Fisheye search not working on files with UCS-2 encoding
プラットフォームについて: Server および Data Center のみ。この記事は、Server および Data Center プラットフォームのアトラシアン製品にのみ適用されます。
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Fisheye および Crucible は除く
問題
Fisheye search will not find text in files with UCS-2 encoding.
No errors are written in the logs.
診断
環境
- Replicated with Subversion (at least), version 1.9.5
- Running Fisheye/Crucible 4.3.1
Diagnostic Steps
- For example, let's use the HelloWorld.cs file attached to this article.
Download it and add it to Subversion version control:
$ svn add HelloWorld.cs A (bin) HelloWorld.csNote that the output above mentions the files have been added as binary. To double-check that:
$ svn propget svn:mime-type HelloWorld.cs application/octet-streamModify their mime-type to text/plain so that Fisheye can show their content:
$ svn propset svn:mime-type text/plain HelloWorld.cs property 'svn:mime-type' set on 'HelloWorld.cs'Commit the file:
$ svn commit -m "Committing HelloWorld.cs with text/plain mime type" Sending HelloWorld.cs Committing transaction... Committed revision 18.- Wait until it is shown in Fisheye:

- Navigate to their source code, by opening http://localhost:8060/browse/SVN/trunk/HelloWorld.cs?r=18.
- Search (
COMMAND+F/CTRL+F) for the termWriteLine, and note that this term can be found in the source. - Now try to use Fisheye's search box at the top right corner in order to search for these same terms, and note that no results will be found:

- The problem persists even if
text/plain;UTF-16encoding is set to the file. - Open any other UTF-8 file committed, choose a term to search for, then use Fisheye's search box for searching for that chosen term, and note that search will work as expected.
原因
The problem lays on Lucene indexing: during this step files are always read using UTF-8; because of different encodings, each letter is indexed separately (see screen below)
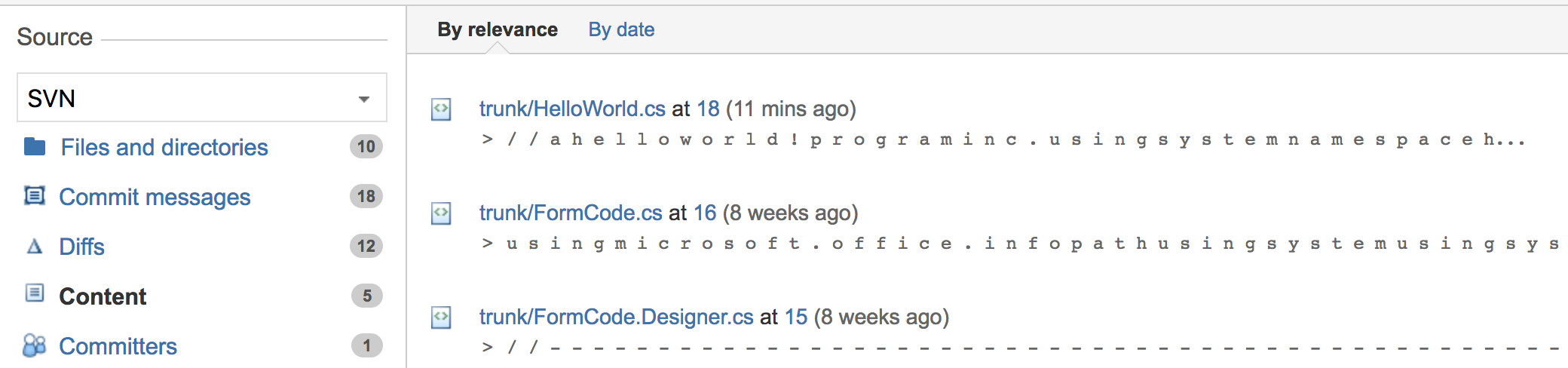
This feature is being tracked at FE-4477 - Getting issue details... STATUS .
回避策
- Change the file encoding to
UTF-8and commit it again. This will not fix the problem with already indexed files, but future revisions will be indexed properly.
ソリューション
- There is no immediate solution for this problem.