Confluence Data Center のディザスタ リカバリ
ディザスタ リカバリ戦略は、事業継続計画の重要な部分です。これは災害発生時に従う必要があるプロセスをの概要を説明し、事業を復旧し、業務を継続することを保証します。Confluence の場合、これはプライマリ サイトが利用できなくなった場合の Confluence の可用性を保証することを意味しています。
Confluence Data Center は、アトラシアンがサポートする Confluence 用の唯一高可用性ソリューションです。
Confluence Server から Data Center へのアップグレードでお悩みですか? Confluence Data Center のメリットについて詳細を参照してください。
このページでは、Confluence用のディザスタ リカバリ戦略に Confluence Data Center 5.9 以降を使用する方法を説明しています。ただし、主要目標(RTO、RPO、RCO1)や標準運用手順の設定のような幅広いビジネス プラクティスについてはカバーしていません。
高可用性とディザスタ リカバリの違いはなんですか?
「高可用性」、「ディザスタ リカバリ」、および「フェイルオーバー」という単語は混同されがちです。このページでは、これらの言葉を次のように定義します。
- 高可用性 – 特定レベルの可用性を提供する戦略。Confluence の場合は、アプリケーションへのアクセスと許容応答時間です。自動修正と(同じ場所での)フェイルオーバーは通常、高可用性計画の一部です。
- ディザスタ リカバリ – (災害などで)メインのデータ センターが利用できなくなる場合に、(通常、別の地域にある)別のデータ センターで運用を再開する戦略。(別の場所への)フェイルオーバーはディザスタ リカバリの基本的な部分です。
- フェイルオーバー - あるマシンが故障した際に、あるマシンが別のマシンから引き継ぐときのことを指します。これは同じデータ センター内またはあるデータ センターから別のデータ センターで行われます。フェイルオーバーは通常、高可用性戦略とディザスタ リカバリ計画の両方の一部です。
概要
始める前に、Confluence Data Center を設定およびセットアップしてください。「Confluence Data Center クラスタのセットアップ」を参照してください。
このページでは、一般的に「コールド スタンバイ」と呼ばれる戦略について説明しています。これはスタンバイ Confluence インスタンスが継続的に実行されておらず、スタンバイ インスタンスを起動し、組織のビジネス ニーズに対するサービスを提供するのに適した状態にあることを確認するための管理手順の実行が必要であることを意味しています。
runbook のメンテナンス
詳細な手順は組織によって異なるため、完全な手順の runbook は参照する本番システムから離れたファイルに保持することをお勧めします。runbook は、事前知識や経験にかかわらず、関連するチームの誰もが手順を実施してサービスを復旧できるように十分に詳細化します。runbook にはディザスタ リカバリ プロセスの以下の部分をカバーする手順が含まれていることが期待されます。
- 問題の検出
- 現在の本番環境の分離と正常終了
- 障害が発生した本番環境と目的の復旧ポイント間のデータの同期
- 復旧インスタンスへのウォーム アップ命令
- ドキュメント、コミュニケーション、およびエスカレーション ガイドライン
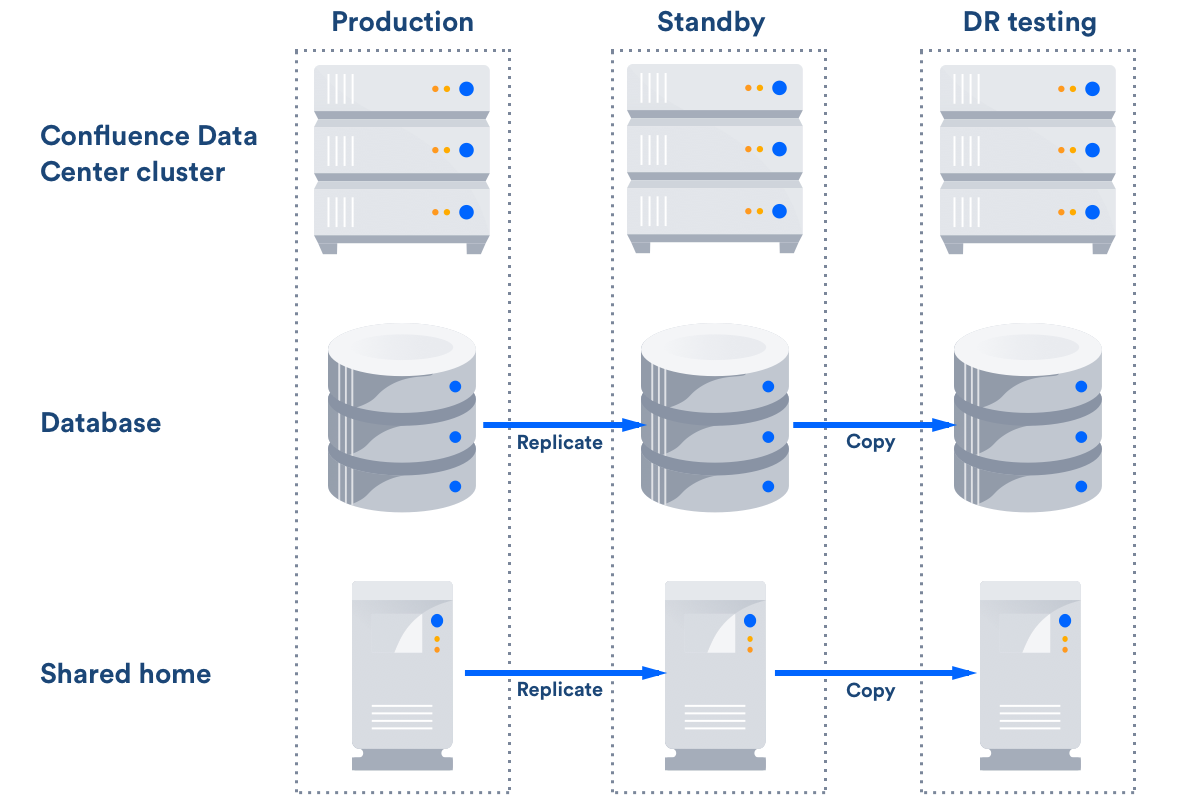
ディザスタ リカバリ計画で考慮する必要がある主なコンポーネントは以下のとおりです。
| Confluence インストール | スタンバイ サイトには、本番サイトと完全に同じバージョンの Confluence がインストールされている必要があります。 |
|---|---|
| データベース | これは Confluence の主要な情報源であり、Confluence データのほとんど(添付ファイルやアバターなどを除く)を含んでいます。データベースをレプリケートし、継続的に最新に維持し、RPO1を満たす必要があります。 |
