically waiting, “scm-command” tickets apply a very short timeout in order to favor showing users an error over displaying spinners for extended periods. |
| scm-hosting | 1x-4x (Adaptive; see below) | 5 分 | “scm-hosting” is used to throttle For SSH only, “scm-hosting” is also used to throttle “scm-hosting” uses an adaptive throttling mechanism (described in detail below) which allows the system to dynamically adjust the number of available tickets in response to system load. The default range is proportional to a configurable scaling factor, which defaults to the number of CPUs reported by the JVM. For example, if the JVM reports 8 CPUs, the system will default to 1x8=8 tickets minimum and 4x8=32 tickets maximum. |
| scm-refs | 8x (Fixed proportional) | 1 分 | “scm-refs” is used to throttle ref advertisements, which are the first step in the process of servicing both pushes and pulls. Additionally, because most of the CPU and memory load are client side, pushes are throttled using the “scm-refs” bucket. Unlike a clone or a fetch, the pack for a push is generated using the client’s CPU, memory and I/O. While processing the received pack does produce load on the server side, it’s minimal compared to generating a pack for a clone or fetch. The default size for the “scm-refs” bucket is proportional to a configurable scaling factor, which defaults to the number of CPUs reported by the JVM. For example, if the JVM reports 8 CPUs, the system will default to 8x8=64 “scm-refs” tickets. Ref advertisements are generally served fairly quickly, even for repositories with large numbers of refs, so the default timeout for “scm-refs” is shorter than the default for “scm-hosting”. |
| git-lfs | 80 (Fixed) | Immediate | “git-lfs” is used to throttle requests for large objects using Git LFS. LFS requests are much more similar to a basic file download than a pack request, and produce little system load. The primary reason they’re throttled at all is to prevent large numbers of concurrent LFS requests from consuming all of Tomcat's limited HTTP request threads, thereby blocking access to users trying to browse the web UI, or make REST or hosting operations. Because LFS is predominantly used for large objects, the amount of time a single LFS ticket may be held can vary widely. Since it’s hard to make a reasonable guess about when a ticket might become available, requests for “git-lfs” tickets timeout immediately when the available tickets are all in use. |
| mirror-hosting | 2x (Fixed proportional) | 1 時間 | "mirror-hosting" is Data Center-only and is used to throttle Unlike "scm-hosting", "mirror-hosting" is not adaptive. It uses a fixed number of tickets based on the number of CPUs reported by the JVM. For example, if the JVM reports 8 CPUs, the system will default to 2x8=16 "mirror-hosting" tickets. The default limit is generally sufficient, but for instances with a large number of mirrors, or large mirror farms, it may be necessary to increase it. Administrators will need to balance the number of "mirror-hosting" tickets they allow against the number of "scm-hosting" tickets they allow to prevent excessive combined load between the two. |
以前のバージョン
Prior to Bitbucket Server 7.3, "scm-hosting" tickets were used to throttle all parts of hosting operations, including ref advertisements and pushes. This meant that the "scm-hosting" bucket often needed to be sized very generously to prevent fast-completing ref advertisements from getting blocked behind slow-running clones or fetches when competing for tickets. However, when the "scm-hosting" limit was very high, if a large number of clone or fetch requests were initiated concurrently, it could result in a load spike that effectively crippled or even crashed the server. "scm-refs" tickets were introduced to combat that risk. With "scm-refs", administrators can configure the system to allow for heavy polling load (typically from CI servers like Bamboo or Jenkins) without necessarily increasing the number of available "scm-hosting" tickets.
Adaptive throttling
Adaptive throttling uses a combination of total physical memory, evaluated once during startup, and CPU load, evaluated periodically while the system is running, to dynamically adjust the number of available "scm-hosting" tickets within a configurable range.
During startup, the total physical memory on the machine is used to determine the maximum number of tickets the machine can safely support. This is done by considering how much memory Bitbucket Server and the bundled search server need for their JVMs and an estimate of how much memory each Git hosting operation consumes on average while running, and may produce a safe upper bound that is lower (but never higher) than the configured upper bound.
To illustrate this more concretely, consider a system with 8 CPU cores and 8GB of physical RAM. With 8 CPU cores, the default adaptive range will be 8-32 tickets.
