データ パイプライン エクスポート スキーマ
このページでは、Jira データ エクスポート ファイルの構造とデータ スキーマについて説明します。
データ パイプラインを設定して構成する方法については、「データ パイプライン」をご参照ください。
- 各ファイルにはヘッダーがあります。これには結果的にデータのないエクスポートからのファイルも含まれます。
- 改行は CRLF 文字
\r\nで区切られます。 - 改行 (CRLF)、二重引用符、およびカンマを含むフィールドは、二重引用符で囲まれます。
- フィールド内に二重引用符がある場合、フィールド内で使用される二重引用符の前には別の二重引用符を付けてエスケープします (
"aaa"、"b""bb"、"ccc"など)。 - CSV エクスポートでは、データのない (Null 値) フィールドは 2 つの連続した区切り文字で表されます (例:
,,)。 - 組み込まれた改行はデフォルトでエスケープされて、n として印刷されます。
可用性
出力
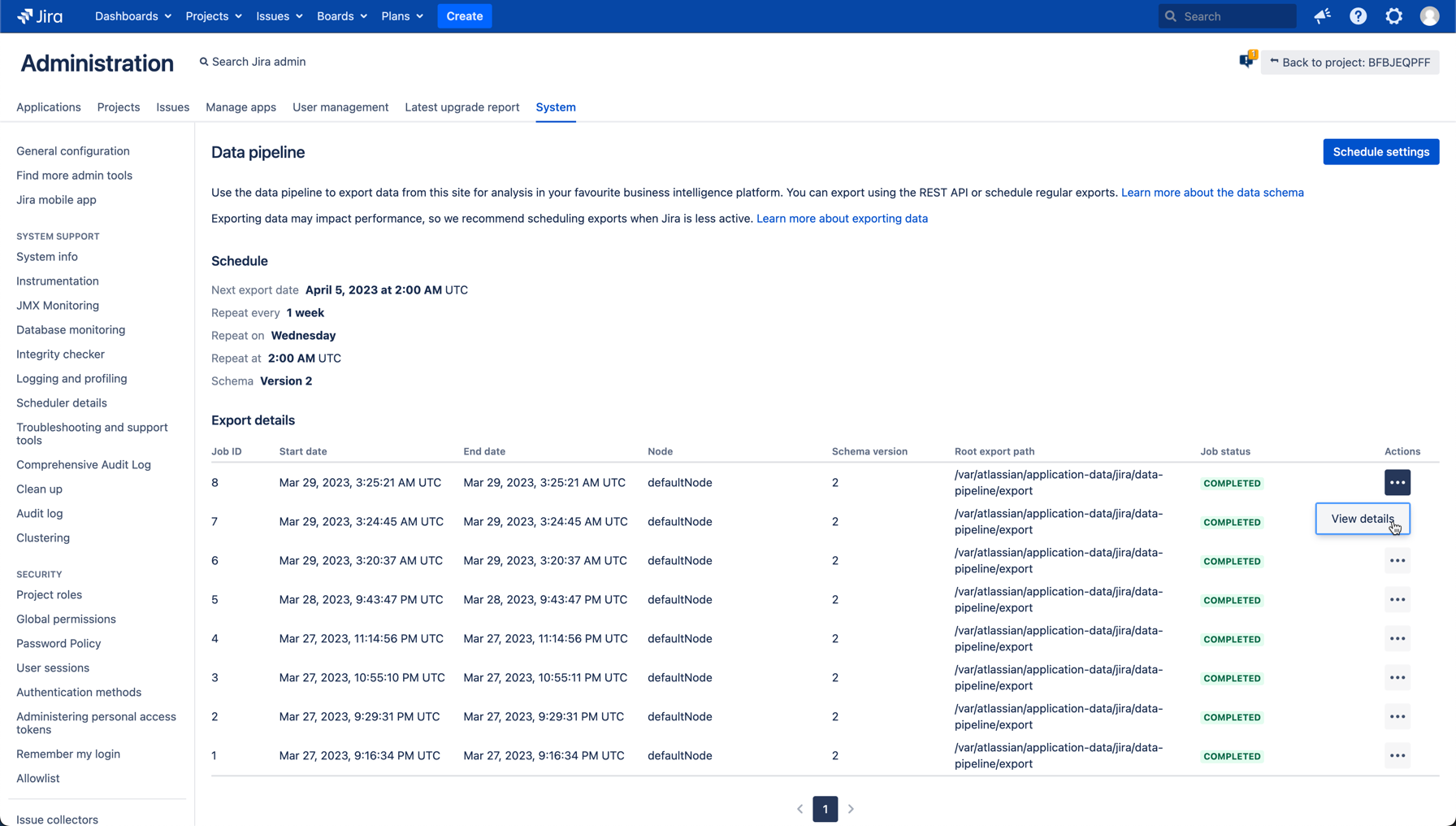
エクスポートの詳細にアクセスする方法は次のとおりです。
[管理] > [システム] > [データ パイプライン] の順に移動します。
[エクスポートの詳細] リストから [アクション] > [詳細を表示] を選択します。
3. エクスポート時間は、exportFrom 行で確認できます。
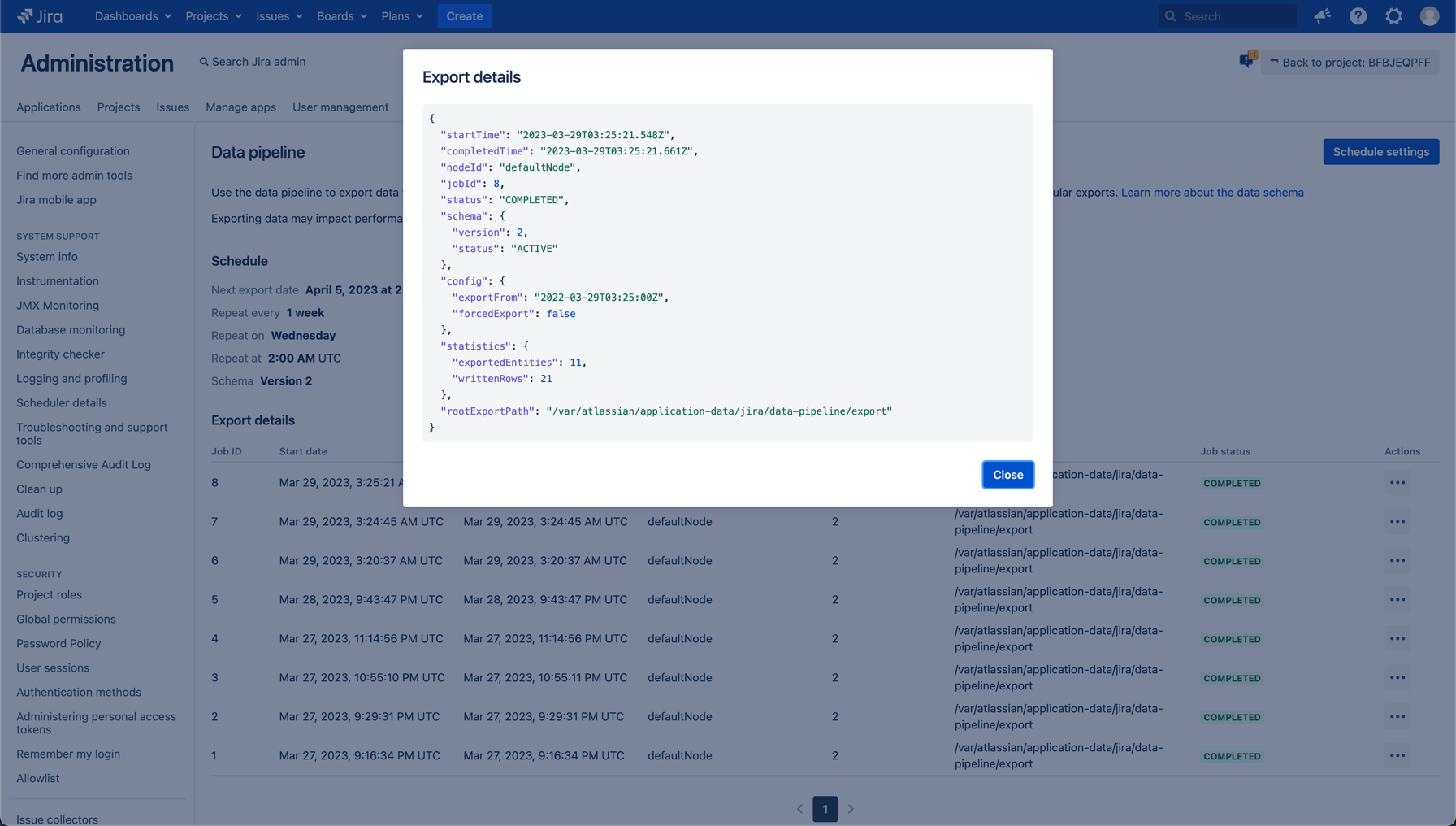
課題や課題リンクが完全に削除された場合、これらのファイルには表示されません。過去のすべての変更については、issue_history ファイルを確認する必要があります。
fromDate は、初期設定で前年を含み、提供されたタイムスタンプ以降に更新された課題とそのメタデータのクエリを示します。
On this page:
課題スキーマ
Jira Software Jira Service Management
issuesCSV ファイルにエクスポートされます。| フィールド | 説明 |
|---|---|
id (主キー) | タイプ: 数値 説明: この課題の一意の ID。主キーとして使用します。 例: |
| instance_url | タイプ: 文字列 説明: 現在のインスタンスのベース URL 例: |
| URL | タイプ: 文字列 説明: 課題の URL 例: |
| 鍵 (キー) | タイプ: 文字列 説明: この課題の一意のキー 例: |
| project_key | タイプ: 文字列 説明: この課題があるプロジェクトのキー 例: |
| project_name | タイプ: 文字列 説明: 課題があるプロジェクトのタイトル 例: |
| project_type | タイプ: 文字列 説明: 課題があるプロジェクトの種類 (ビジネス、ソフトウェア、サービス デスクなど) 例: |
| project_category | タイプ: 文字列 説明: この課題が含まれるプロジェクトに割り当てられたカテゴリー 例: |
| issue_type | タイプ: 文字列 説明: 課題の種類 (タスク、バグ、エピックなど) 例: |
| 要約 | タイプ: 文字列 説明: 課題の要約 例: |
| description | タイプ: 文字列 説明: 課題の説明 (2000 文字以内) 例: |
| creator_id | タイプ: 数値 説明: 課題を作成したユーザーの一意の ID (ディレクトリとは無関係) 例: |
| creator_name | タイプ: 文字列 説明: ユーザー課題作成者の名前 例: スキーマ: バージョン 1 のみ。このデータは Users ファイルに含まれています。 |
| reporter_id | タイプ: 数値 説明: 課題報告者の一意の ID (ディレクトリとは無関係) 例: |
