パフォーマンスおよび拡張のテスト
アトラシアンでは Jira の各リリースで、最新の Jira バージョンを過去のものと比較するパフォーマンスおよびスケーリング レポートを公開しています。このレポートには、さまざまなデータ次元 (カスタム フィールド、課題、プロジェクトなどの数) による Jira への影響についての結果も記載しているため、Jira のスケーリングで最良の結果を実現するために制限すべきデータ次元の判断に役立ちます。
これは Jira 8.15 のレポートです。他のレポートをお探しの場合、右上でバージョンを選択してください。
はじめに
一部の Jira 管理者は Jira の拡張方法について考えたとき、1 つの Jira インスタンスが保有できる課題数に焦点を与えることがよくあります。ただし、Jira インスタンスの規模を決める要因は課題数のみではありません。大きなインスタンスの実行方法について理解するには、複数の要因を検討する必要があります。
このページでは、異なるバージョンや構成で Jira を実行する方法について説明します。そのため、あなたがニーズの拡大に合わせて Jira を拡大する方法について理解する新人 Jira エバリュエータであっても、Jira を次のレベルに進めることに関心を持つ熟練した Jira 管理者であっても、このページが役に立ちます。
次の 2 つも主なアプローチを組み合わせ、組織全体で Jira を拡大することができます。
- 1 つの Jira インスタンスを選択します。
- Jira のクラスタリングを提供する Jira Data Center を使用します。
ここでは Jira を最大限活用するための、両方のアプローチに共通の手法について説明します。Jira Data Center の詳細や、同時負荷状態でのパフォーマンスを改善する方法については、Jira Data Center のページを参照してください。
1 つの Jira インスタンスの規模を決定する
組織内の Jira のパフォーマンスに影響を与える可能性のある要因は複数あります。これらの要因は次のカテゴリーに分類されます (特定の順序はありません):
- データ サイズ
- 課題、コメント、および添付ファイルの数
