Confluence Data Center の技術的概要
Confluence Data Center enables you to configure a cluster similar to the one pictured here with:
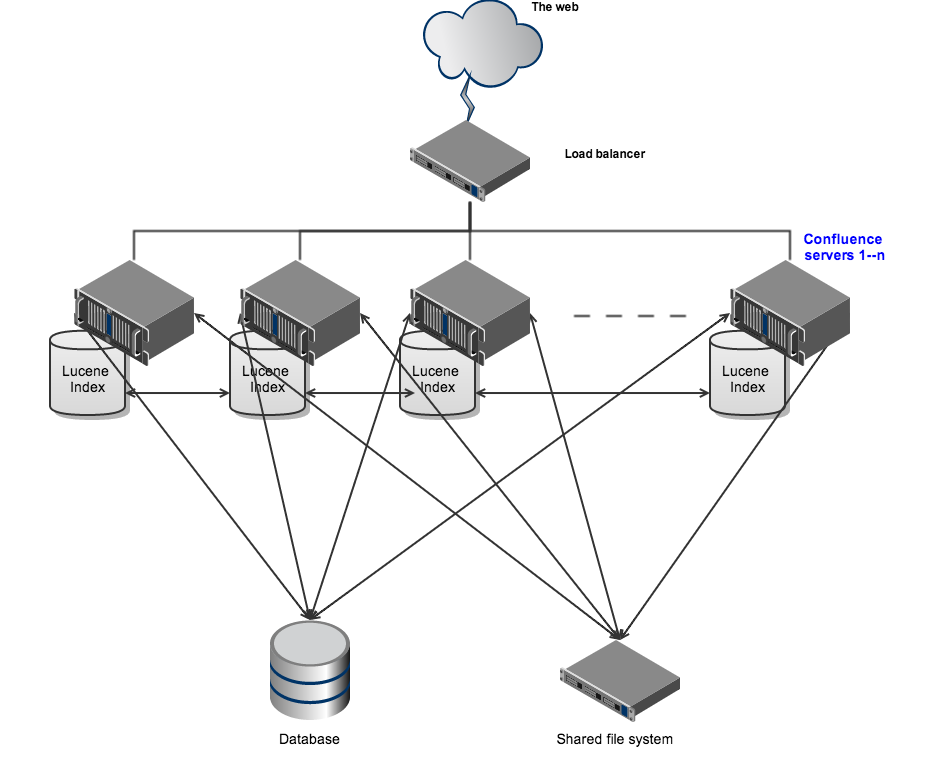
- Multiple server nodes that store:
- logs
- caches
- Lucene インデックス
- 設定ファイル
- plugins
- 以下を格納する共有ファイル システム
- attachments
- アバター / プロフィール写真
- アイコン
- エクスポート ファイル
- インポート ファイル
- plugins
- すべてのノードが読み取るおよび書き込むデータベース
- リクエストを各ノードに均等に送るロード バランサ
All nodes are active and process requests. A user will access the same node for all requests until their session times out, they log out or a node is removed from the cluster.
ライセンス
Data Center ライセンスは、ノードの数ではなく、クラスタのユーザー数に基づいています。ライセンス ページで利用可能なライセンス数を確認することができます。
このプロセスを自動化する(たとえば、割り当て限界に近づいた場合にアラートを送信する)場合は、REST API を使用することができます。
ホーム ディレクトリ
Confluence has a concept of a local home and shared home. Each node has a local home that contains logs, caches, Lucene indexes and configuration files. Everything else is stored in the shared home, which is accessible to each node in the cluster. Attachments, icons and avatars are stored in the shared home as are export and import files.
アドオンはアドオンのニーズに応じて、データをローカル ホームに格納するか共有ホームに格納するかを選択することができます。
現在添付ファイルをデータベースに保存している場合、そのまま保存し続けることができますが、新しいインストールでは利用できません。
キャッシング
Confluence uses a distributed cache that is managed using Hazelcast. Data is evenly partitioned across all the nodes in a cluster, instead of being replicated on each node. This allows for better horizontal scalability, and requires less storage and processing power than a fully replicated cache.