| reporter_name | タイプ: 文字列 説明: 課題報告者の名前 例: スキーマ: バージョン 1 のみ。このデータは Users ファイルに含まれています。 |
| assignee_id | タイプ: 数値 説明: 課題担当者の一意の識別子 (ディレクトリとは無関係) 例: |
| assignee_name | タイプ: 文字列 説明: 課題担当者の名前 例: スキーマ: バージョン 1 のみ。このデータは Users ファイルに含まれています。 |
| ステータス | タイプ: 文字列 説明: この課題の現在のステータス 例: |
| status_category | タイプ: 文字列 説明: この課題に関する現在のステータスのステータス カテゴリー 例: |
| priority_sequence | タイプ: 文字列 説明: 優先順位 (管理者はこれを変更できるため、仮決まりの優先順位の順序になります) 例: |
| priority_name | タイプ: 文字列 説明: この課題の優先順位の名前 例: |
| resolution | タイプ: 文字列 説明: 課題の最終ステータス。Jira は [解決状況] フィールドに値が存在すると、課題のワークフローが完了したと見なします。 例: |
| watcher_count | タイプ: 数値 説明: この課題をウォッチしているユーザー数 例: |
| vote_count | タイプ: 数値 説明: この課題の投票数 例: |
| created_date | タイプ: 日付 説明: この課題の UTC タイムゾーンにおける作成日 (ISO 文字列) 例: |
| resolution_date | タイプ: 日付 説明: この課題の UTC タイムゾーンにおける解決日 (ISO 文字列) 例: |
| updated_date | タイプ: 日付 説明: 課題が最後に更新された UTC タイムゾーン日付 (ISO 文字列) 例: 2020-11-05T14:44:57Z |
| due_date | タイプ: 日付 説明: 課題が完了する予定の UTC タイムゾーン日付 (ISO 文字列) 例: |
| 見積 | タイプ: 数値 説明: 初期見積から残り時間を秒単位で推定します (タイム トラッキングを有効にする必要があります)。 例: |
| original_estimate | タイプ: 数値 説明: 秒単位で設定された初期見積 (タイム トラッキングを有効にする必要があります) 例: |
| time_spent | タイプ: 数値 説明: 記録された作業量 (秒単位) (タイム トラッキングを有効にする必要があります)。消費時間がない場合、フィールドは null になります。 例: |
| labels | タイプ: 文字列 説明: ラベル名の JSON 配列。ラベルがない場合、フィールドは null になります。 例: |
| コンポーネント | タイプ: 文字列 説明: コンポーネント名の JSON 配列。ラベルがない場合、フィールドは null になります。 例: |
| parent_id | タイプ: 数値 説明: 親課題の ID。課題がサブタスクでない場合、フィールドが null になります。 例: |
| environment | タイプ: 文字列 説明: 課題が発生した環境の簡単な説明 (例: 例: |
| apected_versions | タイプ: 文字列 説明: 影響を受けるバージョン名の JSON 配列。ラベルがない場合、フィールドは null になります。 例: |
| fix_versions | タイプ: 文字列 説明: 修正バージョン名の JSON 配列。ラベルがない場合、フィールドは null になります。 例: |
