ダウンタイムなしで AWS で Confluence クラスタをアップグレード
このドキュメントでは、CloudFormation によってオーケストレーションされた AWS デプロイでのローリング アップグレードの実行のステップバイステップの手順について説明します。特に、これらの手順は、AWS クイック スタートに基づく Confluence Data Center デプロイに適しています。
ローリング アップグレードの概要 (計画および準備情報を含む) については、ダウンタイムなしで Confluence をアップグレードを参照してください。
ステップ 1 - アップグレード モードの有効化
アップグレード モードを有効化するには、次の手順を実行します。
 > [一般設定] > [Rolling upgrades (ローリング アップグレード)] に移動します。
> [一般設定] > [Rolling upgrades (ローリング アップグレード)] に移動します。- アップグレード モード トグル (1) を選択します。
スクリーンショット: ローリング アップグレード画面。
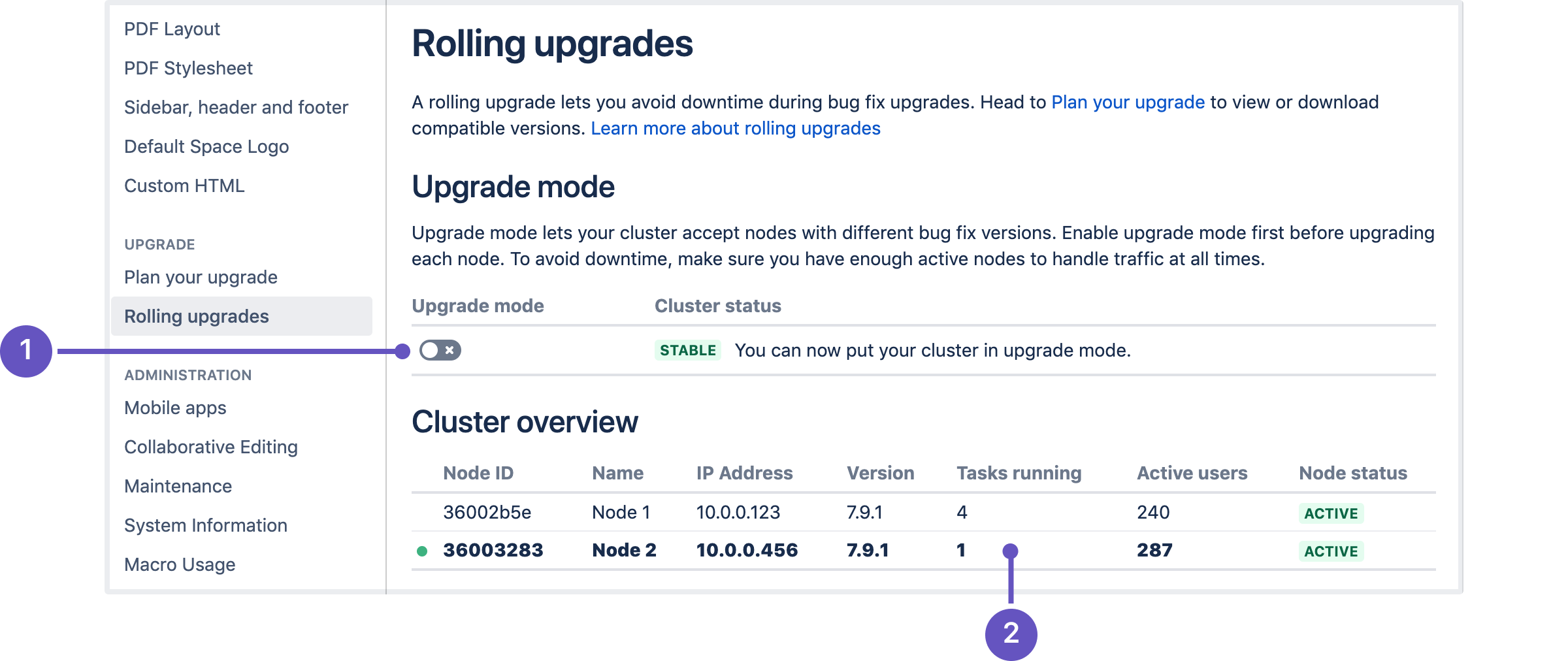
クラスタの概要は、最初にアップグレードするノードを選択する際に役立ちます。タスク実行中 (2) 列ではそのノードで長時間実行されているタスクの数が、[アクティブなユーザー] ではログイン済みのユーザー数が表示されます。最初にアップグレードするノードを選択する際は、実行中のタスク数とアクティブ ユーザーが最も少ないノードから始めましょう。
アップグレード モードでは、クラスタは異なる Confluence バージョンを実行しているノードを一時的に受け入れられます。これによって、1 つのノードをアップグレードして (アップグレードされていない他のノードと併せて) クラスタに再度追加できます。アップグレード済みとアップグレードされていないアクティブ ノードの両方が連携することで、すべてのユーザーが Confluence を使用できます。まだノードをアップグレードしていない場合は、アップグレード モードを無効化できます。
ステップ 2: スタック内の現在のすべてのアプリケーション ノードを見つける
AWS で、スタック内で実行中のすべてのアプリケーション ノードの Instance ID を記録します。これらはすべて、現在のバージョンを実行しているアプリケーション ノードです。後の手順でこれらの ID が必要となります。
AWS コンソールで、[Services] > [CloudFormation] に移動します。デプロイメントのスタックを選択してスタックの詳細を表示します。
- [Resources] ドロップダウンを展開します。[ClusterNodeGroup] を探し、その Physical ID をクリックします。Jira アプリケーション ノードの Auto Scaling Group の詳細を示すページが開きます。
- Auto Scaling Group の詳細で、[Instances] タブをクリックします。ここに表示されているすべての Instance ID を記録します。これらを以降のステップで終了します。
ステップ 3: CloudFormation テンプレートの更新
デプロイでは、環境の各コンポーネントを定義する CloudFormation テンプレートを使用します。この場合、Confluence をアップグレードすることは、テンプレートで使用されている Confluence のバージョンを更新することを意味します。アップグレード時には、クラスタにノードを一時的に追加することを強くお勧めします。
- AWS コンソールで、[Services] > [CloudFormation] に移動します。デプロイメントのスタックを選択してスタックの詳細を表示します。
- スタックの詳細画面で、[Update Stack] をクリックします。
- [Select Template] 画面で、[Use current template] を選択してから、[Next] をクリックします。
- Version パラメーターを、更新先のバージョンに設定します。これはローリング アップグレードなので、これより後のバグ修正バージョンにしか設定できません。