Because of this caching solution, to minimise latency, your nodes should be located in the same physical location.
インデックス
A full copy of the Confluence indexes are stored on each node individually. A journal service keeps each index in synch. If you need to reindex Confluence for any reason, this is done on one node, and then picked up by the other nodes automatically.
初めてクラスタをセットアップする場合、インデックスを含むローカル ホーム ディレクトリを1つ目のノードから新しい各ノードにコピーします。
When adding a new node to an existing cluster, you will copy the local home directory of an existing node to the new node. When you start the new node, Confluence will check if the index is current, and if not, request a recovery snapshot of the index from a running node (with a matching build number) and extract it into the index directory before continuing the start up process. If the snapshot can't be generated or is not received by the new node in time, existing index files will be removed, and Confluence will perform a full re-index.
If a node is disconnected from the cluster for a short amount of time (hours), it will be able to use the journal service to bring its copy of the index up-to-date when it rejoins the cluster. If a node is down for a significant amount of time (days) its Lucene index will have become stale, and it will request a recovery snapshot from an existing node as part of the startup process.
クラスタの安全なメカニズム
A scheduled task, ClusterSafetyJob, runs every 30 seconds in Confluence. In a cluster, this job is run on one node only. The scheduled task operates on a safety number – a randomly generated number that is stored both in the database and in the distributed cache used across the cluster. The ClusterSafetyJob compares the value in the database with the one in the cache, and if the value differs, Confluence will shut the node down - this is known as cluster split-brain. This safety mechanism is used to ensure your cluster nodes cannot get into an inconsistent state.
クラスタ スプリット ブレインが発生した場合、クラスタ化されているノード間の適切なネットワーク接続を確認する必要があります。ほとんどのマルチキャスト トラフィックはブロックされているか、正しくルーティングされません。
このメカニズムはスタンドアロンの Confluence にも存在しています。
稼働時間とデータの整合性のバランス
クラスタ セーフティなスケジュールされたジョブが実行される頻度と Hazelcast ハートビートの期間を変更する(クラスタからノードが削除されるまでのノードの通信不能期間を制御)ことで、クラスタの稼働時間とデータ整合性のバランスを微調整することができます。ほとんどの場合、デフォルト値が適切ですが、場合によっては、たとえば、稼働時間の増加のためにデータ整合性をトレード オフするように決定することができます。
クラスタ ロックとイベント ハンドリング
アクションが1つのノードでだけ実行される場合、たとえば、スケジュールされたジョブまたは日次のメール通知の送信の場合、Confluence はクラスタ ロックを使用して、アクションが1つのノードでだけ実行されることを保証します。
同様に、一部のアクションは1つのノードで実行される必要があり、その後他のノードに発行されます。イベント ハンドリングでは、現在のトランザクションがコミットされ完了するときにのみ、Confluence がクラスタ イベントを発行することを保証します。これは、イベントが受信されて処理されるときに、データベースに格納されているデータが他のクラスタで利用できることを保証するものです。イベント ブロードキャストはアドオンの有効化や無効化のような特定のイベントに対してのみ実行されます。
クラスタ ノード検出
クラスタ ノードを設定する場合、各クラスタノードの IP アドレスかマルチキャスト アドレスのいずれかを指定します。
マルチキャストを使用する場合:
Confluence はマルチキャスト ネットワーク アドレスにジョイン リクエストをブロードキャストします。Confluence はマルチキャスト アドレスの UDP ポートを開くことができる必要があり、それができない場合、他のクラスタノードを検出できません。ノードが検出されたら、それぞれキャッシュ更新のために接続できるユニキャスト(通常の) IP アドレスとポートで応答します。Confluence は他のノードとの通常の通信のために、UDP ポートを開くことができる必要があります。
マルチキャスト アドレスはクラスタ名から自動生成されるか、最初のノードのセットアップ時に自分で入力することができます。
インフラストラクチャとハードウェアの要件
ハードウェアの選択はあなた次第です。以下はハードウェアおよびインフラストラクチャ要件を計画するときに考える必要がある領域です。
サーバー
サーバーには最低 4GB の物理 RAM を搭載することをお勧めします。同時接続ユーザー数を増やすと、大量の RAM が消費されます。通常、JVM プロセスあたり 4GB 以上割り当てる必要はありませんが、必要に応じて設定を微調整することができます。
You should also not run any additional applications (other than core operating system services) on the same servers as Confluence. Running Confluence, JIRA and Bamboo on a dedicated Atlassian software server works well for small installations but is discouraged when running at scale.
