Disaster recovery guide for Jira
このガイドでは、次の概念についてしばしば言及しています。
- 目標復旧地点 (RPO) - 障害発生後に Jira インスタンスをどの程度最新の状態にする必要があるか。
- 目標復旧時間 (RTO) - 障害発生後にスタンバイ インスタンスをどの程度の時間で利用できるようにする必要があるか。
- 目標復旧コスト (RCO) - ディザスタ リカバリ ソリューションにどの程度の金額をかける意思があるか。
- 高可用性 - 1 つ以上のコンポーネントに障害が発生した場合でも、サービスの稼働時間を最大化するための戦略。Jira の場合、アプリケーションへのアクセスを提供し、許容できる応答時間を提供することを意味します。高可用性計画には通常、同じ場所での自動修正とフェイル オーバーが含まれます。Jira の高可用性ガイドをご確認ください
- ディザスタ リカバリ – メインのデータ センターが利用できなくなる場合 (すなわち災害 (ディザスタ) 発生時) に、(通常、別の地域にある) 別のデータ センターで運用を再開する戦略。(しばしば別の場所への) フェイル オーバーはディザスタ リカバリの基本的な部分です。
- フェイルオーバー - あるマシンが故障した場合に、そのマシンから別のマシンに処理を引き継ぎます。これは同じデータ センター内またはあるデータ センターから別のデータ センターの間で行われます。フェイルオーバーは通常、高可用性計画とディザスタ リカバリ計画の両方に含まれます。
はじめる前に
Jira のディザスタ リカバリ戦略は、主要目標 (目標復旧地点、目標復旧時間、目標復旧コスト)や標準運用手順 (SOP) の設定などの、より広範なビジネス プラクティスについてはカバーしていません。
このガイドでは、「コールド スタンバイ」戦略と呼ばれるディザスタ リカバリを実行する方法について説明しています。この場合、スタンバイ JIRA インスタンスが継続的に実行されていないため、管理者はスタンバイ インスタンスを起動し、組織のビジネス ニーズに対応できる適切な状態になるよう、特定のアクションを実行する必要があります。
以下のテーブルには、ディザスタ リカバリ計画で考慮する必要のある主な要素が含まれています。
| Jira インストール | スタンバイ インスタンスには、本番インスタンスとまったく同じバージョンの Jira が必要です。 |
|---|---|
| データベース | これは Jira の主要な信頼できる情報源であり、ほとんどのアプリケーションのデータを含みますが、添付ファイル、アバター、インストール済みのアプリなどは除きます。 復旧ポイント目標 (RPO)1 を満たすには、データベースを複製し、常に最新の状態に保つ必要があります。 |
| 添付ファイル | すべての課題の添付ファイルは Jira Data Center の Amazon S3 に保存されている添付ファイルは複製されません。Amazon S3 の設定について詳細をご覧ください |