- 新しい Jira ノードをクラスタに追加します。これによって、クラスタでユーザー トラフィックに対するノードの不足が発生しにくくなります。これを行うには、次のパラメーターの値を 1 増やします。
- Maximum number of cluster nodes
- Minimum number of cluster nodes
- 次へ をクリックします。 以降のページをクリックして進み、[Update] ボタンを使用して変更を適用します。
スタックを更新すると、新しい Confluence バージョンを実行している追加ノードが 1 つ作成されます。アップグレード モードを有効にすると、そのノードはクラスタに参加して作業を開始できます。他のノードはまだアップグレードされません。
最初にアップグレードされたノードがクラスタに参加するとすぐに、クラスタのステータスは Mixed に移行します。つまり、すべてのノードで同じバージョンが実行されるまで、アップグレード モードを無効にすることはできません。
アップグレードした新しいノードをアクティブ状態で実行すると、そのノードのアプリ ログをチェックしてノードの Confluence にログインし、すべてが機能していることを確認する必要があります。この時点ではアップグレードをまだロール バックできるので、念のためにテストを行うことをお勧めします。
最初のノードをテストすると、別のノードのアップグレードを開始できます。これを実行するには、ノードをシャットダウンして終了します。AWS は、このノードをアップデート済みの Confluence バージョンを実行している新しいノードに置き換えます。
ステップ 4: 他のノードをアップグレードする
最も負荷のノードから開始する
実行中のタスクとアクティブ ユーザーの数が最も少ないノードのアップグレードを開始することをお勧めします。[ローリング アップグレード] ページの [Cluster overview (クラスタの概要)] セクションに両方が表示されます。
ステップ 2 では、クラスタ内の各ノードのインスタンス ID を記録しました。Confluence を正常にシャットダウンしたノードを終了します。この操作を行うには、次の手順を実行します。
- AWS コンソールで、[Services] > [EC2] に進みます。[Running Instances] をクリックします。
- Confluence を正常にシャットダウンしたノードと一致するインスタンスを確認します。
- [Actions] ドロップダウンから、[Instance State] > [Terminate] を選択します。
- クリック スルーして、インスタンスを終了します。
ノードを終了するたびに、AWS は自動的にそれを交換します。置換では、新しいバージョンの Confluence が実行されます。新しいノードのステータスが [Active] になったら、別のノードのアップグレードに進むことができます。
ステップ 5: 残りのノードを個別にアップグレードする
この時点で、クラスタには新しいバージョンの Confluence を実行する 2 つのノードが必要です。これで、他のノードをアップグレードできます。これを行うには、別のノードで前の手順を繰り返します。通常通り、毎回、実行するタスクの数が最も少ないノードをアップグレードすることをお勧めします。
デプロイでスタンドアロン Synchrony を使用している場合は、各 Synchrony ノードで使用されているバージョンも更新する必要がある場合があります。これを行うには、すべてのノードを新しいバージョンにアップグレードした後、各 Synchrony ノードを順に終了します。
ステップ 6. アップグレードを完了する
バグ修正バージョンへのアップグレードを完了する
アップグレードを完了するには、次の手順に従います。
- クラスタのステータスが [完了する準備ができました] に変わるのを待ちます。これは、すべてのノードがアクティブとなり、同じアップグレード バージョンを実行するまで発生しません。
- [アップグレードを完了] を選択します。
- アップグレードの完了が確認されるのを待ちます。クラスターのステータスが [安定] に変わります。
これでアップグレードは完了です。
機能バージョンへのアップグレードを完了する