- プロジェクトの数。
- Jira プロジェクト属性の数 (カスタム フィールド、課題タイプおよびスキーム)。
- Jira やグループに登録されているユーザー数。
- ボード数、およびボード上の課題数 (Jira Software を使用している場合)
- 使用パターン
- Jira を同時に使用しているユーザー数。
- 同時操作の数。
- 電子メール通知の量。
- 構成
- プラグインの数 (一部は独自のメモリ要件を持っている場合がある)。
- ワークフロー ステップ実行の数 (移行や事後操作など)。
- ジョブの数とスケジュールされたサービス。
- デプロイメント環境
- 使用されている Jira のバージョン。
- Jira が実行されているサーバー。
- 使用されているデータベースとデータベースへの接続性。
- オペレーティングシステム (ファイルシステムを含む)。
- JVM 構成。
このページは、データベースに保存されているデータのサイズや特徴によって、Jira の速度がどのように影響を受けるかを示しています。
Jira 8.15 のパフォーマンス
Jira 8.15 はパフォーマンスのみに焦点を当てたバージョンではありませんでしたが、各リリースでは同等かそれ以上のパフォーマンスを提供することを目指しています。このセクションでは、以前の長期サポート リリースであった Jira 8.14 と Jira 8.15 を比較します。同じ広範囲のテスト シナリオを両方の Jira バージョンに対して実行しました。シナリオ間の違いは Jira のバージョンのみです。
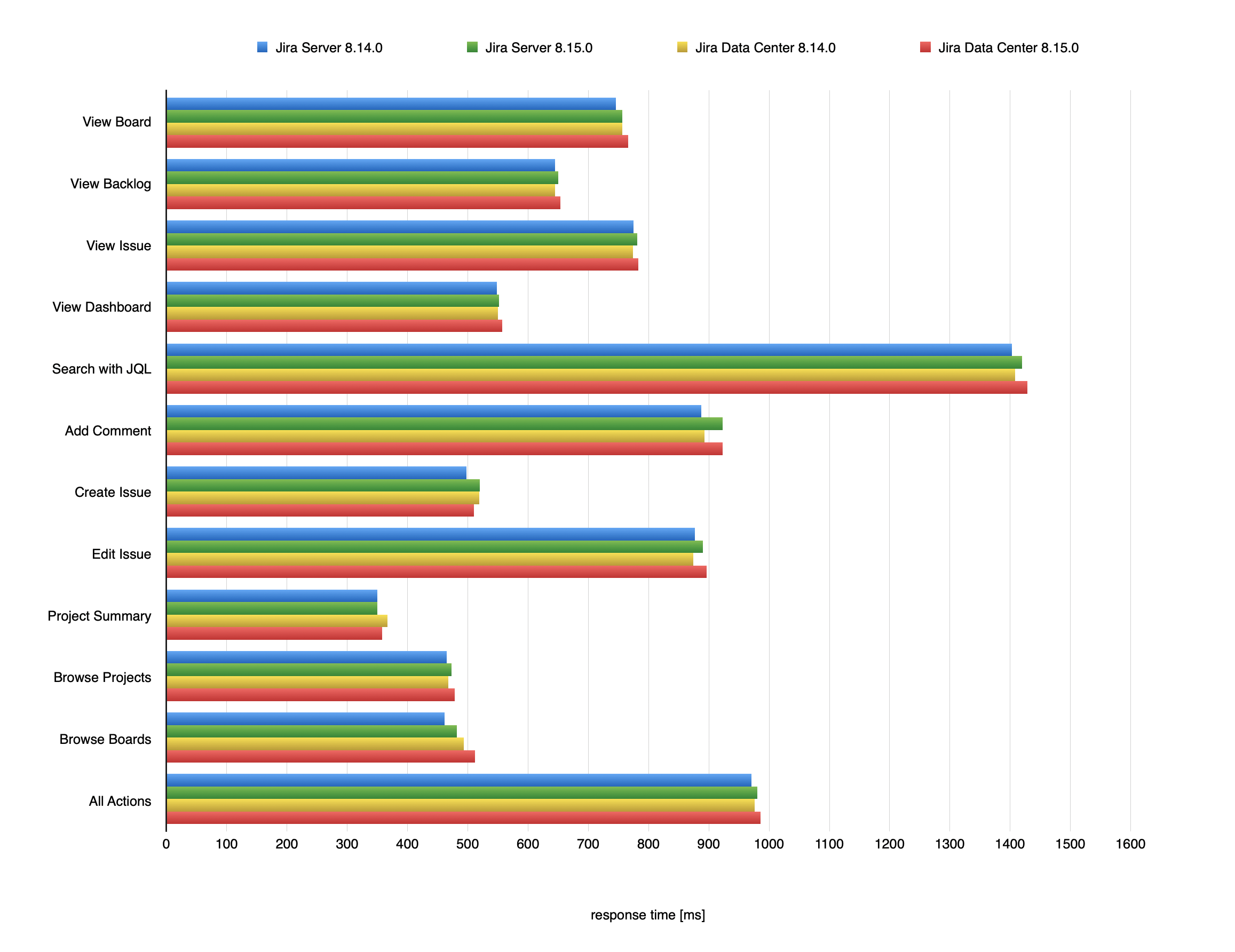
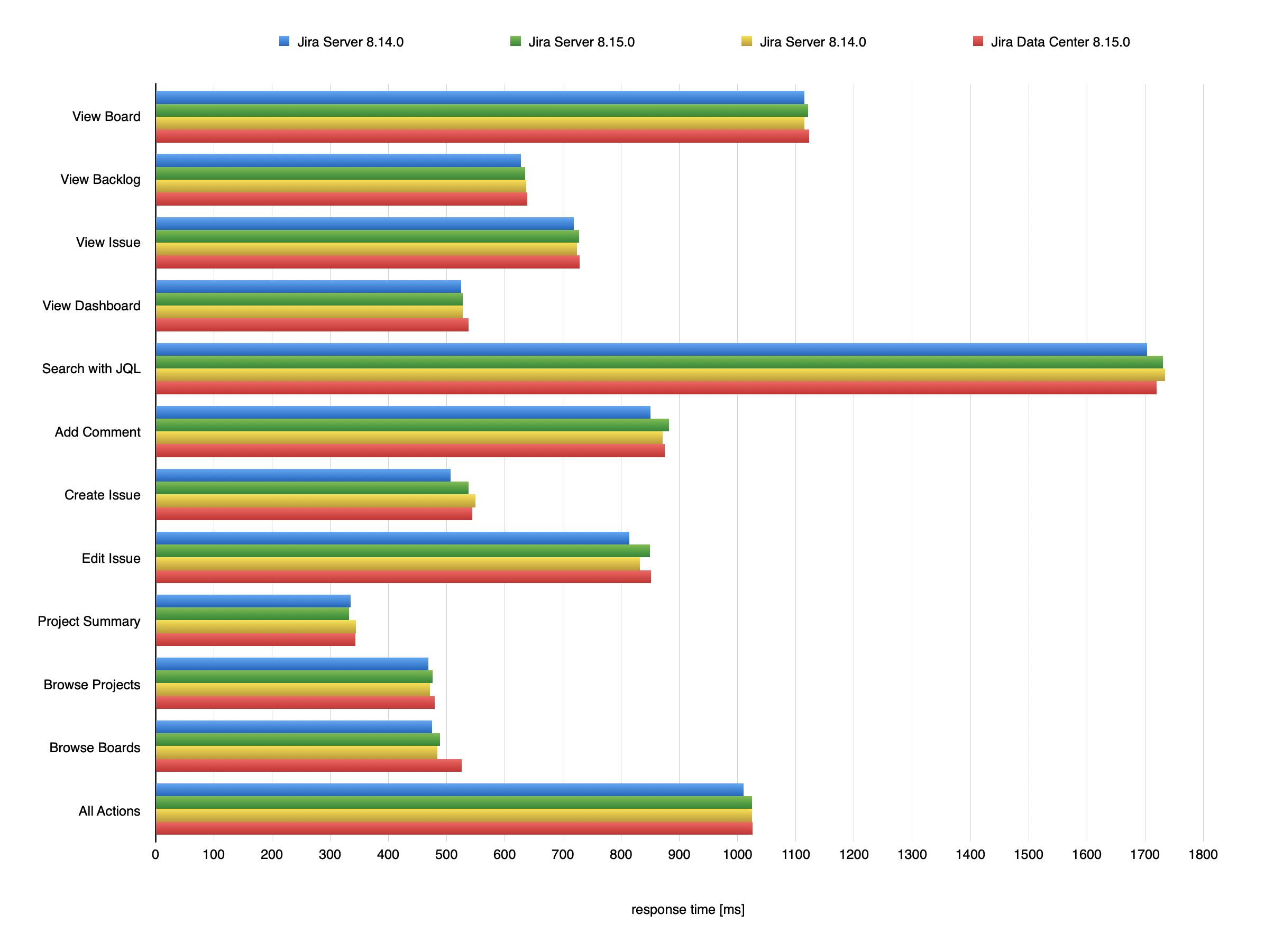
次のグラフは、Jira で実行された各種操作の平均応答時間を示しています。これらの操作と対象の Jira インスタンスの詳細については、「テスト手法」を参照してください。
Jira 操作の応答時間
Jira 8.14.0 と Jira 8.15.0 の比較
100 万件の課題
200 万件の課題
テスト手法
