Daily Statistics job fails to run
プラットフォームについて: Data Center - この記事は、Data Center プラットフォームのアトラシアン製品に適用されます。
このナレッジベース記事は製品の Data Center バージョン用に作成されています。Data Center 固有ではない機能の Data Center ナレッジベースは、製品のサーバー バージョンでも動作する可能性はありますが、テストは行われていません。サーバー*製品のサポートは 2024 年 2 月 15 日に終了しました。サーバー製品を利用している場合は、アトラシアンのサーバー製品のサポート終了のお知らせページにて移行オプションをご確認ください。
*Fisheye および Crucible は除く
要約
The Daily Statistics job fails to run. The analytics logs don't contain a daily statistics entry like the one below:
1.7|2021-06-24 02:20:19,695|1b401868fd9a9b3c1ca6188ef437d85f|confluence|7.4.1|2d0ad342b4ae5617751b6c8dfbd3ff62||confluenceDailyStatistics|{"allComments":4,"maxUsers":2000,"userDirectory.98305.users":3,"allMemberships":4,"allUsers":3,"clusterServerNodes":0,"databaseClusterNodes":0,"blogsWithUnpublishedChanges":3,"draftBlogs":0,"allAttachments":11,"userDirectory.98305.active":true,"currentAttachments":11,"registeredUsers":3,"globalSpaces":1,"draftPages":2,"userInstalledAddOns":1,"isDcLicensed":false,"userDirectory.98305.impl":"INTERNAL","allBlogs":6,"pagesWithUnpublishedChanges":9,"allGroups":2,"currentBlogs":3,"uptime":25147587,"allPages":56,"unsyncedUserCount":1,"userDirectory.98305.type":"INTERNAL","personalSpaces":0,"userDirectory.98305.memberships":4,"userDirectory.98305.groups":2,"currentPages":9,"systemAddOns":333}|1624501219695|SEN-500||periodic||環境
Confluence Data Center with server analytics enabled.
診断
Logs show something like the following:
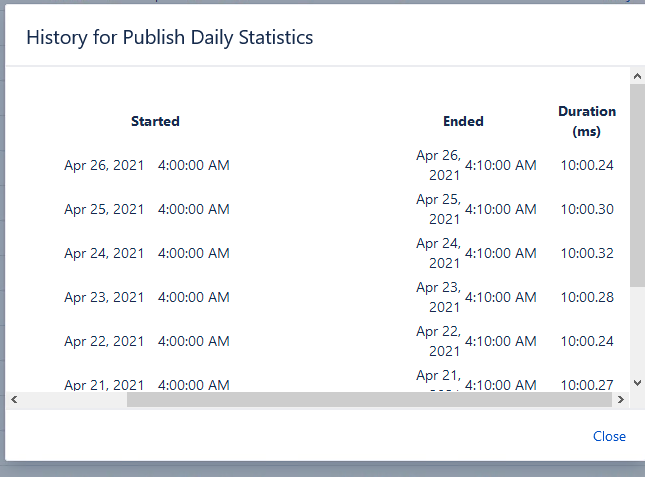
2021-05-10 04:10:00,043 WARN [Caesium-1-2] [impl.schedule.caesium.JobRunnerWrapper] runJob Scheduled job com.atlassian.confluence.plugins.confluence-periodic-analytics-events:confluenceDailyStatisticsPublisherJob#confluenceDailyStatisticsPublisherJob completed unsuccessfully with response JobRunnerResponse[runOutcome=FAILED,message='com.atlassian.confluence.plugins.periodic.event.ConfluenceDailyStatisticsAnalyticsEventSupplier took longer than 600000 ms to supply the event.']The job history shows the job duration as slightly more than ten minutes, which is in line with the warning above:
Thread dumps taken while the job is running show the thread executing the job hanging on a socket read while reading from the database:
java.net.SocketInputStream.socketRead0(Native Method)
java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
java.net.SocketInputStream.read(SocketInputStream.java:171)
java.net.SocketInputStream.read(SocketInputStream.java:141)
sun.security.ssl.InputRecord.readFully(InputRecord.java:465)
sun.security.ssl.InputRecord.read(InputRecord.java:503)
sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:975)
sun.security.ssl.SSLSocketImpl.readDataRecord(SSLSocketImpl.java:933)
sun.security.ssl.AppInputStream.read(AppInputStream.java:105)
org.postgresql.core.VisibleBufferedInputStream.readMore(VisibleBufferedInputStream.java:140)
org.postgresql.core.VisibleBufferedInputStream.ensureBytes(VisibleBufferedInputStream.java:109)
org.postgresql.core.VisibleBufferedInputStream.read(VisibleBufferedInputStream.java:67)
org.postgresql.core.PGStream.receiveChar(PGStream.java:335)
org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2000)
