Confluence Data Center 用に Synchrony クラスタを設定する
Confluence Data Center ライセンスをお持ちの場合、Synchrony を実行するには 2 つのメソッドを使用できます。
- Confluence で管理 (推奨)
Confluence は同じノードで自動的に Synchrony プロセスを起動して管理します。手動による操作は不要です。 - スタンドアロンの Synchrony クラスタ (ユーザーによる管理)
ユーザーはスタンドアロンな Synchrony を必要なノード数で、独自のクラスタでデプロイおよび管理します。大規模なセットアップが必要です。ローリング アップグレードでは、Confluence クラスタとは別に Synchrony をアップグレードする必要があります。
シンプルなセットアップを実現してメンテナンスの労力を極力減らしたい場合、Synchrony を Confluence で管理することをおすすめします。完全な制御を実現したい場合や、エディタの高い可用性の確保が必須である場合、独自のクラスタで Synchrony を管理することが、組織に最適なソリューションである可能性があります。
このページの内容
このページでは、自身のインフラストラクチャにホストするスタンドアロンの Synchrony クラスタのセットアップ手順について説明します。独自の Synchrony クラスタを実行する機能は、Data Center ライセンスでのみ利用可能です。
Architecture overview
以下は、独立したクラスタを使用して Synchrony を自身で管理する際のアーキテクチャの簡単な図です。この図には、ノード間の通信は表示されません。
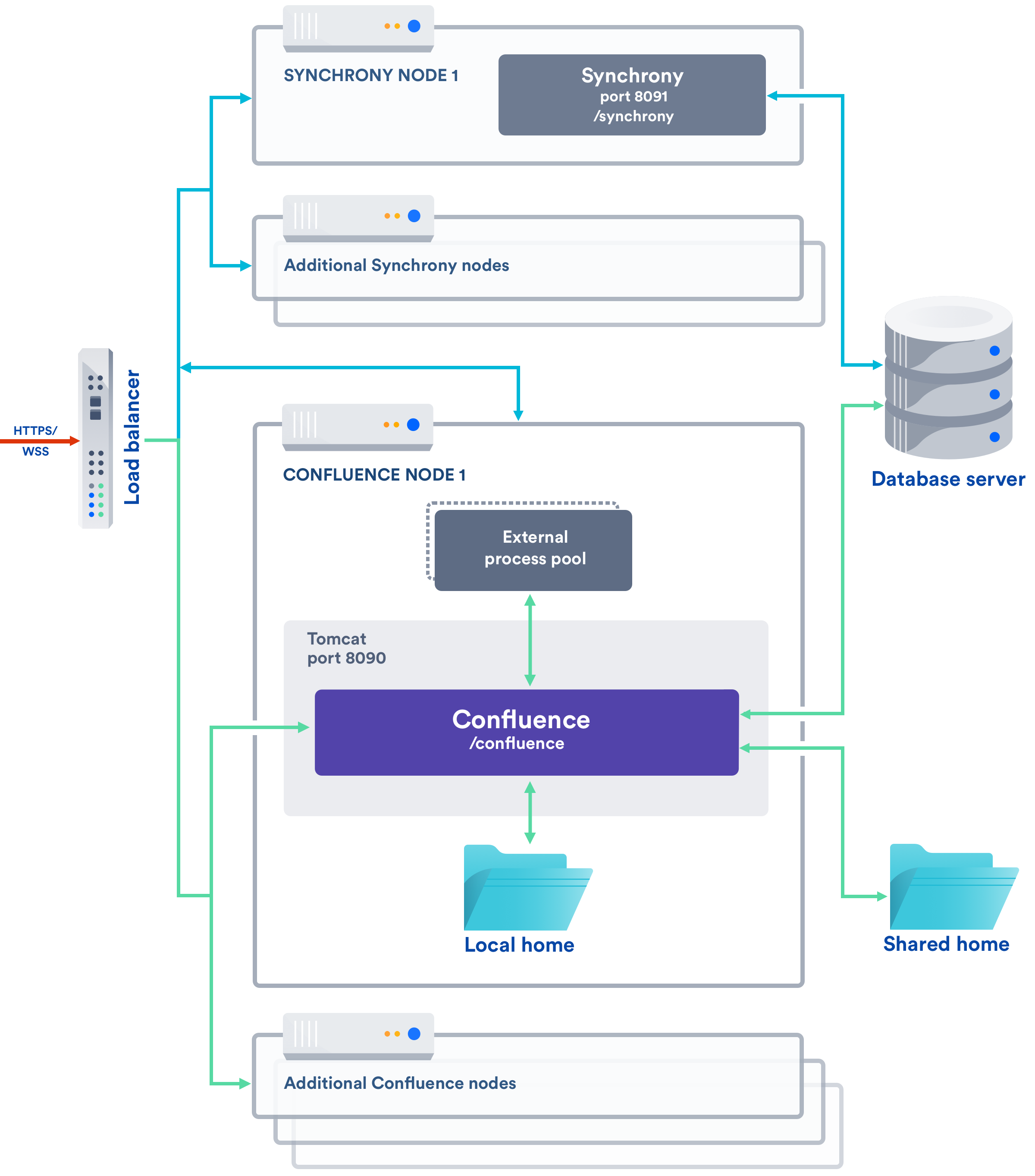
共同編集を Confluence Data Center 6.12 より前に有効化していた場合、スタンドアロンの Synchrony が既定のセットアップとなります。
より簡単なセットアップをご希望の場合、Confluence に Synchrony の管理を許可する方法について、「スタンドアロンの Synchrony クラスタから管理対象の Synchrony に移行する」を参照してください。
Synchrony のスタンドアロン クラスタのセットアップ
このページでは、自身のインフラストラクチャで Synchrony のスタンドアロン クラスタをセットアップする方法について説明します。
AWS または Azure をお使いの場合、スタンドアロンの Synchrony クラスタを持つ Confluence をセットアップするには、アトラシアンが提供しているいずれかのテンプレートを利用できます。
1. Synchrony ノードのプロビジョニング
このガイドでは、Synchrony ノード用にハードウェアまたは仮想インスタンスをプロビジョニング済みであることを想定しています。2 つの Synchrony ノードから始めることをおすすめします。
Synchrony 用に 2GB のメモリと、Synchrony アプリケーションおよびログに十分なディスク容量を許可する必要があります。
2. Synchrony ホーム ディレクトリを作成する
最初の Synchrony ノードに Synchrony ディレクトリを作成するには、次の手順を行います。
- Confluence ノードのいずれかの
<install-directory>/bin/synchronyディレクトリを新しい Synchrony ノードに移動します。これを、<synchrony-home>ディレクトリと呼びます。 synchrony-standalone.jarを Confluence のローカル ホーム ディレクトリから<synchrony-home>ディレクトリにコピーします。- Confluence の
<install-directory>/confluence/web-inf/libからデータベース ドライバをコピーし、<synchrony-home>ディレクトリまたは Synchrony ノード上の適切な場所にペーストします。