| 検索インデックス | 検索インデックスは主要な信頼できる情報源ではなく、いつでもデータベースから再作成することができます。 大規模なインストールでは、インデックスの再作成にかなりの時間がかかることがあります。このプロセス中、インデックスが完全に回復するまで、Jira の機能が大幅に低下する可能性があります。 Jira Data Center では、この復旧時間を最小限に抑えるためのツールを提供しています。インスタンスで Lucene を使用している場合、インデックスの復旧を有効にすると、すべてのインデックス スナップショットが Jira Data Center の |
| プラグイン | ユーザーがインストールしたアプリは、Jira Data Center の sharedhome に保存されます。それらもまた、スタンバイ インスタンスに複製する必要があります。 |
| その他のデータ | Jira Data Center の sharedhome に保存されているその他の重要でないアイテムも、スタンバイ インスタンスに複製する必要があります。このようなファイルには、ユーザーとプロジェクトのアバター、スクリプトなどのプラグイン リソース、設定ファイル、キャッシュ、インデックスなどが含まれます。 |
クラスタリングの考慮事項
クラスター環境の場合は、次の要因にも注意する必要があります。
単一ノードのクラスター環境の作成を伴う場合でも、ディザスタ リカバリ インスタンスをアクティブ化する前に、クラスタリングを設定する必要があります。クラスタリングを有効化せずに単一ノードのインスタンスを設定しようとすると、機能せず、ディザスタ リカバリの設定が失敗します。
| スタンバイ クラスタ | スタンバイ クラスタの構成は、ライブ クラスタの構成を反映する必要はありません。要件と予算に応じて、含まれるノードが増減しても構いません。ノードが少なくなるとスループットが低下する可能性がありますが、状況によっては許容できます。 スタンバイ クラスタがある場合、スタンバイ ノードのノード ID はライブ クラスタの ID と異なっている必要があります。 |
|---|---|
| ファイルの場所 | Jira Data Center には、次の 2 つのホーム ディレクトリがあります。
|
| スタンバイ クラスタの起動 | 最初にクラスタの 1 つのノードだけを起動することが重要です。追加のノードを起動する前に、検索インデックスが正常に回復するのを待ち、正しく機能していることを確認してください。 |
スタンバイ インスタンスのセットアップ
ステップ 1. Jira をディザスタ リカバリ用にインストールして設定する
- スタンバイ インスタンスに Jira の同じバージョンをインストールします。
- インスタンスを構成してスタンバイ データベースに接続します。データベースへの Jira の接続について詳細をご覧ください
インスタンスをディザスタ リカバリ インストールとするように設定します。これにより、Jira が起動したときに自動インデックス復旧メカニズムが作動します。
スタンバイ インスタンスの Jira ホーム ディレクトリのjira-config.propertiesに、以下を追加します。disaster.recovery=true