org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:310)
org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:446)
org.postgresql.jdbc.PgStatement.execute(PgStatement.java:370)
org.postgresql.jdbc.PgPreparedStatement.executeWithFlags(PgPreparedStatement.java:149)
org.postgresql.jdbc.PgPreparedStatement.executeQuery(PgPreparedStatement.java:108)
com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:431)
org.hibernate.engine.jdbc.internal.ResultSetReturnImpl.extract(ResultSetReturnImpl.java:71)
org.hibernate.loader.Loader.getResultSet(Loader.java:2123)
org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1911)
org.hibernate.loader.Loader.executeQueryStatement(Loader.java:1887)
org.hibernate.loader.Loader.doQuery(Loader.java:932)
org.hibernate.loader.Loader.doQueryAndInitializeNonLazyCollections(Loader.java:349)
org.hibernate.loader.Loader.doList(Loader.java:2615)
org.hibernate.loader.Loader.doList(Loader.java:2598)
org.hibernate.loader.Loader.listIgnoreQueryCache(Loader.java:2430)
org.hibernate.loader.Loader.list(Loader.java:2425)
org.hibernate.loader.hql.QueryLoader.list(QueryLoader.java:502)
org.hibernate.hql.internal.ast.QueryTranslatorImpl.list(QueryTranslatorImpl.java:370)
org.hibernate.engine.query.spi.HQLQueryPlan.performList(HQLQueryPlan.java:216)
org.hibernate.internal.SessionImpl.list(SessionImpl.java:1481)
org.hibernate.query.internal.AbstractProducedQuery.doList(AbstractProducedQuery.java:1441)
org.hibernate.query.internal.AbstractProducedQuery.list(AbstractProducedQuery.java:1410)
com.atlassian.confluence.user.persistence.dao.hibernate.HibernateConfluenceUserDao.lambda$countUnsyncedUsers$7(HibernateConfluenceUserDao.java:203)
com.atlassian.confluence.user.persistence.dao.hibernate.HibernateConfluenceUserDao$$Lambda$4499/65599827.doInHibernate(Unknown Source)
org.springframework.orm.hibernate5.HibernateTemplate.doExecute(HibernateTemplate.java:384)
org.springframework.orm.hibernate5.HibernateTemplate.execute(HibernateTemplate.java:336)
com.atlassian.confluence.user.persistence.dao.hibernate.HibernateConfluenceUserDao.countUnsyncedUsers(HibernateConfluenceUserDao.java:201)
com.atlassian.confluence.impl.user.persistence.dao.CachingConfluenceUserDao.countUnsyncedUsers(CachingConfluenceUserDao.java:136)原因
The countUnsyncedUsers method that's used to count unsynced users hangs as it queries the data. This is because the query for counting unsynced users queries data from the user_mapping and cwd_user tables, and from two columns that aren't indexed: user_mapping.username and cwd_user.user_name. This results in a table scan of both tables, and when there's tens or hundreds of thousands of records in both tables, this can make the query hang past the timeout of 600000ms.
ソリューション
Add indexes to the two unindexed columns. For example, in Postgres:
create index concurrently user_mapping_idx_username ON user_mapping USING btree (username);
create index concurrently cwd_user_idx_user_name ON cwd_user USING btree (user_name);Please note that creating these indexes can interfere with regular operation of your database, so be sure to test in a lower environment first and consider applying them in production during a maintenance window.