3. 開始および停止スクリプトの編集
アトラシアンでは、各ノードで Synchrony を開始および停止するスクリプトを提供しています。これを自身の環境に合わせて編集し、情報を追加する必要があります。
<synchrony-home>/start-synchrony.shファイルまたはstart-synchrony.batファイルを編集します。- [パラメーターの設定] に記載されているすべての必須パラメータに詳細を入力します。
それぞれの説明については、以下の必須プロパティを参照してください。 - 指定したいオプション プロパティの詳細を入力します。
それぞれの説明については、以下のオプション プロパティを参照してください。 - ファイルを保存します。
- start-synchrony スクリプトを実行して、Synchrony を起動します。
http://<SERVER_IP>:<SYNCHRONY_PORT>/synchrony/heartbeatにアクセスして、Synchrony が動作していることを確認します。
4. Synchrony ノードを追加してロード バランサを設定する
2 番目の Synchrony ノードを作成するには、次の手順を実行します。
- <synchrony-home> ディレクトリを 2 番目の Synchrony ノードにコピーします。
そのノードで start-synchrony スクリプトを使用して Synchrony を起動します。各ノードがジョインすると、コンソールに次のように表示されます。
Members [2] { Member [172.22.52.12]:5701 Member [172.22.49.34]:5701 }- ロード バランサーを Synchrony トラフィック用に構成します。
最善の結果を得られるように、ロード バランサーで WebSocket 接続を許可する必要があります。Synchrony は HTTPS リクエストを受け入れられないため、SSL 接続をロード バランサーで終了させる必要があります。
Confluence と Synchrony の両方で同じロード バランサーも、また 2 つの異なるロード バランサーも使用できます。ここで言及する Synchrony ロード バランサーは、Synchrony のトラフィックを処理するロード バランサーを指します。 - Synchrony ポート (8091) が開いていることを確認します。Data Center で Synchrony が使用するすべてのポートの概要については、「Atlassian Data Center アプリで使用するポート」をご参照ください。これは唯一開く必要があるポートです。
5. Confluence のノードを 1 つずつ起動する
Synchrony がクラスタで実行されるようになったため、ここで Confluence を含めます。続行する前に、すべてのノードで Confluence を停止する必要があります。
- すべてのノードで Confluence を停止します。
次のシステム プロパティを使用して、Confluence を1 つのノードで起動します。
このプロパティは Confluence に対して Synchrony の場所を伝え、Confluence が Confluence ノードで Synchrony プロセスを自動的に開始しないようにします。-Dsynchrony.service.url=http://<synchrony-load-balancer-url>/synchrony/v1例:
http://42.42.42.42/synchrony/v1またはhttp://synchrony.example.com/synchrony/v1- Confluence が Synchrony に接続できることを確認します。[管理] メニュー
 から [一般設定] > [クラスタリング] の順に移動して、開始した Confluence ノードの横にある [
から [一般設定] > [クラスタリング] の順に移動して、開始した Confluence ノードの横にある [ ] > [共同編集] の順に選択します。