| security_level | タイプ: 文字列 説明: セキュリティ レベル名。注: これは、データ エクスポート間で変更される可能性があります。 例: |
| タイプ: 数値 説明: 課題をアーカイブしたユーザーの一意の ID (ディレクトリとは無関係)。 例: スキーマ: バージョン 1 以降 (Jira 8.19 以降が必要) |
| タイプ: 日付 説明: この課題がアーカイブされた UTC タイムゾーン日付 (ISO 文字列)。 例: スキーマ: バージョン 1 以降 (Jira 8.19 以降が必要) |
フィールド スキーマ
Jira Software Jira Service Management
issue_fields CSV ファイルにエクスポートされて、すべてのカスタム フィールドは別の行に表示されます。カスタム フィールドを対応する課題にマッピングするには、このファイルから issue_id を使用して、その課題ファイルから一致する ID を探します。一般的に、ユーザーが生成したカスタム フィールドとアプリによって提供されるフィールドは、エクスポート可能なタイプ (フィールド implement ExportableCustomFieldsType) である限り含まれます。
カスタム フィールドに値が含まれない場合は、エクスポートされません。
| フィールド | 説明 |
|---|---|
| issue_id | タイプ: 数値 説明: 課題データ スキーマ内の対応する課題にリンクする ID 例: |
| field_id | タイプ: 文字列 説明: Jira Software フィールドと Jira Service Management フィールドの事前設定された ID。 例: |
| field_name | タイプ: 文字列 説明: フィールドの名前 例: |
| field_value | タイプ: 数値、文字列、JSON 配列 説明: フィールドの値 例: |
| 次の Jira Software フィールドは、エピックに関連していません。 | |
| sprint | タイプ: JSON 説明: 課題が現在発生している、または以前から発生していたスプリント。すべての日時は UTC タイムゾーンで ISO 文字列としてフォーマットされます。 例: |
| epic_link_id | タイプ: 数値 説明: この課題にリンクされているエピックの ID 例: |
| story_points | タイプ: 数値 説明: この課題に関連付けられているストーリー ポイントの数 例: |
| 次の Jira Software フィールドは、エピックに関連しています。 | |
| pic_color | タイプ: 文字列 説明: エピックの色 例: |
| epic_name | タイプ: 文字列 説明: エピックの名前 例: |
| epic_status | タイプ: 文字列 説明: エピックのステータス 例: |
| Jira Service Management に関連するフィールドは以下のとおりです。 | |
| customer_request_type | タイプ: 文字列 説明: JSM カスタマー リクエストのカスタマー リクエスト タイプ 例: |
| 組織 | タイプ: 文字列 説明: 特定の JSM 課題に割り当てられた組織のリスト。組織とは管理者が顧客を分類できるエンティティです。 例: ["org1", "org2"] |
| request_participants | タイプ: 数値 説明: 特定の JSM 課題のリクエスト参加者として割り当てられたユーザー ID のリスト。 例: スキーマ: バージョン 2 以降 |
| satisfaction_comment | タイプ: 文字列 説明: JSM 課題満足度調査の一環として入力されたコメント 例: |
