階層型ファイル システムによる添付ファイル ストレージ
Confluence 3.0 では、添付ファイルを保存する方法が大幅に変更されました。Confluence 2.10 以前からアップグレードする場合、推奨されるアップグレード パスについては「Confluence のアップグレード」を、新しいファイル システム構造への移行の詳細については Confluence 3.0 ドキュメントの「階層型ファイル システムによる添付ファイル ストレージ」ページご参照ください。
Confluence はファイルや画像などの添付ファイルをファイル システムに保存します。 Confluence の添付ファイル ストレージの構造は次のように設計されています。
- ディレクトリ構造の任意のレベルでエントリ数を制限できること (一部のファイル システムではディレクトリに格納できるファイル数に制限があるため)。
- スペースごとに添付ファイルを区分し、システム管理者が特定のスペースから添付ファイルを選択的にバックアップできるようにすること。
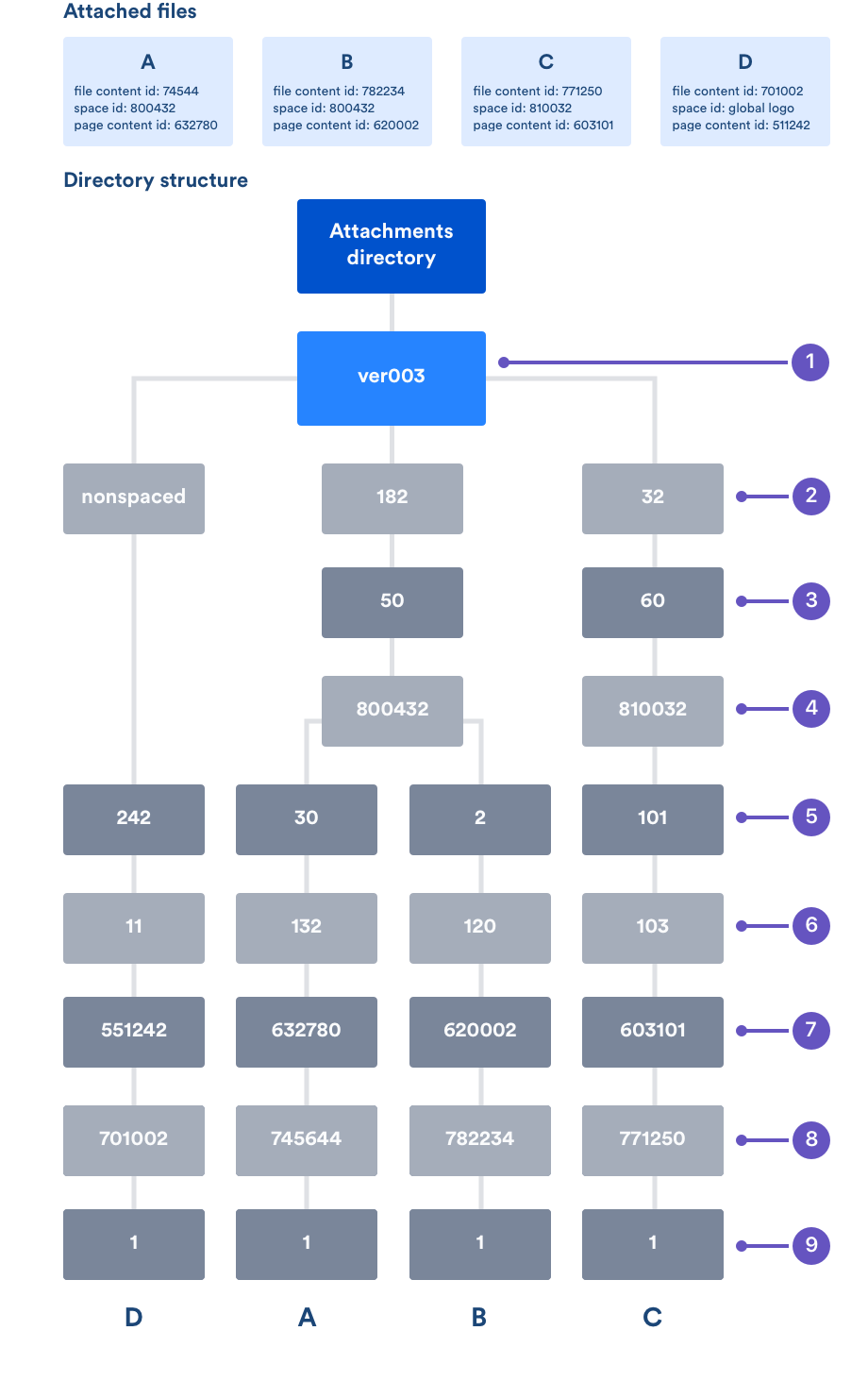
Confluence の添付ファイルには、ファイル自体のコンテンツ ID 、スペース ID 、ファイルが添付されているページのコンテンツ ID などのいくつかの識別属性があります。つまり、すべてのコンテンツが 1 つのスペースに属するのではなく、ファイルは 1 つのコンテンツに論理的に属し、そのコンテンツが 1 つのスペースに論理的に属します。Confluence のスペース内のファイルの場合、ディレクトリ構造は通常 8 レベルで、次のようなアルゴリズムに基づいて各ディレクトリ レベルに名前がつけられています。
レベル | 由来 |
|---|---|
1 (最上位) | 常に "ver003" で、Confluence バージョン 3 ストレージ フォーマットであることを示す |
2 | スペース ID の最下位 3 桁を 250 で剰余演算した結果 |
3 | スペース ID の次の下位 3 桁を 250 で剰余演算した結果 |
4 | 完全なスペース ID |
5 | ファイルが添付されたページのコンテンツ ID の最下位 3 桁を 250 で剰余演算した結果 |
6 | ファイルが添付されたページのコンテンツ ID の次の下位 3 桁を 250 で剰余演算した結果 |
7 | ファイルが添付されているページの完全なコンテンツ ID |
8 | 添付ファイルの完全なコンテンツ ID |
| 9 | ファイルのバージョン番号の名前を持つ、実際のファイル。例: 1, 2, 6。 |
剰余計算は、除算後の余りを見つけために使用されます。例: 800 modulo 250 = 50。
例:
特定のスペースの添付ファイルが保存されているディレクトリを検索するには、<confluence url>/admin/findspaceattachments.jsp にアクセスして、スペース キーを入力します。そのスペースの添付ファイルが保存されているファイル システム上のディレクトリが返されます。
上図のファイル D はすこし異なる構造で保存されています。概念的にはスペース内に存在しないファイルの場合、レベル 2 から 4 のディレクトリが "nonspaced" と呼ばれる単一のディレクトリで置き換えられます。このようなファイルの例としては、グローバルのサイト ロゴや未保存のコンテンツの添付ファイルなどがあります。
抽出されたテキスト ファイル
テキストベースのファイル (Word、PowerPoint など) が Confluence にアップロードされると、テキストが抽出され、インデックスが作成されます。これにより、ユーザーはファイル名だけでなく、ファイルのコンテンツを検索することができます。この抽出テキストは保存されるので、ファイルのインデックス再作成が必要な場合でも、ファイルのコンテンツを改めて抽出する必要がありません。
抽出されたテキスト ファイルにはバージョン番号を使用した名前が付けられ (例: 2.extracted_text)、ファイル バージョン自体とともに保存されます(上記の説明のレベル 8 内)。最新バージョンの抽出ファイルのみを保持し、以前のバージョンのファイルは保持されません。