- The total is reduced by 1GB for Bitbucket Server's default heap: 7GB
- The total is reduced by 512MB for bundled search: 6.5GB
- The remainder is divided by 256MB: 6656 / 256 = 26
In this example, the actual upper bound for the adaptive range will be 26 tickets, rather than the 32 calculated from CPU cores, because the system doesn't have enough RAM to safely handle 32 tickets.
While the system is running, Bitbucket Server periodically samples CPU usage (every 5 seconds by default) and increases or decreases the number of available tickets based on a target load threshold (75% by default). A smoothing factor is applied to CPU measurements so the system doesn't overreact by raising or lowering the number of available tickets too aggressively in response to bursty load.
Adaptive throttling is enabled by default, but the system may automatically revert to fixed throttling if any of the following conditions are met:
- A non-default fixed number of tickets has been set; for example
throttle.resource.scm-hosting=25 - A fixed throttling strategy is configured explicitly; for example
throttle.resource.scm-hosting.strategy=fixedthrottle.resource.scm-hosting.fixed.limit=25 - The adaptive throttling configuration is invalid in same way
- The total physical memory on the machine is so limited that even the minimum number of tickets is considered unsafe
Adaptive throttling is only available for the "scm-hosting" ticket bucket. Other buckets, like "scm-refs", do not support adaptive throttling; they use fixed limits for the number of tickets. This prevents high CPU usage from git clone and git fetch requests from reducing the number of tickets available in other buckets, which generally don't use much CPU.
キャッシング
Building pack files to serve clone requests is one of the most resource-intensive operations Bitbucket Server performs, consuming significant amounts of CPU, memory and disk I/O. To reduce load, and allow instances to service more requests, Bitbucket Server can cache packs between requests so they only need to be built once. When a pack is served from the cache, no "scm-hosting" ticket is used. This can be particularly beneficial for systems with heavy continuous integration (CI) load, from systems like Bamboo or Jenkins, where a given repository may be cloned several times either concurrently or in short succession.
Cached packs are stored in $BITBUCKET_HOME/caches/scm, with individual subdirectories for each repository. On Data Center nodes, packs are cached per node and are not shared. If free space on the disk where $BITBUCKET_HOME/caches/scm is stored falls below a configurable threshold, pack file caching will be automatically disabled until free space increases. Cached packs will automatically be evicted using a least-recently-used (LRU) strategy to try and free up space when free space approaches the threshold.
Considerations
- Because clones typically include the full history for the repository, cached packs are often close to the same size as the repository being cloned. This means cached packs can consume a significant amount of disk space–often more than the repository itself consumes if multiple packs are cached
- It may be desirable to use a separate disk or partition mounted at
$BITBUCKET_HOME/cachesto allow for more disk space and to ensure cached packs don't fill up the same disk where other system data is stored
- It may be desirable to use a separate disk or partition mounted at
- Using single-branch clones (e.g.
git clone --single-branch) can result in a large number of distinct cached packs for a single repository. In general, for maximizing cache hits, it's better to use full clones
制限事項
Pack files for
git fetchrequests are not cached. Unlike clones, where it's likely the same clone will be executed multiple times, fetches tend to be much more unique and are unlikely to produce many cache hits
以前のバージョン
Prior to Bitbucket 7.4 the system supported caching ref advertisements as well as packs. Unlike pack file caching, enabling ref advertisement caching did little to reduce system load. Instead, the primary benefit of ref advertisement caching was reduced contention for "scm-hosting" tickets. Ref advertisement caching was disabled by default because it could result in advertising stale refs. This meant administrators had to balance the risk of stale data against the reduction in "scm-hosting" ticket usage.
Bitbucket Server 7.3 introduced a new "scm-refs" bucket for throttling ref advertisements, eliminating contention for "scm-hosting" tickets, and Bitbucket Server 7.4 introduced significant reductions in the number of threads used to service HTTP and SSH hosting operations. The combination of those improvements eliminate the benefits of ref advertisement caching, leaving only its downsides, so support for ref advertisement caching has been removed.
HTTPS and SSH
Bitbucket Server can serve hosting operations via HTTPS and SSH protocols. Each has its pros and cons, and it's possible to disable serving hosting operations via either protocol if desired.
