サービスの制限
Jira Server インスタンスが円滑に実行されていることを確認することは、優れた Jira 管理者の責任です。サービスの制限は皆様を対象にしていますが、99.9% のユーザーはこうした制限を経験しません。本当に例外的なケースにのみ適用されます。
| limit | Server | 制限違反の例 |
|---|---|---|
| ルールのコンポーネント数 | 65 | 1 つのルールに対して、条件、ブランチ、アクションが 65 を超える。 |
| 各アクションの新規サブタスクの数 | 100 | 100 件を超えるサブタスクの作成をトリガーします。 |
| 検索される課題 | 1000* | スケジュールされた JQL 検索のうち、最適化が不十分で返される課題が 1000 件を超えるもの。 *サーバーでは、この数は jira.search.views.default.max 設定プロパティに由来しています。設定すると、Jira のグローバルな検索で返される課題の数を制限できます。 |
| 同時にスケジュールされたルール実行 | 1 | 実行が 5 分を超えるアクションが、5 分おきにスケジュールされたルール。このルールの同時実行は 1 つのみ許可します。 |
| ルール別キュー項目 | 25000 | 詳細についてはキューのアイテム数の制限に関する次のセクションをご参照ください。 |
| グローバル レベルでキューに入れられているアイテム数 | 100000 | ルールに従ってキューに入れられたアイテムと同様ですが、グローバル レベルの Jira インスタンス全体で進行中のルールに適用されます。 |
| 1 日の処理時間 | 120 分 | ルールが 5 分ごとに実行されて、1 回あたり (クラウドで) 5 秒を超える。たとえば、ルールで動作の遅い外部システムと通信する場合はこのケースに該当する可能性があります。 |
| 毎時の処理時間 | 100 分 | 課題イベントをリッスンする複数のルールを構成して、これらのルールを一括操作で実行する。この制限は、クラウドで 1 時間に実行されるルールが 2000 件を超える、またサーバーで 1 時間に実行されるルールが 5000 件を超える場合にのみトリガーされます。 |
| ループ検知 | 10 | 実行が停止されてループとしてマークされるまでに、ルール自体 (または他のルール) をどれだけ速く連続でトリガーできるかを制御します。 |
最新バージョンの Automation for Jira Server を実行している場合は、サービスの制限違反トリガーによって、上記の処理時間制限のいずれかに違反しそうになっている際に通知を送信する自動化ルールをセットアップできます。
制限違反
監査ログに次のようなエラーが表示されている場合は、制限に達しています。
- 監査アイテムのステータスは THROTTLED です。
- 監査アイテムに次のいずれかが含まれます。
- この自動化ルールは前日の合計処理時間の上限を超えた。1 日の最大処理時間 (秒):
- Automation for Jira が過去 1 時間のルール実行数の上限を超えた。
- この自動化ルールの JQL 検索が 1 回の検索で取得できる最大課題数を超えた。最初の課題から次の上限数までしか処理されていない:
ルールが制限を超えると、監査ログに次の詳細が表示されます。
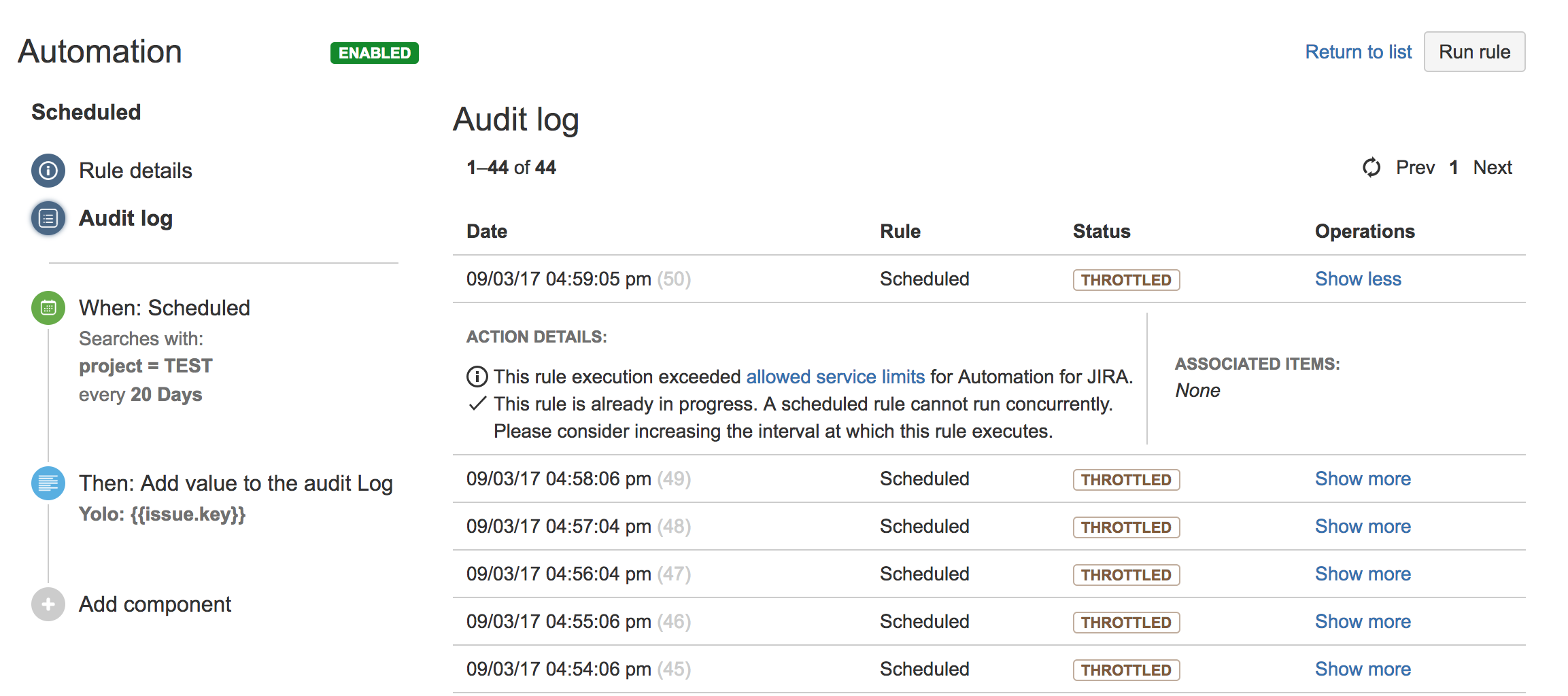
監査ログに表示される詳細に基づいて、ルールが許容可能制限内に収まるように次のようないくつかのステップに従えます。
- スケジュールされたルールの実行間隔を短くします。たとえば、5 分ではなく 1 時間おきにのみルールを実行します。
- JQL クエリを制限して関心のある課題のみを検索します。たとえば、課題の更新された時間が一定の範囲内であることを確認します (更新済み > -1 週間として、前週の課題のみを含める)。
