グローバル Jira 設定の構成
アセットのグローバル Jira 設定には、オブジェクト スキーム、オブジェクト タイプ、あるいはオブジェクトではなく、アセット アプリ自体の設定が含まれます。ここでは、ログ設定、日時、アセットのインデックス再作成などを設定できます。利用できる設定の詳細については、次をご覧ください。
グローバル Jira 設定にアクセス
アセットのグローバル Jira 設定にアクセスするには、次の手順に従います。
- [管理] > [アプリを管理] の順に移動します。
- [アセット] セクションでページを探します。
一般設定
一般設定を開くには [アセット設定] を選択します。

| 設定 | 説明 | |
|---|---|---|
| ユーザー相互作用 | ||
属性の既定ラベル | すべてのオブジェクト タイプの既定のラベルとして使用されるテキスト タイプの属性。これは、特定のオブジェクト タイプ設定でも変更できます。 この設定はこの設定の変更後に作成されるオブジェクト タイプにのみ影響することにご注意ください。 | いいえ |
属性の既定の説明 | 既定のラベル属性の説明。これは、特定のオブジェクト タイプ設定でも変更できます。 | いいえ |
[オブジェクトを開く] ダイアログ イベント | ユーザーがオブジェクト リンクを選択、またはユーザーがオブジェクト リンクにカーソルを移動した際に、オブジェクト ダイアログを開くかどうかを決定します。 これは、Jira 課題を表示している際にアセット オブジェクト フィールドを表示する場合にも適用されます。 | いいえ |
カスタム フィールドで取得されるオブジェクトの既定数 | これは、アセットがリクエストごとにカスタム フィールドで取得するオブジェクトの数を示します。既定値は 25 に設定されています。 ユーザーがカスタム フィールドのオブジェクトの検索を開始すると、検索条件に一致するオブジェクトがサーバーから非同期でフェッチされます。したがって、既定の制限である 25 で十分なはずであり、この値が推奨されます。 この数を増やすとリクエストごとにより多くのオブジェクトをフェッチする必要があるため、パフォーマンスに影響します。 | いいえ |
| 一般設定 | ||
アセット監査ログが有効 | このチェックボックスをオンにすると、すべてのアセット オブジェクト イベントが監査ログファイルに記録されます。 | いいえ |
属性値を監査ログに含める | このチェックボックスは、上記の [アセット監査ログが有効] がオンになっている場合にのみ有効になります。 オンにすると、監査ログにあるオブジェクトのすべての属性値が含まれます。 | いいえ |
アセット インデックスをファイルから復元 | これによって、起動時にアセット インデックスがファイルから確実に復元されるため、起動時間の短縮に繋がります。 アセットは起動時にファイルの整合性チェックをデータベースに対して実行して、一致しない場合はインデックスを再作成します。 これをオフにすると起動時間が遅くなる場合がありますが、壊れたインデックス ファイルがデータの不整合を引き起こす可能性があるリスクを排除できます。 初期設定ではオンになっています。ファイルは {$JIRA_HOME/caches/assets_indexes} にあります。 たとえば、MacOS ではファイルのパスは {/var/atlassian/application-data/jira/caches/assets_indexes} になります。 | いいえ |
キャッシュをシャットダウン時に保存 | これは、アセットのインデックスをアセットのシャットダウン時にファイルに保持する必要があることを示します (例: プラグインのアップグレード、Jira の再起動、アセットの無効化など)。 [アセット インデックスをファイルから復元] がオンになっている場合は、このプロパティもオンにすることをお勧めします。 | いいえ |
アセット キャッシュを制限 | これによって、アセットに保存できるオブジェクトの量を制限できます。キャッシュに存在するオブジェクトの数が限られるため、メモリ フットプリントが制限されます。 既定では、アセットを使用する際にキャッシュ内のオブジェクトは制限されず、この方法が推奨されます。制限すると、パフォーマンスに悪影響が及ぼされます。 | はい |
キャッシュに許されるオブジェクトの数 | [アセット キャッシュを制限] がオンになっている場合にのみ有効になります。 このプロパティは、キャッシュに保存されるアセット オブジェクトの数を示します。 推奨される方法は、キャッシュのオブジェクトを制限しないことです。 | はい |
ファイル アップロードの最大サイズ | ファイル、画像、添付ファイルをアセットにアップロードする際の最大サイズ (バイト単位)。 | いいえ |
アセットの並列処理 | アセットが並列タスク (データのインポート、インデックスの再作成など) を実行するために生成するスレッドの数です。 この数値が低い値に設定されている場合はアセットが Jira にかける負担が軽減します。ただし、パフォーマンス速度は低下します。 | いいえ |
インポート中にデータ ソースを一時ファイル経由で処理 | インポート中のメモリ フットプリントを減らす目的でインポート モジュールを使用する際に、データをディスク上で一時的に保存します。 | いいえ |