] > [共同編集] の順に選択します。
Synchrony モードは [スタンドアロン Synchrony クラスター] になっている必要があります。
このモードが [Confluence による管理] の場合、Confluence ノードは Synchrony クラスターに接続されていません。Synchrony サービス URL のシステム プロパティが適切に渡されていることを確認します。 - このプロセスを繰り返し、
synchrony.service.urlで Confluence ノードを 1 つずつ起動します。
Synchrony の実行状態の確認方法の詳細については「Confluence Data Center で Synchrony の状況を確認する方法」を参照してください。
6. 共同編集を有効にする
Confluence を初めてインストールする場合、共同編集は既定で有効になっています。以前の Confluence バージョンからアップグレードした場合や、過去に無効化している場合、共同編集は引き続き無効になっている可能性があります。
共同編集を有効にするには、次の手順を実行します。
- [管理] メニュー から [一般設定] > [共同編集] の順に移動します。
- [モードの変更] を選択します。
- [オン] を選択してから、[変更] を選択します。
これで、ページの編集を試すことができます。ロード バランサ経由で Confluence にアクセスする必要があります。ノードに直接アクセスする場合、ページを作成または編集することはできません。
接続先の Synchrony URL が変更されるため、この変更を加える前にエディタを開いていたユーザーは、編集を続行するためにページを更新する必要があります。
スタンドアロンの Synchrony の必須プロパティ
これらのプロパティは、独自のクラスタでスタンドアロンの Synchrony を実行している場合にのみ適用されます。Synchrony が Confluence (Server または Data Center) によって管理されている場合、これらのプロパティは適用されません。
start-synchrony スクリプトで次のプロパティを提供する必要があります。
| プロパティ名 | 説明 |
|---|---|
SERVER_IP | この Synchrony ノードの公開 IP アドレスまたはホスト名。プライベート IP アドレスの場合もあります。その他のノードによって、Synchrony が到達可能なアドレスに設定する必要があります。 |
DATABASE_URL | Confluence データベースの URL。例: jdbc:postgresql://yourserver:5432/confluence
。この URL は <local-home>/confluence.cfg.xml にあります。 |
DATABASE_USER | Confluence データベース ユーザーのユーザー名。 |
DATABASE_PASSWORD | (オプション) Confluence データベース ユーザーのパスワード。パスワードに特殊文字が含まれている場合、Synchrony はそれを通知せずにデータベースへの接続に失敗する場合があります。 パスワードをハードコーディングするのではなく、環境変数 |
CLUSTER_JOIN_PROPERTIES | これにより、SYnchrony のデータ検出方法が決定します。次のいずれかのパラメーター セットのコメントを外すよう求められます。
これらに入力する値については、スクリプトのプロンプトに従ってください。 |
DATABASE_DRIVER_PATH | データベース ドライバの jar ファイルへのパスです。Synchrony を独自のノードで実行している場合、データベース ドライバを適切なロケーションにコピーした後、そのロケーションへのパスを指定します。 |
SYNCHRONY_JAR_PATH | このノードにコピーした synchrony-standalone.jar ファイルへのパスです。 |