以下のセクションでは、当社のパフォーマンス テストで使用するテスト環境 (ハードウェア仕様を含む) とテスト方法を詳しく説明します。
Jira 8.14 の拡張性
Jira は柔軟なため、顧客の構成にはとてつもない多様性があります。Analytics データは、ほとんどの顧客データセットが、独自の特性を示していることを示します。異なる Jira インスタンスは、各データ ディメンションの異なる比率で増加します。いくつかのディメンションは他のディメンションより大幅に大きくなることが多くあります。たとえば、課題数が急速に増加する一方、プロジェクト数は一定数を維持することがあります。また、別の事例では、カスタム フィールドが膨大なのに、課題数が少なくなる場合があります。
多くの組織には独自のプロセスやニーズがあります。これらのさまざまな使用事例をサポートできる Jira の能力が、データセットの多様性の理由となっています。ただし、各データ ディメンションは Jira の速度に影響を与える可能性があります。多くの場合、これらの影響は一定または直線的ではありません。
それぞれの Jira インスタンス ユーザーに最適な体験を提供し、パフォーマンスの低下を防ぐため、どの Jira データ属性がアプリケーションの速度にどのような影響を与えるかを理解することが重要です。このセクションでは、各種設定値の相対的な影響を調査した Jira 8.15 拡張性テストの結果を示します。
テスト方法
- テスト用の参照として、「テスト方法論」で指定したベースライン データ セットとともに Jira 8.14 インスタンスを使用し、フル パフォーマンス テスト サイクルを実施しました。
- データ ディメンションとそれらのパフォーマンスへの影響に焦点を当てるため、個々の操作はテストしていませんが、代わりにパフォーマンス テストからのすべての操作の平均を使用しました。
- 次にベースライン データ セットで各属性を 2 倍にし、ベースライン データ セットのその他すべての値はそのままで、2 倍になった値に対して独立したパフォーマンス テストを実施しました (例:課題数を 2 倍、またはカスタム フィールド数を 2 倍にしてテストを実行)。