| satisfaction_rating | タイプ: 文字列 説明: JSM 課題満足度調査の一環として入力された評価 例: |
| satisfaction_scale | タイプ: 文字列 説明: 特定の満足度の基準となる尺度 (最大評価) 例: |
| satisfaction_date | タイプ: 日付 説明: 満足度調査が完了した日付 例: |
課題履歴スキーマ
Jira Software Jira Service Management
issue_history CSV ファイルにエクスポートされます。エクスポートの fromDate 後の履歴のみが含まれます。issue_id フィールドを使用して、このテーブルを Issues テーブルと Fields テーブルに結合します。
| フィールド | 説明 |
|---|---|
| タイプ: 数値 説明: この課題の一意の ID。この課題テーブルにある対応する課題にリンクします。 例: |
| タイプ: 数値 説明: 同時に行われた変更や一連の変更の ID。フィールドと組み合わせて、1 つの変更を識別します。 例: |
| タイプ: 数値 説明: 変更を行ったユーザーの一意の ID。 例: |
| タイプ: 文字列 説明: 変更の作成者の一意の ID を一意の文字列として指定します。 例: |
| タイプ: 日付 説明: この変更 (ISO 文字列) の UTC タイムゾーンの日付。分単位に切り捨てられます。 例: |
| タイプ: 文字列 説明: 変更されたフィールドの名前。 例: assignee (担当者) |
| タイプ: 数値 説明: 変更されたフィールドのタイプ (Jira またはカスタム) 例: |
| タイプ: 文字列 説明: 変更前のフィールドの値の ID。2000 文字以内。 例: |
| タイプ: 文字列 説明: 変更前のフィールドの値 (文字列型)。2000 文字以内。 例: |
| タイプ: 文字列 説明: 変更後のフィールドの値の ID。2000 文字以内。 例: |
| タイプ: 文字列 説明: 変更後のフィールドの値を文字列として指定します。2000 文字以内。 例: |
| タイプ: 文字列 説明: 変更に関連する追加情報 (JSON 形式)。 例: |
課題履歴のエクスポートには時間がかかります。また、課題の詳細の取得後、課題が更新される可能性もわずかながらあります。これによって、課題ファイルの更新日が課題履歴ファイルの最終変更よりも前になる場合があります。
新しいエンティティ (新しい課題リンクなど) を作成すると、from / from_string フィールドは空になり、to / to_string フィールドは作成時の値になることにご注意ください。エンティティを削除すると、from / from_string と to / to_string の各フィールドは空の値になります。値を変更すると、両側に値が表示されるはずです。
課題リンク スキーマ
Jira Software Jira Service Management
issue_links CSV ファイルにエクスポートされます。フィールド | 説明 |
|---|---|
| タイプ: 数値 説明: 元の課題の一意の ID。 例: |
| タイプ: 数値 説明: 目的の課題の一意の ID。 例: |
| タイプ: 数値 説明: 課題リンク タイプの一意の ID。 例: |
| タイプ: 数値 説明: blocks、duplicates、relates to などの課題リンク タイプ。 例: |
ユーザー スキーマ
Jira Software Jira Service Management
users CSV ファイルにエクスポートされます。フィールド | 説明 |
|---|---|
| タイプ: 文字列 説明: ユーザーの ID 例: スキーマ: バージョン 2 以降 |
