Bitbucket Data Center のサンプル デプロイメントおよび監視戦略
アトラシアンでは、エンタープライズ規模の複数の開発ツールを使用しています。その中でも Bitbucket Data Center インスタンスは、6,500 ユーザーに対するグローバル ソース コード管理のニーズを満たして、月間最大 900,000 件のビルドをサポートするようにデプロイされています。ピーク負荷時、インスタンスは 1 分あたり最大 300 ビルドを処理できます。
Bitbucket の使用の背景
この Bitbucket Data Center インスタンスは多くのアトラシアン アプリケーションを一か所にまとめるため、多数のユーザーがソース管理の要件を他のチームと統合しやすくなります。 2018 年 2 月の時点で、このインスタンスは 2,500 プロジェクトで約 6,500 リポジトリをホストしています。
非常に多くのユーザーが各拠点からこのインスタンスに依存しているため、このインスタンスで監視する優先的な項目に高可用性が挙げられます。同時に、インスタンスは継続的に健全な状態で動作する必要があります。健全性が失われると、他の連携アプリケーションにおける Git 関連の操作に影響し始める可能性があります。これは組織全体の生産性に影響を及ぼします。さらに、ここでの速度低下は連携された Bamboo ビルド サーバーのパフォーマンスに影響するため、ソフトウェアの予定通りの出荷にも影響します。
インフラストラクチャとセットアップ
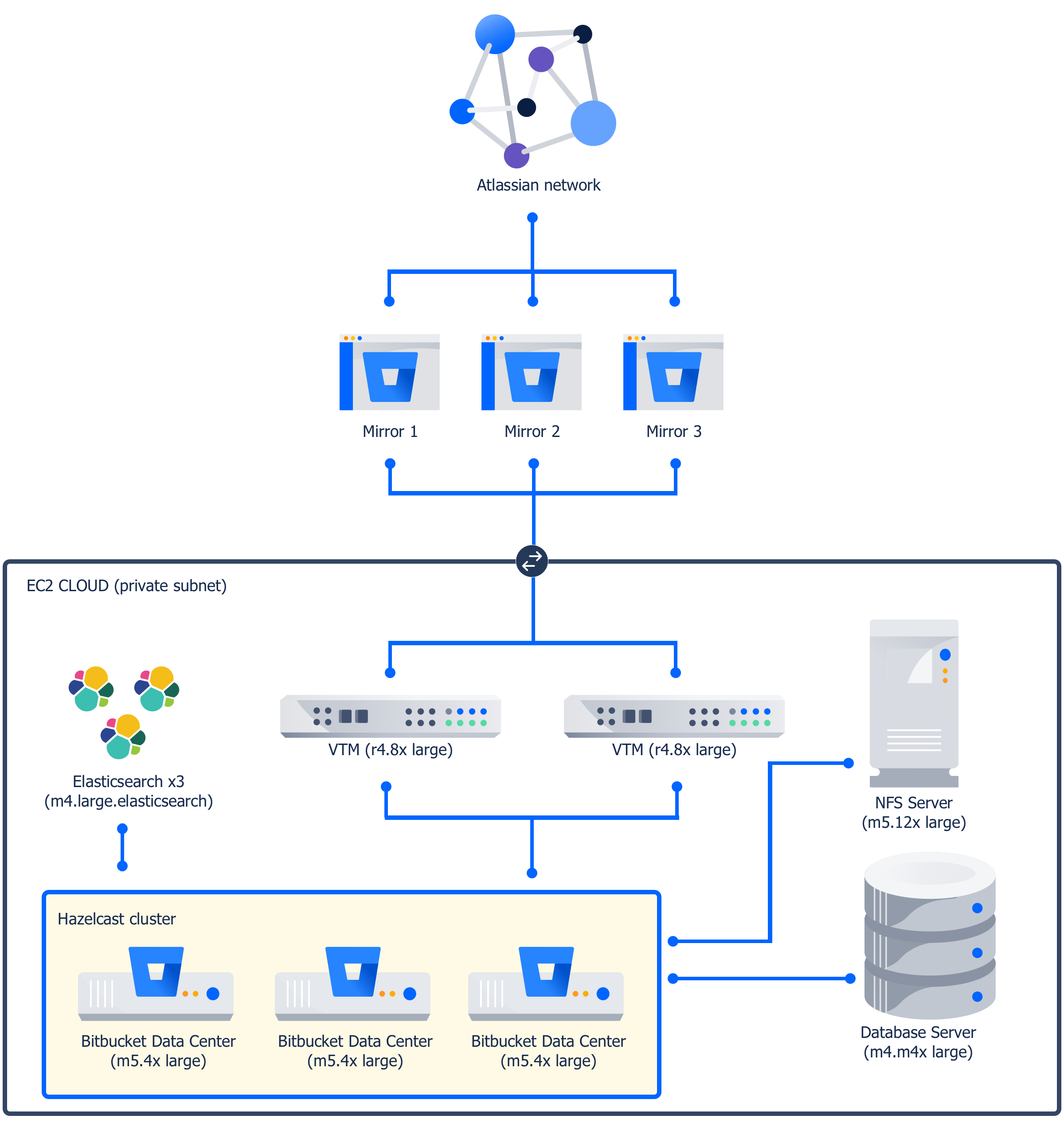
Atlassian の Bitbucket Data Center インスタンスは、次のノードで構成される、Amazon Web Services (AWS) 上の EC2 クラウドでホストされます。
| 機能 | インスタンス タイプ | 数値 |
|---|---|---|
| Bitbucket Data Center アプリケーション | m5.4xlarge | 3 |
| 専用 NFS サーバー | m5.12xlarge | 1 |
| 専用データベース (Amazon RDS Postgresql) | m4.2xlarge | 1 |
| 仮想トラフィック マネージャー | r4.8xlarge | 2 |
| Elasticsearch インスタンス | m4.large.elasticsearch | 3 |
Atlassian では AWS EC2 discovery plugin for Hazelcast を使用して、EC2 Cloud 内のノードを検出しています。3 つのミラーが、大部分のユーザーがいるリージョン全体でのトラフィック管理をサポートします。
実際のロード バランサの代わりに、必要な帯域幅の処理に適した 2 つのインスタンス上にホストされている専用の仮想トラフィック マネージャー を使用します。専用 NFS サーバーを使って、ページ キャッシュ用に大量の RAM を提供します。
各ノード タイプの詳細については、「インスタンス タイプに関する AWS ドキュメント (特に「汎用インスタンス」、および「メモリ最適化インスタンス」) をご参照ください。
インスタンスの Elasticsearchの詳細については、「Amazon Elasticsearch Service」 をお読みください。
連携サービス