スタンバイの Jira インスタンスを起動するとデータベースにデータを書き込むので、起動しないでください
インストールをテストしたい場合は、一時的に別のデータベースに接続し、Jira を起動して、期待どおりに動作することを確認します。テスト後にスタンバイ データベースを参照するようにデータベース設定を更新することを忘れないでください。
ステップ2.データ レプリケーション戦略の実装
スタンバイの場所へのデータのレプリケートは、コールド スタンバイ フェイルオーバー戦略において不可欠です。スタンバイ JIRA インスタンスにフェイルオーバーしたときに、スタンバイのデータが古かったり、インデックスの再作成に長い時間がかかったりする事態は避ける必要があります。
データが失われないように、sharedhomeフォルダの内容全体を複製することをお勧めします。
データベース レプリケーションのセットアップ
以下の Jira がサポートするデータベース サプライヤーは、独自のデータベース レプリケーション ソリューションを提供しています。
組織の目標復旧地点 (RPO)、目標復旧時間 (RTO)、および目標復旧コスト (RCO)1 を満たすデータベース レプリケーション戦略を使用する必要があります。
ファイル レプリケーションのセットアップ
Jira はセカンダリ ロケーションへのファイルのレプリケーションを自動的に管理できます。これには、添付ファイル、アバター、インストール済みアプリが含まれます。Lucene を使用している場合は、インデックス スナップショットも含まれます。
Jira アプリによって追加されたファイルには、他のレプリケーション方法が必要になることを考慮してください。このような場合は、アプリ開発者に連絡して推奨事項を確認する必要があります。
添付ファイルやアバターをAmazon S3 に保存してた場合、それらも複製されません。Amazon S3 の設定について詳細をご覧ください
既定のレプリケーション フォルダは sharedhome/secondary です。場所を変更したい場合は、jira-config.properties ファイル内の目的のパスに jira.secondary.home プロパティを設定してください。クラスタ モードで Jira を実行している場合、セカンダリ ホームはすべてのノードからアクセスできるパスである必要があります。
ファイル レプリケーションを有効にする方法。
画面右上で [管理]
> [システム] を選択します。
[詳細] から [レプリケーション] を選択します。
[ ファイル レプリケーション設定] ページで、[ 設定を編集] を選択します。
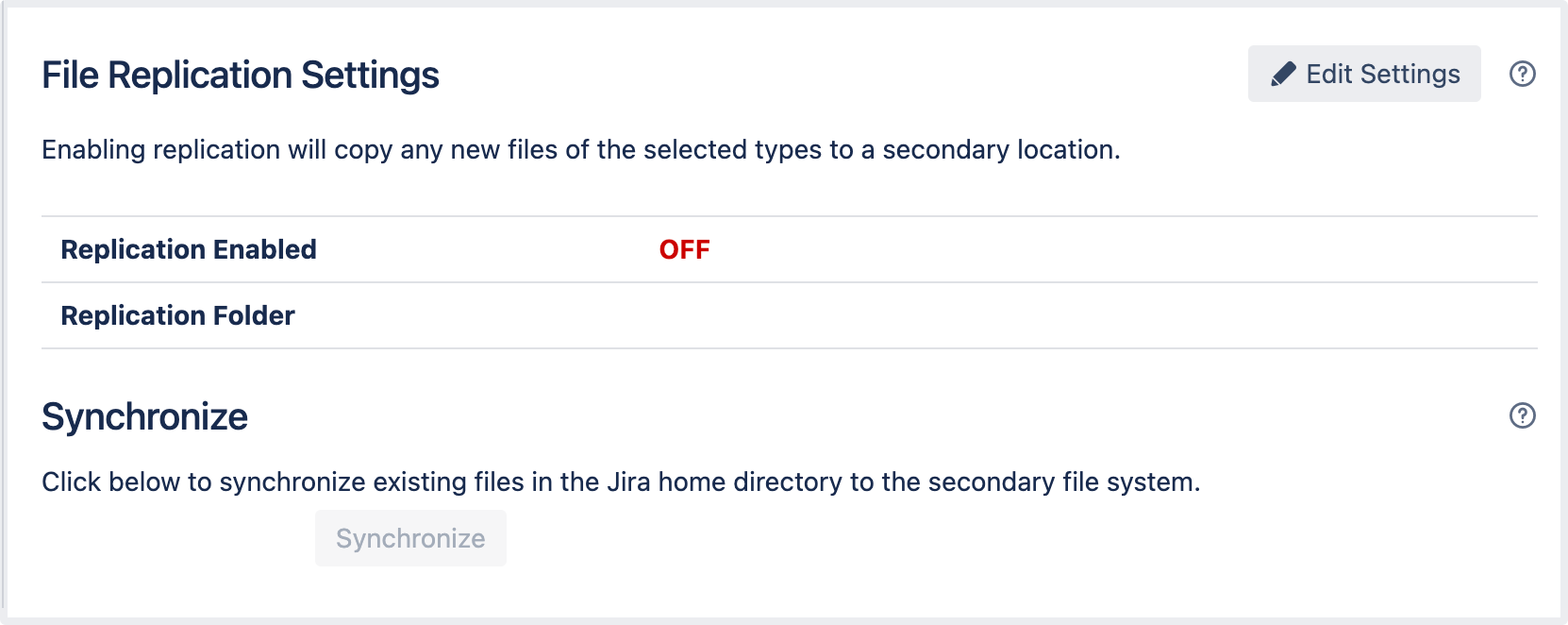
- 必要なファイルタイプのレプリケーションを有効にします。
初めてファイルのレプリケーションを有効にする場合は、[同期] ボタンを選択してファイルを同期します。
ファイル同期は長時間かかる場合があります。Jira へのアクセスを妨げないように、ピーク時間を避けてファイルを同期することをお勧めします。