- 各ルールに複数のコンポーネントが必要な場合は、自動化ルールを複数のルールに分割します。
- 数千の課題を編集する必要のある非常に大きな一度限りの操作に対しては、Jira の一括変更機能を使用する。
サービスの制限を増やす
REST API を介してこれらの値を変更できます。
REST 呼び出しによって制限を増やす
最初に、この HTTP REST 呼び出しを使用している現在の制限を調べます。
https://YOUR_JIRA_INSTANCE_URL/rest/cb-automation/latest/configuration/property:
{
"max.processing.time.per.day": "3600",
"rule.rate.per.five.second": "2",
"short.scheduled.interval.issue.limit": "1000",
"max.rules.per.hour": "5000",
"max.issues.per.search": "1000",
"max.queued.items.per.rule": "25000"
}では、順番に解説していきましょう。
| プロパティ | 説明 |
|---|---|
max.processing.time.per.day | 1 つのルールが直近の 24 時間で処理にかけられる最大秒数です。つまり、ルールの実行に平均で 1 分かかって 24 時間の制限内に 60 回実行されると、このルールが調整されます。 |
rule.rate.per.five.secondmax.rules.per.hour | 処理できるルールの数を制御します。次のように機能します。
これによって、アクティビティのスパイクがあれば調整されることが保証されます。ただし、このスパイクの後にアクティビティが通常に戻ってルールが少しずつ流れていくと、すぐに再び実行されます。 たとえば、過去 5 秒間にルール A が 10 回トリガーされたとします。過去 1 時間ですべてのルールがトリガーされた回数を確認します。インスタンスで 5000 回を超えると、このルールの実行は抑制されます。 |
max.issues.per.search | 検索を実行するトリガーによって合計で処理される課題の数を制御します (例: JQL または受信 Webhook トリガー)。初期設定は jira.search.views.default.max 設定プロパティで、これは個別に設定できます。 |
short.scheduled.interval.issue.limit | この制限によって、スケジュールされたトリガーにより大規模な課題検索を実行できる間隔を短縮します。クエリがこの制限を超える課題を返す場合、UI には警告が表示されて 24 時間に多くても 4 回のスケジュールのみが許可されます。これはソフト制限で、ルールの設定時にのみ適用されます。 |
automation.processing.thread.pool .size.per.node | この制限は上記のプロパティとは少し異なり、Jira Server のキューからルールを処理するスレッドの数を定義します。初期設定では、サーバーごと (またはデータ センターのノードごと) に 4 スレッドです。通常、ほとんどのインスタンスにとってこの値で十分なはずです。ルールの実行速度が遅い場合は、これを 8 スレッドに増やすことをお勧めします。 ⚠️警告: この値を増やすと逆効果となり、DB またはアプリ サーバーが増加した負荷を処理できない場合にパフォーマンスが低下する可能性があります。インフラに確実に処理能力がある場合にのみ、この値を増やしてください。 |
max.queued.items.per.rule | 詳細については「キューのサービス制限」をご参照ください。 |