アップグレードを完了するには、次の手順に従います。
- クラスターのステータスが [アップグレード タスクを実行する準備が完了しました] に変わるまで待ちます。すべてのノードがアクティブになって同じアップグレード バージョンを実行するようになるまで、このステータスにはなりません。
- [アップグレード タスクを実行してアップグレードを完了 (Run upgrade tasks and finalize upgrade)] ボタンを選択します。
- 1 つのノードでアップグレード タスクの実行が開始されます。プロセスを監視する場合は、このノードのログを確認します。
- アップグレードの完了が確認されるのを待ちます。クラスターのステータスが [安定] に変わります。
これでアップグレードは完了です。

スクリーンショット: クラスタ全体のアップグレード タスクを実行している 1 つのクラスタ ノード。
ステップ 7: クラスタをスケール ダウンする
ステップ 3 では、終了した各ノードの置き換えとして、ノードをクラスタに一時的に追加しました。これは、通常のユーザー トラフィックを処理するのに十分なノードがあることを確認するためでした。アップグレードを完了したら、そのノードを削除できます。
- AWS コンソールで、[Services] > [CloudFormation] に移動します。デプロイメントのスタックを選択してスタックの詳細を表示します。
- スタックの詳細画面で、[Update Stack] をクリックします。
- [Select Template] 画面で、[Use current template] を選択してから、[Next] を選択します。
- 次のパラメーターの値を 1 減らします。
- Maximum number of cluster nodes
- Minimum number of cluster nodes
- 次へ をクリックします。 以降のページをクリックして進み、[Update] ボタンを使用して変更を適用します。
AWS を置き換えることなく、クラスタから 1 つのノードを削除できるようになりました。この操作を行うには、次の手順を実行します。
- 実行中のタスクの数が最も少ないノードを選択します。
- ノードで Confluence をグレースフル シャットダウンします。
- ノードを終了します。
詳細な手順については、ステップ 4 を参照してください。
トラブルシューティング
ロード バランサーを使用してクラスタからノードを切断する
エラーによってノードを終了できない場合は、ロード バランサーを使用してクラスタからノードを切断してみてください。AWS Application Load Balancer では、各ノードがターゲットとして登録されているため、ノードを切断するには、登録を解除する必要があります。これを行う方法の詳細については、Application Load Balancers のターゲット グループと登録済みターゲットを参照してください。
アップグレード中またはアップグレード後にトラフィックが不均一に分散しています
この問題に対処するには、ノードをクラスタから一時的に切断することもできます。これにより、ロード バランサーは、他のすべての利用可能なノード間でアクティブなユーザーを再分配します。その後、クラスタにノードを再度追加できます。
ローリング アップグレード中のノード エラー
対処方法はいくつかあります。
ノードで Confluence をグレースフル シャットダウンします。これにより、ノードがクラスタから切断され、ノードが Offline ステータスにトランジションできるようになります。
Confluence を正常にシャットダウンできない場合は、ノードを完全にシャットダウンしてください。
すべてのアクティブ ノードがアップグレードされたら、ローリング アップグレードを完了できます。問題のあるノードの問題を後で調査し、エラーに対処したら、クラスタに再接続できます。
元のバージョンにロール バックする
アップグレード モードが無効になっている Mixed ステータス
アップグレード モードが無効のノードが Error 状態の場合、アップグレード モードを有効にすることはできません。問題を修正するか、クラスタからノードを削除して、アップグレード モードを有効にします。