Bitbucket Data Center インスタンスでは Crowd を使用してユーザー ディレクトリを管理しており、これは他のいくつかの Atlassian 製品とも連携されています。これには、次のパブリック Jira インスタンスが含まれます。
- http://getsupport.atlassian.com/
- http://jira.atlassian.com/
- https://www.atlassian.com/software/jira/service-desk
Bitbucket Data Center インスタンスは次のようにさまざまなアプリケーションへリンクされています。
21 個の Bamboo リンク
10 個の Jira リンク
3 個の Confluence リンク
2 個の FishEye / Crucible
また、このインスタンスには 30 個のアプリがインストールされ、有効化されています。
監視戦略
アトラシアンの監視戦略は、インスタンスが負荷の処理に十分なリソースを持っていることを確認することに焦点を当てています。これにより、ノード リソースの追加、ローリング スタートの実施、またはその他の適切な修正などを行うことで、多くの場合 Git 関連の操作のボトルネックを素早く解決できます。これはインスタンス全体でソース コントロールを堅牢に保つだけでなく、ソース コントロールに依存する統合サービスの速度の低下を防ぎます。
ほとんどの場合、これによってインスタンスのパフォーマンス レートが健全に保たれます。このレベルのパフォーマンスを保持できる場合、インスタンスに重大な障害が発生することは少なくなります。我々の経験では、これらの障害の原因のほとんどは、自身をホスティング チケット キューとして明示することです。したがって、これにアラートを設定しています (「一般的な負荷」を参照)。
また、アトラシアンでは、スプリット ブレイン シナリオの兆候となるイベントも監視しています。特に、Hazelcast リモート オペレーションの数と、過去の重大なレベルに対するアラートを監視しています (詳細は「ノード」を参照してください。
次の表は、インスタンスの各サブシステムの監視方法、アラート レベル (ある場合)、およびアラートがトリガーされたときにとるべき対応の詳細を示しています。これらの戦略は我々のセットアップ、スケール、およびユース ケースに固有のものです。
一般的な負荷
| 追跡するメトリック | アラート レベル | アラートがトリガーされたときの対応 |
|---|---|---|
ホスティング チケット。Bitbucket ではチケットを使用して、システムがリクエストで過負荷になるのを防ぎます。ホスティング チケットは、同時に実行される可能性がある ソース コントロール管理 (SCM) ホスティング オペレーションの数を制限します。SMC ホスティング オペレーションは、HTTP または SSH を介した Git プッシュまたはプルで構成されます。 | ホスティング チケットが 5 分間キューに残っている。ホスティング チケット キューに 5 分間チケットがあった場合、アラートがトリガーされます。これは通常、負荷が高すぎるか、インスタンスが十分にチケットを処理していないことを意味します。 | 負荷の高さとインスタンスの速度低下のどちらが原因でキューが発生しているかをチェックします。後者の場合、インスタンスで利用可能なリソースを増やします (関連する詳細は、「Bitbucket がリソースの制限に達しつつある」を参照してください)。 インスタンスの速度が遅い場合、他のサブシステム (JVM、ノード、Git プロセス、またはデータベース) を調査して根本原因を判断します。 |