初回同期の後、Jira は自動的にセカンダリ コピーを更新します。このセカンダリ コピーは非同期に書き込まれるため、プライマリ Jira インスタンスのパフォーマンスには影響しません。
ファイル レプリケーション設定のいずれかを変更した場合は、同期を再度行う必要があります。 これもピーク時間外に実施することをお勧めします。
ディザスタ リカバリ テストの実施
ディザスタ リカバリ計画をテストするときは特に注意してください。単純なミスにより、ライブ インスタンスのデータが損傷を受ける可能性があります。たとえば、テスト中のアップデートが本番データベースに挿入されてしまうような場合です。
テスト中に適切な注意を払わないと、実際の災害からの回復能力に悪影響を及ぼす可能性もあります。
復旧テストを成功させるために重要な点は、メインのデータ センターをディザスタ リカバリ テストからできるだけ隔離することです。
ステップ 1. 本番データを分離する
これは、すべてのテストを行う前に必要な手順です。
データベースの分離
スタンバイ データベースへのレプリケーションをすべて一時的に停止します。
メインのデータベースから分離されていて、接続の方法を持たない別のデータベースに、スタンバイ データベースからデータを複製します。
添付ファイル、アプリ、およびインデックス
テスト中に、決してアプリの更新やインデックスのバックアップを行わないでください。
インデックス バックアップを無効化します。
システム管理者に、Jira で更新を行わないように指示します。
添付ファイルによる問題は起こらないはずです。フォルダに書き込み権限があれば、フェイルオーバー インスタンスのヘルス チェックで十分な情報が得られます。Jira のヘルス チェックについて詳細をご覧ください
インストール フォルダ
ライブ インスタンスとスタンバイ インスタンスの両方から分離されたスタンバイ インストールをクローンします。
Jira の
localhome/dbconfig.xmlでデータベースへの接続を変更して競合を回避します。
これらの手順を完了したあと、データベースを含むスタンバイ インスタンスへのすべてのレプリケーションを再開することができます。
ステップ 2. ディザスタ リカバリ テストの実施
本番データを分離したら、以下の手順に従い、ディザスタ リカバリ計画をテストします。
- 新しいデータベースの準備ができており、最新のスナップショットを持ち、レプリケーションを持たないことを確認します。
適切な
dbconfig.xmlコネクションが設定されたクリーンなサーバーに Jira のコピーがあることを確認します。- テスト サーバーでも、スタンバイ インスタンスと同じように Jira の
sharedhomeがマッピングされていることを確認してください。Lucene を使用している場合は、Jira のsharedhome/export/indexsnapshotsフォルダのスナップショットに最新のインデックス スナップショットがあることが重要です。 - メールを無効化します。Jira アプリケーション メール設定の詳細をご覧ください
Jira をディザスタ リカバリ モードで起動します。各ノードの