max.queued.items | max.queued.items.per.rule と同様ですが、現在進行中のすべての自動化ルール全体で Jira インスタンスにグローバルに適用されます。 |
max.rule.execution.loop.depth | ループの検出方法を制御します。1 つ以上のルールはそれ自体または他のルールをトリガーして、この制限までの実行チェーンを作成できます。初期設定は 10 です。つまり、最も単純なケースでは、すぐにそれ自体をトリガーするルールがある場合は、実行が停止して監査ログで LOOP としてマークされる前に 10 回の実行が許可されます。 |
これらのプロパティのいずれかを設定するには、この REST 呼び出しを使用します (Content-Type の設定は application/json)。
PUT https://<your Jira instance url>/rest/cb-automation/latest/configuration/property
{
"key": "max.processing.time.per.day",
"value": "10000"
}curl コマンドの例
curl -X PUT -H 'Content-type: application/json' \
-d '{"key": "max.rules.per.hour", "value": "10000"}' \
https://your-instance.com/rest/cb-automation/latest/configuration/propertyキューのアイテム数のサービス制限
Automation for Jira Server では、ルール処理キューによってインスタンスにおける自動化ルールの実行が管理されます。Jira では、ブラウザーでユーザーからのリクエストを処理したり、自動化ルールなどの「バックグラウンド」サービスを実行したりするために利用できる容量が限られています。Jira が過負荷になり応答が止まることがないように、自動化ルールの実行はキューに入れられて、キューから並行して処理されるアイテムの数が制限されます。初期設定では、Cloud で 8 アイテムのみが Jira ホストごとに並行して、サーバーで 6 スレッドが同時に処理されます (Data Center 構成ではノードごとに)。
自動化ルール ビルダーは非常に強力で、ユーザーが設定できるルールはほぼすべての処理に対応できます。これによって、実行に非常にコストがかかるルールになる可能性があります。次の課題の例で、特定のシナリオを考えてみましょう。
- ABC-120 - 課題タイプが「タスク」の親開発課題
- ABC-121 - サブタスク 1
- ABC-122 - サブタスク 2
- ABC-123 - サブタスク 3
- ABC-124 - サブタスク 4
- ABC-125 - サブタスク 5
- ABC-130 - 課題タイプが「タスク」の別の親開発課題
- ABC-131 - サブタスク 1
- ABC-132 - サブタスク 2
- ABC-133 - サブタスク 3
- ABC-134 - サブタスク 4
- ABC-134 - サブタスク 5
ここで、次のルールを考えてみましょう。

この単純なルールでは、13 の個別アイテムが自動化キューに入っています。では、順番に解説していきましょう。
- 1 アイテムがキューに入っている目的は、検索を実行するために最初にスケジュールされたトリガーの実行です。
- 2 アイテムがキューに入っている目的は、親課題 ABC-120 & ABC-130 のマッチングです。
- 次に、それらの各アイテムについて、関連する課題のブランチがそれぞれ 5 アイテムをキューに入れています。
つまり、すべてを合わせると 1 + 2 + 5 + 5 = 13 アイテムです。
