Confluence セットアップ ガイド
以下に説明するように、Confluence のセットアップウィザードを開始する前に、Confluence インストールガイドを完了しておく必要があります。
ユーザーのウェブブラウザーから Confluence に初めてアクセスすると、Confluence セットアップウィザードが開始されます。これは、ユーザーサイトの Confluence に必要な設定を行うための一連の画面です。また、以前にインストールした Confluence からのデータの取得や復元を簡便に行う手段も提供します。また、以前にインストールした Confluence からのデータの取得や復元を簡便に行う手段も提供します。
1. セットアップウィザードの開始
- Confluence まだ実行していない場合は開始します。
Windows の場合、[スタート] > [すべてのプログラム] > [Confluence] > [Confluence サーバーを開始する] に進みます。
または、インストール ディレクトリのbinフォルダで次の起動スクリプトを実行します。start-confluence.bat(Windows)。start-confluence.sh(Linux ベースのシステム)。
- ご使用のブラウザで http://localhost:8090/ に移動し、
インストール時に別のポートを選択した場合は、 「8090」を指定したポートに変更します。
エラーになる場合、インストール時に指定したポートをしているかどうかを確認します。
On this page:
2. インストールの種類を選択する
このステップでは、トライアル版のインストールまたは本番環境インストールのいずれかを選択します。
- 試用版インストールライセンスを持たと初めて Confluence を試す場合は、
このオプションを選択します。外部データベースが必要です。
- 本番環境インストール
独自の外部データベースを使用して Confluence をセットアップします。このオプションは、本番環境で Confluence を設定する場合にお勧めします。
3. ライセンス キーを入力
プロンプトに従って評価ライセンスを生成するか、既存のライセンス キーを入力します。既存のライセンス キーを取得するには、my.atlassian.com に進みます。新しい商用ライセンスを購入するには、www.atlassian.com/buy に進みます。
前の手順でトライアル版のインストールを選択した場合は、Confluence によってライセンスが生成されます。この処理には数分かかります。完了したら、下記のステップ 8 に進みます。
本番環境インストールを選択した場合、次のステップに進み、外部データベースを設定します。
4. 本番環境インストール: データベースの設定
次は、データベースの設定です。以下に考慮事項を挙げます。
- サポート対象プラットフォーム 一覧をチェックして、 選択したデータベースとバージョンがサポート対象であることを確認します。
- UTF-8 文字エンコード要件など、データベースの設定に関する情報は、データベース設定 を参照してください。
- 本番環境システムとして Confluence を使用する場合、外部データベースを使用する必要があります。
- 組み込み H2 データベースは、非クラスタ (シングルノード) Confluence Data Center インストールでのテストおよびアプリケーション開発目的でのみサポートされます。。
スクリーンショット: データベースの設定

5. 本番環境インストール: 外部データベース
作業を開始する前に
- 文字のエンコード:
- 文字のエンコードは、データベース、アプリケーションサーバー、ウェブアプリケーション間で統一し、かつ UTF-8 を使用することを強く推奨します。
- データベースの設定を行う前に、 文字エンコードの設定についてをお読みください。
- データベース名: 新しい外部データベースを作成するときは、名前を 'confluence' としてください。
Confluence とデータベースを接続する方法として、 JDBC 直接接続とサーバー管理データソース接続のいずれかを選択します。
スクリーンショット: 接続オプション

直接 JDBC
標準の JDBC データベース接続を使用します。接続プールは Confluence 内で管理します。
- ドライバー クラス名 – 使用するデータベースドライバーの Java クラス名です。これは使用する JDBC ドライバーに依存しますので、データベースの説明書で確認してください。なお、 Confluence にもいくつかのデータベースドライバーが組み込まれていますが、組み込まれていないドライバーはユーザー自身でインストールする必要があります。詳細は「 データベース JDBC ドライバー 」をご覧ください。
- データベース URL – 接続先データベースの JDBC URL です。これは使用する JDBC ドライバーに依存しますので、データベースの説明書で確認してください。
- ユーザー名およびパスワード – Confluence がユーザーのデータベースにアクセスするために使用できる有効なユーザー名とパスワードです。
以下の情報も必要になります:
- Confluence が管理する接続プールのサイズ。不明な場合は標準値を使用してください。
- 接続先データベースの種類。これによって Confluence が使用する言語を指定します。