| 添付ファイル | すべての添付ファイルは Confluence Data Center の共有ホーム ディレクトリに保存されており、スタンバイ インスタンスにレプリケートされていることを確認する必要があります。 |
| 検索インデックス | 検索インデックスは主要な情報源ではなく、いつでもデータベースから再作成することができます。大規模なインストールの場合は長時間かかる可能性があり、インデックスが完全に復旧するまで Confluence の機能は大幅に低下します。Confluence Data Center は検索インデックスのバックアップを共有ホーム ディレクトリに保存しています。これは共有ホーム ディレクトリのレプリケーションでカバーされています。 |
| プラグイン | ユーザーがインストールしたプラグインはデータベースに保存されており、データベースのレプリケーションでカバーされています。 |
| その他のデータ | その他の重要ではないアイテムは Confluence Data Center の共有ホームに保存されています。これらがスタンバイ インスタンスにレプリケートされていることを確認します。 |
スタンバイ システムのセットアップ
ステップ 1. Confluence Data Center 5.9 以降をインストールする
スタンバイ システムに同じバージョンの Confluence をインストールします。スタンバイ データベースにアタッチするようにシステムを設定します。
スタンバイ Confluence システムを起動しないでください
Confluence の起動によって、データベースと共有ホームに不要なデータが書き込まれます。
一時的に異なるデータベースおよび異なる共有ホーム ディレクトリに接続して Confluence を起動し、期待通りに動作することを確認して、インストールをテストすることができます。テスト後にスタンバイ データベースを参照するようデータベース設定を更新し、スタンバイ共有ホーム ディレクトリを参照する用共有ホーム ディレクトリ設定を更新することを忘れないでください。
ステップ2.データ レプリケーション戦略の実装
スタンバイの場所へのデータのレプリケートは、コールド スタンバイ フェイルオーバー戦略において不可欠です。スタンバイのデータが古かったり、インデックスの再作成に数時間かかると、スタンバイ Confluence インスタンスにフェイルオーバーさせたくなくなります。
| データベース | 以下の Confluence がサポートするデータベース サプライヤーのはすべて独自のデータベース レプリケーション ソリューションを提供しています。 RTO、RPO、および RCO1 を満たすデータベース レプリケーション戦略を実装する必要があります。 |
|---|---|
| ファイル | RTO、RPO、および RCO1 を満たす Confluence 共有ホーム ディレクトリ用のファイル サーバ レプリケーション戦略も実装する必要があります。 |
クラスタリングの考慮事項
クラスタ化された環境の場合、上記の情報に加え、以下に注意する必要があります。
| スタンバイ クラスタ | スタンバイ クラスタがライブ クラスタの構成を反映する必要はありません。要件と予算に応じて、含まれるノードが増減する可能性があります。ノードが少なくなるとスループットが低下しますが、状況に応じて許容される可能性があります。 |
|---|---|
| ファイルの場所 | 同期が必要なファイルの場所として |
| スタンバイ クラスタの起動 | 最初にクラスタのノードを1つだけ起動し、検索インデックスを復旧させ、他のノードを起動する前に正しく動作することを確認するのが重要です。 |
ディザスタ リカバリ テスト
ディザスタ リカバリ計画をテストする際は、細心の注意を払ってください。たとえば、テストの更新が本番データベースに挿入された場合など、単純なミスによってライブ インスタンスが破損する可能性があります。ディザスタ リカバリのテスト中に、実際の災害から復旧する能力に悪影響を及ぼあす可能性があります。
重要なことはメインのデータ センターをディザスタ リカバリ テストから可能な限り分離することです。
この手順は、スタンバイ環境が正しいデータをすべて持つことを保証しますが、テスト環境はスタンバイ環境から完全に分離されているため、スタンバイ インスタンスで起こりうる構成の問題はカバーされていません。