SYNCHRONY_URL | これはブラウザが Synchrony との通信に使用する URL です。一般に、これは Synchrony が背後で実行するロード バランサの完全な URL に Synchrony のコンテキスト パスを加えたものです (例: Confleunce に渡される |
OPTIONAL_OVERRIDES | 追加システム プロパティを指定できます。認識済みのシステム プロパティについては、以下の表を参照してください。 |
FEATURE_AUTH_TOKEN | これは、Handshaking REST API で Synchrony 認証をオンまたはオフにするためのフラグです。これを true に設定し、「認識済みのシステム プロパティ」にある Synchrony の |
AUTH_TOKENS | これは、リクエストが有効と見なされるようにするために、Synchrony に対する Handshaking REST API 呼び出しに含まれている必要がある認証トークンです。 |
スタンドアロンの Synchrony のオプション プロパティ
これらのプロパティは、Synchrony をスタンドアロン クラスタで実行している場合にのみ適用されます。
Synchrony を起動すると、以下に示すプロパティに既定値が渡されます。Synchrony を起動する際、これらのプロパティのいずれかを指定することで、これらの値を上書きすることを選択できます。
| プロパティ名 | 既定 | 説明 |
|---|---|---|
cluster.listen.port | 5701 | これは、Synchrony の Hazelcast ポートです。ポート 5701 を使用しない場合や使用できない場合は、このプロパティを指定します。 Confluence の Hazelcast ポート (5801) と同様に、ファイアウォールまたはネットワークの分離の使用を通じて、承認を受けたクラスタ ノードのみが Synchrony の Hazelcast ポートへの接続を許可されていることを確認してください。 |
synchrony.cluster.base.port | 25500 | Aleph のバインディング ポートです。Synchrony は Aleph を使用してノード間の通信を実行します。既定値を使用しない場合は、このプロパティを指定します。 |
cluster.join.multicast.group | 224.2.2.3 | クラスタ結合タイプがマルチキャストで、既定を使用しない場合はマルチキャスト グループの IP アドレスを指定できます。 |
cluster.join.multicast.port | 54327 | クラスタ結合タイプがマルチキャストで、既定を使用しない場合はマルチキャスト ポートを指定できます。 |
cluster.join.multicast.ttl | 32 | クラスタのジョイン タイプがマルチキャストの場合、これは TTL しきい値です。既定の 32 は、同じサイト、組織、または部門に範囲が制限されていることを意味します。別のしきい値を使用する場合はこのプロパティを指定します。 |
| クラスタのジョイン タイプが AWS の場合、これが AWS アクセス キーです。 | |
| クラスタのジョイン タイプが AWS の場合、IAM ロールまたはシークレット キーで認証できます。これが AWS シークレット キーです。 | |
| クラスタのジョイン タイプが AWS の場合、IAM ロールまたはシークレット キーで認証できます。これが AWS IAM ロールです。 | |
| us-east-1 | クラスタのジョイン タイプが AWS の場合、これが Synchrony ノードを実行する AWS リージョンです。 |
| クラスタのジョイン タイプが AWS で、クラスタのメンバーを特定のセキュリティ グループのリソースに絞り込みたい場合、AWS セキュリティ グループの名前を指定します。 | |