データソース
これは、アプリケーションサーバー (Tomcat) を経由してデータベースに接続する方法です。アプリケーションサーバーのデータソースはあらかじめ設定しておく必要があります。外部データベースの設定については、「データベース設定」を参照してください。
- データソース名 - アプリケーション サーバーで設定されている、データソースの JNDI 名です。
注意:jdbc/datasourcenameなどの JNDI 名を持つサーバーも、java:comp/env/jdbc/datasourcenameなどを持つサーバーもあります。アプリケーション サーバーのドキュメントをご確認ください。
以下の情報も必要になります:
- 接続先データベースの種類。これによって Confluence が使用する言語を指定します。
6. 本番環境インストール: コンテンツの読み込み
用意されているいくつかのデモンストレーション コンテンツを使用すると、新しい Confluence サイトの開始に役立ちます (これらのコンテンツは稼働開始後に削除できます)。または、空のサイトで続行してもかまいません。コンテンツを追加できるようにするには、まず、新しいサイトにスペースを作成する必要があります。
別の Confluence インストール環境から移行する場合は、バックアップから復元を選択して、既存の Confluence データをインポートします。
7. 本番環境インストール: バックアップからのデータの復元
このオプションによって、セットアップ プロセスの過程で、既存の Confluence インストールからデータをインポートできます。この操作を行うには、既存の Confluence インストールのマニュアル バックアップ ファイルが必要となります (既存の Confluence サイトの管理コンソールにある [バックアップと復元] に移動します)。
スクリーンショット:データオプションの復元
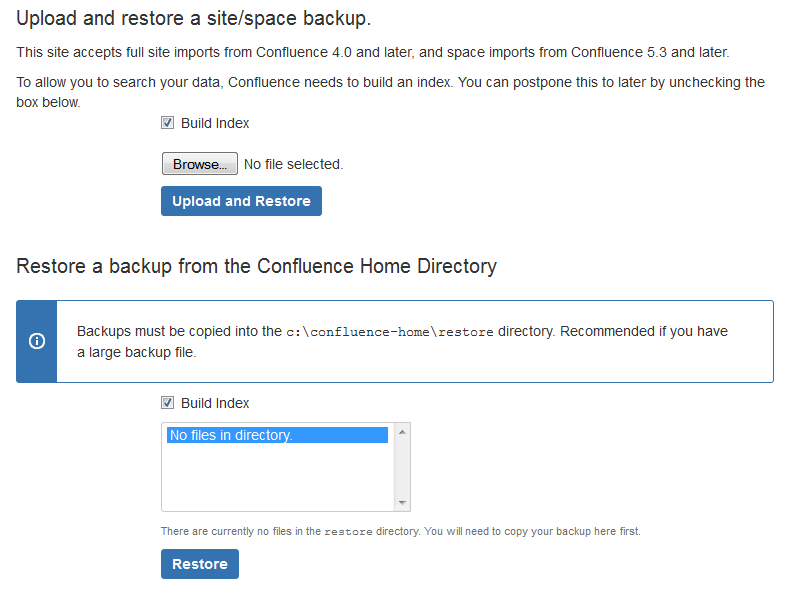
データの復元方法は 2 通りあります - ファイルをアップロードする、または、ご利用のファイルシステムから復元する。
- バックアップファイルをアップロード
このオプションでは、zip形式のバックアップファイルからデータをロードします。バックアップファイルのサイズが非常に大きい場合は、ファイルシステムから復元することをすすめします。プロンプトにしたがってバックアップファイルを開きます。検索インデックスを生成するため、確実に インデックスを作成 を選択してください。
ファイルシステムからバックアップファイルを復元
バックアップファイルが非常に大きい場合(100 mb 以上)または、バックアップファイルがすでに同じサーバー内に存在する場合は、このオプションの選択を推奨します。XML バックアップ ファイルを
<confluence-home>/restoreディレクトリにコピーします。バックアップ ファイルが一覧に表示されます。プロンプトにしたがってバックアップを復元します。検索インデックスを生成するため、[インデックスを作成] を選択するようにします。
復元処理が完了すると、Confluence にログインできるようになります。以前にインストールした Confluence から、システム管理者のアカウント情報をはじめとするすべてのユーザーデータとコンテンツのインポートが完了します。
8. ユーザー管理の設定
Confluence のユーザーおよびグループは、Confluence 内部か、Jira Software や Jira Service Management などの Jira アプリケーションで管理できます。
- Jira アプリケーションをインストールしていなかったり、後で外部のユーザー管理を設定したい場合は、Confluence のユーザーとグループの管理を選択します。
- Jira アプリケーションをインストール済みの場合、セットアップウィザードで Jira 接続を自動設定する機会があります。これは、ほとんどのオプションを標準条件とした状態で Jira との連携を設定するためのものです。Jira のユーザーディレクトリが Confluence で使用できるように構成され、Jira と Confluence の間で相互にアプリケーション リンクが設定されるため、データを容易に共有できます。Jira に接続 を選択してください。
9. Jira アプリケーションへの接続
詳細説明とトラブルシューティングについては、セットアップウィザードでJira統合の構成をご覧ください。
10. システム管理者アカウントの設定
システム管理者は Confluence インスタンスに関するすべての管理権限を持ちます。システム管理者は、ユーザーの追加、スペースの作成、Confluence に追加のオプション設定を行うことができます。詳細情報は、グローバル権限の概要参照してください。
Jira アプリケーションにユーザー管理を代行させた場合、アトラシアンは、ユーザーが指定した Jira システム管理者アカウントを Confluence のシステム管理者アカウントとして使用します。
11. 設定完了
Confluence が利用できるようになりました。 スタート をクリックし、Confluence を開きます。
管理コンソールに直接アクセスしてメールサーバーの設定、ユーザーの追加、ベース URL の変更、その他の管理者タスクを行う場合は、詳細設定 を選択します。