- 次に、データ セットを 2 倍にしたときのテスト サイクルの応答時間を参照結果と比較しました。このアプローチにより、個別の Jira 構成アイテムのサイズの増加が (すでに大規模な) Jira インスタンスの速度にどのように影響するかを、隔離した環境で観測できました。
Jira データ セットの応答時間
Jira 8.14.0 と Jira 8.15.0 の比較

データ セットが異なる場合でも、応答時間は Jira のバージョン間ではほぼ同じであり、上の画像にあるような違いは、ほとんどの場合、10ms (1 ~ 2%) を超えることはありません。Server (プロジェクト、アジャイル ボード) のいくつかのデータ セットでは、応答時間が最大で 34ms、Data Center (アジャイル ボード) では 16ms 増加しましたが、ほとんどのデータセットでは 10ms 以下にとどまっています。
その他のリソース
課題をアーカイブする
課題の数は Jira のパフォーマンスに影響するため、不要になった課題のアーカイブが望ましい場合があります。また、Jira のビューに多数の課題が表示され、不要になった古い課題をインスタンスからアーカイブしたい場合があります。「プロジェクトのアーカイブ」を参照してください。
ユーザー管理
Jira ユーザー ベースが増加すると、以下を確認する必要が出る場合があります。
- 認証、ユーザー、グループ管理のために Jira をディレクトリに接続します。
- ユーザー管理のために Crowd または別の Jira Server に接続する 。
- 他のアプリケーションに対し、ユーザー管理のために Jira への接続を許可する。
Jira ナレッジベース
パフォーマンス関連のトピックの詳細なガイドラインについては、Jira ナレッジベースの「Jira サーバーのパフォーマンスの問題のトラブルシューティング」の記事を参照してください。
Jira エンタープライズ サービス
経験豊富なアトラシアンから直接組織内の Jira の拡大のサポートが必要な場合は、プレミア サポートと技術アカウント管理サービスをご利用ください。
ソリューションパートナー
お住まいの地域のアトラシアン エキスパートも、お客様の環境での Jira の拡大をサポートできます。