jira-config.propertiesファイルに以下を追加します。disaster.recovery=true
フェイルオーバーのハンドリング
プライマリ インスタンスが使用できなくなった場合は、スタンバイ インスタンスにフェイルオーバーする必要があります。このセクションでは、その方法を説明します。また、スタンバイ インスタンスのデータを確認する手順も含まれています。
ステップ 1. スタンバイ インスタンスへのフェイルオーバー
スタンバイ インスタンスへのフェイルオーバーの基本的な手順は以下のとおりです。
- ライブ インスタンスがシャットダウンされ、データベースの更新がなくなっていることを確認します。
- Jira
sharedhomeディレクトリがスタンバイ インスタンスに存在していないことを確認します。/indexarchive - Jira
sharedhome/export/indexsnapshotsの内容を Jirasharedhome/import/indexsnapshotsにコピーします。 - 必要な手順を実行して、スタンバイ データベースを有効化します。
- スタンバイ インスタンスで Jira を起動します。
- Jira が起動するのを待ち、期待どおり動作することを確認します。
- DNS、HTTP プロキシ、または他のフロントエンド デバイスを更新して、トラフィックがスタンバイ インスタンスに転送されるようにします。
Jira が起動したら、Jira localhome/log/atlassian-jira.log
ステップ 2. スタンバイ インスタンスでデータを確認する
次の手順を完了するには、Jira 管理者権限と、すべてのプロジェクトに対するプロジェクトの参照権限が必要です。Jira の権限について詳細をご覧ください
スタンバイ インスタンスにフェイルオーバーした後、ユーザーがシステムにアクセスしてデータを変更し始める前に以下の項目を確認します。
画面右上で [管理]
> [システム] を選択します。
[システム サポート] で、[トラブルシューティングとサポート ツール] を選択します。
[インスタンス ヘルス チェック] タブで、インデックス化と添付ファイルのチェックを検証します。
データベースとインデックスの一貫性
チェックが正常に行われた場合:

チェックが正常に行われなかった場合:

項目数と更新日が、組織の目標復旧地点の範囲内にあることを検証する必要があります。
添付ファイル
チェックが正常に行われた場合:
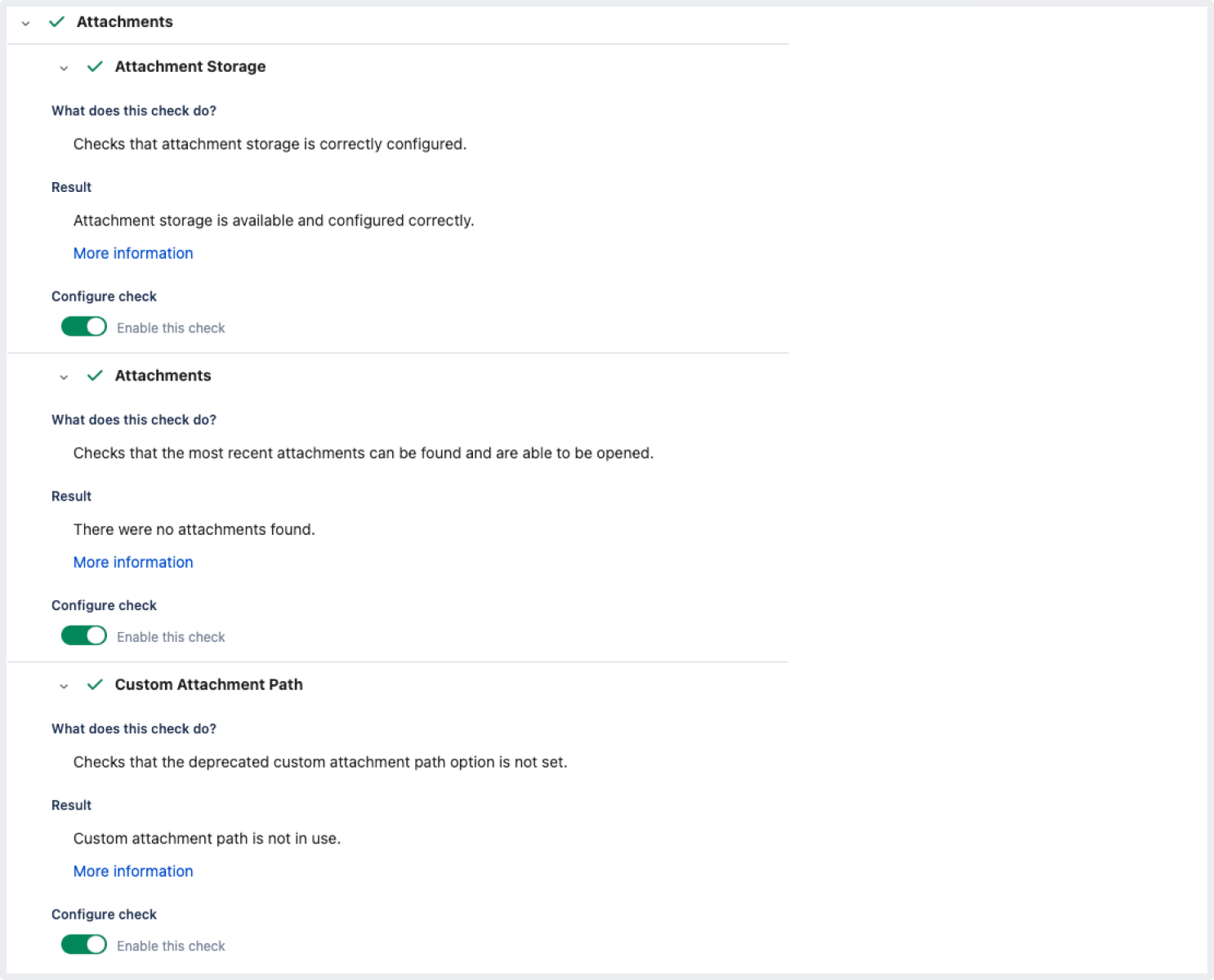
チェックが正常に行われなかった場合:

チェックが動作しない場合は、次のように手動で復旧地点を決定できます。
データベースで、以下の SQL クエリを実行します。
select issueid, created from fileattachment order by created desc limit 1;Jira で [課題] > [課題を検索] の順に移動して、次のように高度な(JQL)検索を実行します。
id=<issue_id>ここで、