| アクティブなデータベース接続の数。このメトリックは、サービスにボトルネックがあるかどうかを示すのに役立ちます。 | 5 分間に 50 以上のアクティブ データベース接続 (ノードあたり) がある。過去のパフォーマンス データを使用して、このアラートが、インスタンスが問題なく回復できる上限であると判断しました。ほとんどの障害は、5 分のマークを超えたところで発生しはじめます。 | アラートが表示されたら、他のメトリックを調査して差し迫った課題がないかどうかを確認します。ほとんどの場合、インスタンスは時間とともに単純に自己回復します。まれに、ローリング リスタートが必要になることがある、他のサブシステムの課題が見つかります。 ポリシー上、できるだけ早く最新バージョンにアップグレードします。これにより、各リリースでの安定性の改善を活用できるようになり、停止や不安定性のリスクは時間の経過とともに減少します。 |
スレッド プールの長さ: 特に、IoPumpThreadPool、ScheduledThreadPool、および EventThreadPool などの Bitbucket サーバー スレッドプールの長さを監視します。 Bitbucket インスタンスで誤動作しているアプリがスレッドプール上で長時間かかるタスクを実行し、これによってサービスに影響する場合があります。 | 5 分間でキューの長さが 40を超える。関連するカスタマー ケースのキューの長さを調査し、それに基づいてこのアラートを作成しました。 | このアラートがトリガーされた場合、まず最初に、トラブルの兆候がないかすべてのアプリをチェックします。問題が見られない場合、他のメトリックをチェックして、アラートがトリガーされていないかどうか (またはもうすぐでトリガーされるような状態になっていないか) を確認します。現時点では、我々のインスタンスでこのアラートがトリガーされたことはありません。 アプリによって生成されたアラートの表示および分析方法の詳細については、「サードパーティ アプリの診断」を参照してください。 |
ノード
| 追跡するメトリック | アラート レベル | アラートがトリガーされたときの対応 |
|---|---|---|
| CPU および RAM 利用状況。Git はリソース集約型であり、特に CPU や RAM を大量に消費する場合があるため、これらのメトリックを監視します。 | このメトリックに自動アラートはありません。代わりに、インスタンスの速度低下を評価できるよう、ホスティング チケットとまとめて監視しています。 | ホスティング チケットのアラートが高い CPU および RAM 使用量とともにトリガーされた場合は、インスタンスに利用可能なリソースを増やします (関連する詳細は、「Bitbucket がリソースの制限に達しつつある」を参照してください)。 |
| ディスクのレイテンシ。Git のパフォーマンスは、レイテンシに非常に影響されやすい場合があります。 | このメトリックに自動アラートはありません。代わりに、インスタンスの速度低下を評価できるよう、ホスティング チケットとまとめて監視しています。 | ディスク レイテンシの高さによってホスティング チケット アラートがトリガーされたら、ストレージ ハードウェアと接続をチェックします。また、パフォーマンス低下の原因となったインシデントを調査する際には、根本原因を判断するためにディスク レイテンシ データも確認します。 |