| クラスタのジョイン タイプが AWS で、クラスタのメンバーを特定のタグが付いたリソースに絞り込みたい場合、AWS タグ キーを指定します。 | |
| クラスタのジョイン タイプが AWS で、クラスタのメンバーを特定のタグが付いたリソースに絞り込みたい場合、AWS タグのキー値を指定します。 | |
| クラスタのジョイン タイプが AWS の場合、これが使用する Synchrony 用 AWS エンドポイントです (EC2 API に到達するためのアドレス。例: ec2.amazonaws.com)。 | |
| 5 | クラスタのジョイン タイプが AWS の場合、これがジョイン タイムアウト (秒単位) です。 |
cluster.interfaces | 既定値は SERVER_IP と同じ値 | Synchrony がノード間の通信に使用するネットワーク インターフェースです。既定設定を使用したくない場合はこの値を指定します。既定では、必須プロパティの値がSERVER_IP (synchrony.bind) と同じ値になります。 |
synchrony.cluster.bind | 既定値は SERVER_IP と同じ値 | Aleph のバインディング アドレス。
|
synchrony.port | 8091 | Synchrony を実行する HTTP ポートです。ポート 8091 を利用できない場合は、別のポートを選択するようこのプロパティを指定します。 |
synchrony.context.path | 既定値は SYNCHRONY_URL のコンテキスト パス | Synchrony のコンテキスト パスです。これを変更する必要はありません。 |
hazelcast.prefer.ipv4.stack | True | IPv6 環境で Confluence を実行している場合、このプロパティを False に設定する必要があります。 |
cluster.authentication.enabled | true | Synchrony ノードが Synchrony クラスターに参加する際に認証しない場合は、このプロパティを false に設定します。これは非推奨です このプロパティは 7.17.4 で追加されました。 |
cluster.authentication.secret | (自動生成)。 | このプロパティを設定して、Synchrony ノードが Synchrony クラスターに参加するときにノードを認証するために使用される共有シークレットを変更します。シークレットは最大 40 字の文字列にする必要があります。 このプロパティは 7.17.4 で追加されました。 |
スタンドアロンの Synchrony を IPv6 環境で実行
IPv6 環境でスタンドアロンの Synchrony クラスタを実行する場合、Synchrony を次の JVM 引数で起動する必要があります。
-Dhazelcast.prefer.ipv4.stack=falsestart-synchrony スクリプトを使用している場合は、スクリプトの次の行のコメントを解除します。
スタンドアロンの Synchrony をサービスとして実行する
スタンドアロンの Synchrony クラスタを実行していて、Synchrony を各ノード上でサービスとして実行したい場合は、「Linux でサービスとしてスタンドアロンの Synchrony を実行する」を参照してください。
スタンドアロンの Synchrony を Windows サービスとして実行することはできません。管理対象の Synchrony への切り替えを検討してください。
環境変数を使用してスタンドアロンの Synchrony に資格情報を提供する
クラスタ内でスタンドアロンの Synchrony を実行しており、機密情報を Synchrony の起動スクリプトに直接保存するのではなく自身の環境内に保存したい場合、synchronyenv ファイルを作成し、それを使用してデータベース資格情報を提供できます。これは Linux 環境でのみ行えます。
「環境変数を使用して Synchrony に資格情報を提供する (Linux)」を参照してください。