<issue_id>は前のステップで SQL クエリで返された issueid です。検索で返された課題を開いて、課題の添付ファイルを表示されるかを確認します。表示されない場合は、やや古い課題をチェックしてみましょう。利用可能な最新の添付ファイルと、表示されない添付ファイルを特定できるはずです。
プライマリ インスタンスに戻る
多くのケースでは、ディザスタの原因となった問題を解決したら、プライマリ インスタンスの使用を再開する必要があるでしょう。適切な長さの停止期間をスケジュールできる場合は、これを簡単に実行できます。
必要な操作:
- プライマリ データベースをセカンダリの状態と同期させる。
- プライマリ添付ファイル ディレクトリをセカンダリの状態と同期させる。
- プライマリ サーバーのインデックス状態を復元する。
ステップ 1. プライマリ インスタンスを使用する準備をする
添付ファイルとその他のファイル
カットオーバー プロセスを開始する前に、rsync または同様のユーティリティを使用して、ほとんどの添付ファイルをプライマリ サーバーに同期します。
同様に、開始する前にインストール済みのアプリとロゴを同期させる必要があります。
検索インデックス
Lucene を使用している場合は、最近のインデックス スナップショットを保持できるように、スタンバイ (実行中の) インスタンスでインデックス スナップショットを有効にします。これはプライマリ インスタンスからアクセスできる場所にコピーする必要があります。
ステップ 2. カットオーバーの実行
- スタンバイ インスタンスで Jira をシャットダウンします。
セカンダリ データベースのデータが、プライマリ データベースと同期されていることを確認します。
- Jira を起動します。
- Lucene を使用している場合は、Jira にログインして、インデックス スナップショットからインデックスを復元します。スナップショット ファイルの名前と場所を把握しておく必要があります。
- Jira が正常に動作していることを確認します。
- DNS、HTTP プロキシまたはその他のフロント エンド プロキシがを更新し、プライマリ サーバーへトラフィックをルーティングするようにします。
ヘルプの確認
ディザスタ リカバリ計画の設定についてサポートが必要な場合や、関連する問題がある場合は、次のリソースをご参照ください。
トラブルシューティングのヒント & よくある質問
スタンバイ インスタンスへのフェールオーバー後に問題が発生した場合は、次の FAQ をご参照ください。
アトラシアン コミュニティ
他の Jira ユーザーの参考になる意見や関連する会話をチェックしましょう。アトラシアン コミュニティは、アプリ開発者、管理者、一般ユーザー、アトラシアン スタッフが集まる場所です。
ベスト プラクティス、質問、コメントを共有しましょう。このページに関連する回答の例をご覧ください。
アトラシアン パートナー
アトラシアンのエキスパートたちが、ご利用の環境に合わせたディザスタ リカバリ計画の実施を支援できる可能性があります。アトラシアン パートナー チームにお問い合わせください。