| カスタム ロケールをアセットに使用 | アセットに保存されているデータを Jira の既定のロケール以外のロケールで並べ替える必要があることを示すために使用されます。 オンにするとオブジェクトのフェッチが遅くなる可能性があるため、パフォーマンスに問題が起こらないように初期設定では無効になっています。 | いいえ |
| アセットのロケール | [カスタム ロケールをアセットに使用] がオンになっている場合にのみ有効になります。 この設定で、アセットがデータを並べ替える際に使用する言語が決まります。 | いいえ |
Service Desk ポータルの検索テキスト (単一) | Jira Service Desk ポータル上にあるアセット フィールドのプレースホルダー (単一フィールド) | |
Service Desk ポータルの検索テキスト (複数) | Jira Service Desk ポータル上にあるアセット フィールドのプレースホルダー (複数フィールド) | |
| スケジュールの専用ノード | このノードはアセットのスケジュール タスク (Importers や Automation など) を実行するための専用ノードになります。 ノードがスケジュールの専用ノードとして選択されてスケジュールされたタスクの実行時に利用できなくなった場合、そのタスクは実行されないことにご注意ください。 | いいえ |
日付の設定
アセットのすべての日付は Jira 管理者設定を使用しています。次の URL で変更できます。
https://host:port/secure/admin/AdvancedApplicationProperties.jspaログ ファイル
ログは次のディレクトリにあります。
<Jira-shared-home>/log添付ファイル
アセットの添付ファイルは、次のディレクトリの avatars、files、icons、objects という名前のサブフォルダーにそれぞれ保存されます。
<Jira_home>/data/attachments/assetsインデックス作成
インデックス設定を開くには [アセットのインデックス化] を選択します。
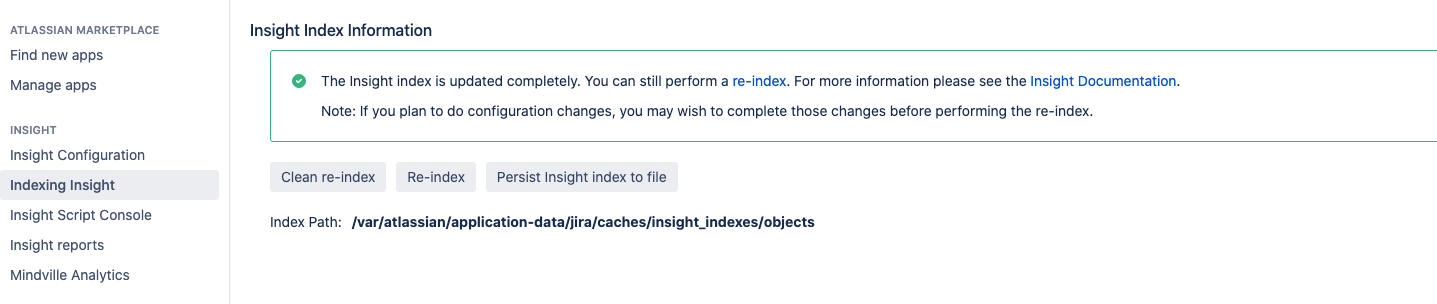
インデックス作成では次のオプションから選択できます。
- Clean re-index
A clean re-index means that all objects will be removed from the index across all nodes, and then will be indexed again. This is recommended if you want to have a fresh state of the index. Once the indexing is in progress, you won't be able to cancel it or search for objects or filter them. - 再インデックス化
この処理ではすべてのオブジェクトをインデックスに残した上で、アセットが再度インデックスを作成します。処理中もオブジェクトを検索できます。 - アセット インデックスをファイルに永続化
ディスク上のインデックスを手動で保持 (コピー) できます。多数のオブジェクトを含む大規模なアセット環境があり、アプリの再インストールを計画している場合に役立ちます。インデックスをディスク上に置いておけば、アセットでゼロから作り直す必要はありません。
Groovy スクリプトのテスト
Groovy スクリプトをテストするには [アセット スクリプト コンソール] を選択します。これによって、アセットの自動化や事後操作で使用する Groovy スクリプトをすばやく簡単にテストできます。

レポートの同期
レポートの同期設定を開くには [アセット レポート] を選択します。ここでは、レポートのデータを同期する cron スケジュールを設定できます。

Analytics
アナリティクスの設定を開くには [Mindville アナリティクス] を選択します。

Data Center に関するその他の設定
clustermessage テーブルのデータ保持期間を設定する
データ保持期間を設定すると、clustermessage テーブルの過負荷に起因するパフォーマンスの問題を回避できます。大量のデータセットを短時間でアセットにインポートすると、clustermessage テーブルに情報が入力されてパフォーマンスの問題が発生する可能性があります。
データ保持期間を設定するには、次の手順に従います。
- [管理] > [システム] の順に移動します。
- [詳細] セクションまで下にスクロールして [サービス] を選択します。
- [サービスを追加] の [クラス] で [Build-in services (組み込みサービス)] を選択します。
- [クラスター メッセージ フラッシュ サービス] を選択します。
- 以下の情報を入力します:
- 名前 - クラスター メッセージ フラッシュ サービス
- クラス - com.atlassian.jira.service.services.cluster.ClusterMessageCleaningService
- スケジュール - 0 0 4/12 * * ?
- [サービスを追加] を選択します。
- [保存期間] に「2880m」と入力します。
- 更新を選択します。