たとえば、最初にスケジュールされたトリガーが多数の課題にマッチする、または関連する課題ブランチが多数の課題にマッチする場合、こうしたタイプのルールではキュー アイテムがすぐに増える可能性があることが分かります (また、関連する課題ブランチは JQL 別に課題を検索できます)。
キューに多くのアイテムあると良くない理由
インフラストラクチャはキュー内にある多くのアイテムを処理します。ただし、たくさんのアイテムを挿入する単一のルールは、Automation for Jira のパフォーマンスにとって有害です。ある顧客のルールでは、100,000 件を超えるアイテムが Cloud の自動化キューに挿入されて、その顧客の 8 個のプロセッサーすべてがキューを処理するのに何時間もの間ビジーな状態になり、他のルールすべてに遅延が発生していました。
この状況をある程度回避するには、特定のルールを優先して実行します (例: 手動ルールのトリガーを最初に実行する)。ただし、このアプローチは一定の範囲までしか効果がありません。
調整と無効化
ルールの実行終了時にキューに過剰な数のアイテムが追加されると、そのルールは監査ログに記録されてそれ以上は実行されないように無効になります。

キューが急増する原因となるルールはどのようなものですか?
多数の関連課題ブランチを伴い、これらの各課題ブランチが多数の課題とマッチしているルールの例を次に示します。
- 100 件の課題にマッチするスケジュールされたトリガー
- 50 件の課題にマッチする関連課題ブランチ
- 80 件の課題にマッチする別の関連課題ブランチ
この結果は (約) 13,000 アイテム (100 * 50 + 100 * 80) です。
(if 条件をシミュレートするための) 多数の関連課題ブランチ含むルール
- トリガー: 課題の更新
- 関連課題ブランチの JQL タイプがバグであり、課題 1000 件にマッチする
- 関連課題ブランチの JQL タイプがタスクであり、課題 500 件にマッチする
- 関連課題ブランチの JQL タイプがフィーチャーであり、課題 2000 件にマッチする
この結果は、ブランチの数に応じて 3,500 アイテム以上になります (1000 + 500 + 2000)。
防止策
ついに重要なところまで到達しました。幸いなことに、ほとんどのルールは実行されるたびに、それほど多くの課題に対して実行されるわけではありません。この問題を軽減するオプションをいくつか用意しました。
- 実行対象が最小限の課題セットに抑えられるように JQL を使用する。その方法は以下のとおり、いくつかあります。
- JQL 検索の内容をできるだけ具体的にします。たとえば、現在「進行中」の課題にのみ関心がある場合は、単純に
type = Taskに一致する課題を検索しないでください。type = Task and status = "In Progress"と検索することをお勧めします。 Only include issues that have changed since the last time this rule executedチェックボックスをチェックにして、ルールを最後に実行してから変更された課題のみを含めます。ルールの多くは、この小さいサブセットで運用するだけでも問題ありません。
- JQL 検索の内容をできるだけ具体的にします。たとえば、現在「進行中」の課題にのみ関心がある場合は、単純に
- 関連課題ブランチを「条件付きの確認」用に作成しないでください。そのため上記のルールは多くの関連課題ブランチで
type = Bug、type = Taskなどを確認することで、次のように効率的に書けます。- トリガー: 課題の更新
- 目的の課題とマッチする特定 JQL の関連課題ブランチ (何らかの形でトリガー課題に関連する)
- このブランチで、if/else ブロックによってマッチを課題タイプに基づいて探す
一般的に、トリガーまたは関連課題ブランチによって、1 つのルールで取得する課題の総数を減らすことを目的としています。