| タイプ: URL 説明: 現在のインスタンスのベース URL。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: ユーザーのユーザー名 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: ユーザーの氏名。 例: スキーマ: バージョン 2 以降 |
| タイプ: メール 説明: ユーザーのメール アドレス 例: スキーマ: バージョン 2 以降 |
無効なユーザー アカウントはエクスポートに含まれません。
SLA サイクル データ スキーマ
Jira Service Management
sla_cycles CSV ファイルにエクスポートされます。各課題には複数の SLA が適用される場合もあります。各 SLA のサイクル (Ongoing や Completed) は、個別の行に表示されます。対応する課題に SLA をマッピングするには、このファイルの issue_id を使用して課題ファイルから一致する ID を探します。| フィールド | 説明 |
|---|---|
| issue_id | タイプ: 数値 説明: 課題データ スキーマ内の対応する課題にリンクする ID 例: |
| sla_id | タイプ: 数値 説明: SLA サイクルが属する SLA の ID 例: |
| sla_name | タイプ: 文字列 説明: サイクルが属する SLA の名前。 例: |
| cycle_type | タイプ: 文字列 説明: 現在の SLA が 例: |
| start_time | タイプ: 日付 説明: SLA サイクルが開始された時刻のタイムスタンプ 例: |
| stop_time | タイプ: 日付 説明: SLA サイクルの 例: |
| paused | タイプ: ブール 説明: SLA サイクルが一時停止しているかどうかを示します。真、偽、または空にできます。 例: |
| remaining_time | タイプ: 数値 説明: 予定の SLA 上限を超過するまでの残り時間 (ミリ秒)。残り時間は 30 分ごとに計算されて更新されます。そのため、出力された値はその時点での実際の残り時間を表していない場合があります。 例: |
| elapsed_time | タイプ: 数値 説明: SLA サイクル開始時からの経過時間 (ミリ秒)。 例: |
| goal_duration | タイプ: 数値 説明: 現在のサイクルを完了するのに要した時間 (ミリ秒)。 例: |
承認スキーマ
Jira Service Management
approvals_<job_id>_<schema_version>_<timestamp>.csv CSV ファイルにエクスポートされます。フィールド | 説明 |
|---|---|
| タイプ: 数値 説明: 課題の一意の ID (外部キー)。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: 承認が必要なワークフロー ステージ。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: 承認の現在の状態。 例: スキーマ: バージョン 2 以降 |
| タイプ: 日付 説明: この課題が承認を要求した UTC タイムゾーンの日付 (ISO 文字列) 例: スキーマ: バージョン 2 以降 |
| タイプ: 日付 説明: 承認ステップが完了した UTC タイムゾーンの日付 (ISO 文字列) 例: スキーマ: バージョン 2 以降 |
| タイプ: ブール 説明: 承認の決定がシステムによって自動で行われたか ( 例: スキーマ: バージョン 2 以降 |