| Hazelcast: リモート オペレーションの数。これらのリクエスト数が多い場合、スプリット ブレイン シナリオの原因となるクラスター ネットワークの問題を示している可能性があります (「Data Center クラスターのスプリット ブレインからの回復」を参照)。 | >1000/秒 が 5 分以上続く。この値は一般的に、クラスター ネットワークの問題、または特定のイベント キューがバックアップされていることを示します。また、クラスターが、スプリット ブレイン シナリオから回復する際に問題が発生している可能性も示しています。 | このアラートがトリップされたら、Hazelcast クラスター ノードのローリング リスタートを直ちに実行します。なお、回復力や信頼性を向上させるため、Hazelnut プロジェクトに寄与しています。 |
アラートしないメトリック
以下のメトリックに関するアラートは設定されていませんが、異常なスパイクやディップは定期的に監視しています。
| 追跡するメトリック | 監視プラクティス |
|---|---|
HTTP リクエストのレイテンシ。 レイテンシの一般的な指標として、平均 HTTP 応答時間を監視します。 | これをパフォーマンス テスト サイクルの一部として監視しており、アラートの自動化は設定していません。重大なパフォーマンス レベルは別のアラート (特にホスティング チケット) をトリガーしますが、このメトリックはインスタンスのパフォーマンス レベルを素早くチェックするのに役立ちます。 重大な停止が発生した場合、根本原因を調査するためにこのメトリックで収集されたデータを調べます。 |
1 秒あたりの Git プッシュ/プル。 プッシュとプルは Git オペレーションの大部分を占め、インスタンスが受けている負荷の量を大まかに把握するのに役立ちます。 | Git プル (フェッチまたはクローン) は大量の CPU および RAM を消費するため、このメトリックを高い水準で監視しています。このメトリックの急増は、何かによってスループットが抑制されているか、システムに異常な負荷がかかっていることを意味します。 このメトリックに対するアラートは設定していません。これは、重大なレベルではホスティング チケットがキューに追加され始めますが、このアラートを既に設定しているためです。停止や類似のインシデントを調査する際には、このメトリックで収集されたデータを分析し、長期間にわたる一般的な利用状況/負荷と比較します。 アトラシアンでは JMX カウンターによってこのデータを収集しています。詳細は「パフォーマンス監視用に JMX カウンターを有効化」をご参照ください。 |
JVM ヒープ。 このメトリックの値が正常であれば、Bitbucket に十分なメモリがあります。 | このメトリックを監視する目的は、主に開発フィードバックです。また、このデータは Bitbucket にメモリ リークがあるかどうかを確認するのに役立ちます。 |
ガベージ コレクターによる CPU 使用率。 ガベージ コレクターが多くの CPU 時間をしているとき、多くの場合、パフォーマンスの速度低下が発生します。 | このメトリックを監視する目的は、主に開発フィードバックです。多くの場合、このデータはパフォーマンス低下の原因を見つけるのに役立ちます。 |
Atlassian が提供するサービス