HTTPS
Serving hosting operations via HTTPS requires 2 or more requests to complete the overall operation. By default Git will attempt to reuse the same connection for subsequent requests, to reduce overhead, but it's not always possible to do so. Additionally, Git does not support upload-archive over HTTP(S); it's only available over SSH. One advantage of HTTPS for hosting is that encryption overhead can be offloaded to a proxy to reduce CPU load on the Bitbucket Server instance.
Git's HTTPS support offers 2 wire protocols, referred to as "smart" and "dumb". Bitbucket Server only supports the "smart" wire protocol, which has 2 versions: v0 and v2 (v1 was a transitional protocol and is not generally used). The v0 "smart" wire protocol is always supported; v2 is only supported when Git 2.18+ is installed on both Bitbucket Server and on clients.
By default, Tomcat allows up to 200 threads to process incoming requests. Bitbucket Server 7.4 introduced the use of asynchronous requests to move processing for hosting operations to a background threadpool, freeing up Tomcat's threads to handle other requests (like web UI or REST requests). The background threadpool allows 250 threads by default. If the background threadpool is fully utilized, subsequent HTTPS hosting operations are handled directly on Tomcat's threads. When all 200 Tomcat threads are in use, a small number of additional requests are allowed to queue (50 by default) before subsequent requests are rejected.
ssh
Hosting operations via SSH are handled using a single request, with bidirectional communication between the client and server. SSH supports the full range of hosting operations: receive-pack (push), upload-archive (archive) and upload-pack (pull). One disadvantage of SSH is that its encryption overhead cannot be offloaded to a proxy; it must be handled by the Bitbucket Server JVM.
Git's SSH support only offers a single wire protocol, which is roughly equivalent to HTTPS's "smart" wire protocol. As with the HTTPS "smart" wire protocol, Git's SSH wire protocol supports 2 versions: v0 and v2. The v0 wire protocol is always supported; v2 is only supported when Git 2.18+ is installed on both Bitbucket Server and on clients.
By default, Bitbucket Server allows up to 250 simultaneous SSH sessions, and sessions over that limit are rejected to prevent backlogs.
以前のバージョン
Prior to Bitbucket Server 7.4, hosting operations via HTTPS and SSH used 5 threads per request. One of these was the actual HTTPS or SSH request thread, and the rest were overhead related to using blocking I/O to communicate with the git process that was servicing the request. In Bitbucket Server 7.4, that blocking I/O approach was replaced with a non-blocking approach which eliminated the 4 overhead threads, allowing HTTPS and SSH hosting operations to be serviced by a single thread.
Configuring Bitbucket Server scaling options and system properties
The sizes and timeouts for the various ticket buckets are all configurable; see Configuration properties.
When the configured limit is reached for the given resource, requests will wait until a currently running request has completed. If no request completes within a configurable timeout, the request will be rejected. When requests while accessing the Bitbucket Server UI are rejected, users will see either a 501 error page indicating the server is under load, or a popup indicating part of the current page failed to load. When Git client 'hosting' commands (pull/push/clone) are rejected, Bitbucket Server does a number of things:
Bitbucket Server will return an error message to the client which the user will see on the command line: "Bitbucket is currently under heavy load and is not able to service your request. Please wait briefly and try your request again."
A warning message will be logged for every time a request is rejected due to the resource limits, using the following format:
"A [scm-hosting] ticket could not be acquired (0/12)"The ticket bucket is shown in brackets, and may be any of the available buckets (e.g. “scm-command”, “scm-hosting”, “scm-refs” or “git-lfs”)
For five minutes after a request is rejected, Bitbucket Server will display a red banner in the UI for all users to warn that the server is under load.
This period is also configurable.
The hard, machine-level limits throttling is intended to prevent hitting are very OS- and hardware-dependent, so you may need to tune the configured limits for your instance of Bitbucket Server. When hyperthreading is enabled for the server CPU, for example, the default number of “scm-hosting” and “scm-refs” tickets may be too high, since the JVM will report double the number of physical CPU cores. In such cases, we recommend starting off with a less aggressive value; the value can be increased later if hosting operations begin to back up and system monitoring shows CPU, memory and I/O still have headroom.