Confluence Data Center は仮想マシンで正常に動作することができます。マルチキャストを使用する場合、Amazon Web Service (AWS)は現在マルチキャスト トラフィックをサポートしていないため、AWS で Confluence Data Center を実行することはできません。
クラスタノード
Data Center ライセンスでは、クラスタのノード数は制限されません。最大4ノードによるパフォーマンスと安定性をテストしています。
各ノードはまったく同じである必要はありませんが、一貫性のあるパフォーマンスのために、可能な限り同質になるようにします。すべてのクラスタ ノードは以下を満たす必要があります。
- 同じデータ センターにある
- run the same Confluence version
- 同じ OS、Java、およびアプリケーション サーバー バージョン
- 同じメモリ設定(JVM と物理メモリの両方)(推奨)
- 同じタイムゾーンで設定されている(および現在の同期された時間を維持する)。これを保証するには ntpd または同様なサービスを使用することをお勧めします。
![]() クラスタでさまざまな問題が発生する可能性があるため、クラスタ ノードのクロックが逸脱していないことを確認する必要があります。
クラスタでさまざまな問題が発生する可能性があるため、クラスタ ノードのクロックが逸脱していないことを確認する必要があります。
データベース
The most important requirement for the cluster database is that it have sufficient connections available to support the number of nodes. For example, if each Confluence instance has a connection pool of 20 connections and you expect to run a cluster with four nodes, your database server must allow at least 80 connections to the Confluence database. In practice, you may require more than the minimum for debugging or administrative purposes.
目的のデータベースが現在「サポートされているプラットフォーム」に記載されていることも確認する必要があります。平均的なクラスタ ソリューションの負荷はスタンドアロン インストールよりも高くなるため、サポートされているデータベースを使用することが重要です。
共有ホーム ディレクトリおよびストレージ要件
All cluster nodes must have access to a shared directory in the same path. NFS and SMB/CIFS shares are supported as the locations of the shared directory. As this directory will contain large amount of data (including attachments and backups) it should be generously sized, and you should have a plan for how to increase the available disk space when required.
ロード バランサ
We suggest using the load balancer you are most familiar with. The load balancer needs to support ‘session affinity’.
ネットワークアダプタ
Use separate network adapters for communication between servers. The Confluence cluster nodes should have a separate physical network (i.e. separate NICs) for inter-server communication. This is the best way to get the cluster to run fast and reliably. Performance problems are likely to occur if you connect cluster nodes via a network that has lots of other data streaming through it.
高可用性の追加要件
Confluence Data Center removes the application server as a single point of failure. You can further minimise single points of failure by ensuring your load balancer, database and shared file system are also highly available.
プラグインとアドオン
Confluence Data Center へのアドオンのインストールのプロセスは、Confluence のスタンドアロン インスタンスと同じです。アドオンのインストールまたは更新の際に、クラスタを停止させたり、ノードをダウンさせたりする必要はありません。
The Atlassian Marketplace indicates add-ons that are compatible with Confluence Data Center.
Data Center のアドオン ライセンスは、単一サーバー レートで販売されていますが、Confluence Data Center ライセンス層と一致するか超えている必要があります。たとえば、Confluence Data Center を使用しているユーザーが3,000ユーザーの場合、2,001-10,000ユーザー層でアドオンを購入します。
Confluence の独自のプラグイン開発した場合、「アドオンがクラスタで正しく動作するかを確認するにはどうしたらよいですか?」の開発者ドキュメントを参照し、プラグインがクラスタ互換であることを確認する方法を確認する必要があります。
準備はよろしいですか?
Data Center を開始する時やアトラシアン担当者と相談する場合は、お問い合わせください。