Prerequisites
テストを実施する前に、本番データを分離する必要があります。
| データベース |
|
|---|---|
| 添付ファイル、プラグイン、およびインデックス | テスト中にプラグインの更新やインデックスのバックアップが発生しないようにする必要があります。
|
| インストール フォルダ |
|
このあと、データベースを含むスタンバイ インスタンスへのすべてのレプリケーションを再開することができます。
ディザスタ リカバリ テストの実施
本番データを分離したら、以下の手順に従い、ディザスタ リカバリ計画をテストします。
- 新しいデータベースの準備ができており、最新のスナップショットを持ち、レプリケーションを持たないことを確認します。
- 新しい共有ホーム ディレクトリの準備ができており、最新のスナップショットを持ち、レプリケーションを持たないことを確認します。
- クリーン サーバーに、適切なデータベースおよび共有ホーム ディレクトリ設定 (
<confluencelocalhome>/confluence.cfg.xml) を含む Confluence のコピーがあることを確認します。 - スタンバイ インスタンスと同様に、テスト サーバーで confluence.home がマッピングされていることを確認します。
- メールを無効化します (「システム プロパティの設定」の
atlassian.mail.senddisabledを参照)。 - Confluence を起動します。
フェイルオーバーのハンドリング
プライマリ サイトが利用できなくなった場合、スタンバイ システムにフェイルオーバーする必要があります。手順は以下のとおりです。
- ライブ システムがシャットダウンされており、データベースの更新がなくなっていることを確認します。
<confluencesharedhomeの内容がスタンバイ インスタンスに同期されていることを確認します。>- スタンバイ データベースをアクティブ化するのに必要な手順を実施します。
- スタンバイ インスタンスの1つのノードで Confluence を起動します。
- Confluence が起動するのを待ち、期待通りに動作することを確認します。
- 他の Confluence ノードを起動します。
- DNS、HTTP プロキシ、またはその他のフロント エンド デバイスを更新し、トラフィックをスタンバイ サーバーにルーティングします。
プライマリ インスタンスに戻る
ほとんどの場合、ディザスタの原因となった問題を解決した後、プライマリ インスタンスを使用して戻ることになります。妥当なサイズの停止期間をスケジュールできる場合は、この方法が最も簡単です。
必要な操作:
- プライマリ データベースをセカンダリの状態と同期させる。
- プライマリ共有ホーム ディレクトリをセカンダリの状態と同期させる。
カットオーバーの実行
- スタンバイ インスタンスで Confluence をシャットダウンします。
- データベースが要求どおり、正しく同期さおよび構成されていることを確認します。
- rsync または類似のユーティリティを使用して、共有ホーム ディレクトリをプライマリ サーバーに同期します。
- Confluence を起動します。
- Confluence が期待どおり動作していることを確認します。
- DNS、HTTP プロキシまたはその他のフロント エンド プロキシがを更新し、プライマリ サーバーへトラフィックをルーティングするようにします。
その他のリソース
トラブルシューティング
スタンバイ インスタンスへのフェールオーバー後に問題が発生した場合、ガイドラインの以下の FAQ を確認してください。
定義
| RPO | Recovery Point Objective : 目標復旧地点 | 障害発生後、Confluence インスタンスをどの程度最新の状態にする必要があるか |
| RTO | Recovery Time Objective : 目標復旧時間 | 障害発生後、スタンバイ システムをどの程度の時間で利用できるようにする必要があるか |
| RCO | Recovery Cost Objective : 目標復旧コスト | ディザスタ リカバリ ソリューションにどの程度の金額をかける意思があるか |