| 型: JSON 配列 説明: リクエストを承認したユーザーの一意の ID。 例: スキーマ: バージョン 2 以降 |
| 型: JSON 配列 説明: リクエストを却下したユーザーの一意の ID。 例: スキーマ: バージョン 2 以降 |
| 型: JSON 配列 説明: 承認者としてリストされたが、リクエストを承認または却下しなかったユーザーの一意の ID。 例: スキーマ: バージョン 2 以降 |
定型返信スキーマ
Jira Service Management
canned_responses_<job_id>_<schema_version>_<timestamp>.csv CSV ファイルにエクスポートされます。フィールド | 説明 |
|---|---|
| タイプ: 数値 説明: 定型返信の一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: プロジェクトの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: 定型返信が関連付けられているサービス デスクの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: 定型返信のタイトル。 例: スキーマ: バージョン 2 以降 |
| タイプ: 日付 説明: 定型返信が最後に更新された UTC タイムゾーン日付 (ISO 文字列) 例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: 定型返信が使用された回数。 例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: 定型返信を作成したユーザーの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: 定型返信を最終更新したユーザーの一意の ID。 例: スキーマ: バージョン 2 以降 |
ナレッジ ベース スキーマ
Jira Service Management
knowledge_base_<job_id>_<schema_version>_<timestamp>.csv CSV ファイルにエクスポートされます。フィールド | 説明 |
|---|---|
| タイプ: 数値 説明: このナレッジ ベースが接続されているプロジェクトのキー。 例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: ナレッジ ベース スペースが関連付けられているサービス デスクの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 日付 説明: イベントの時刻。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: イベントのキー、次が含まれます。
例: スキーマ: バージョン 2 以降 |
| タイプ: 数値 説明: Confluence ナレッジ ベース記事の一意のページ ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: Confluence スペースの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: Confluence ナレッジ ベース記事のページ タイトル。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: Jira アプリケーションと Confluence を接続するアプリケーション リンクの一意の ID。 例: スキーマ: バージョン 2 以降 |
| タイプ: 文字列 説明: ナレッジ ベース記事が共有された Jira 課題の一意のキー。 例: スキーマ: バージョン 2 以降 |