データ パイプライン
要件
REST API を使用してデータのエクスポートをトリガーするには、次が必要です。
A valid Bitbucket Data Center license
Bitbucket system admin global permissions
Considerations
開始する前に、多数のセキュリティとパフォーマンスへの影響を考慮する必要があります。
セキュリティ
セキュリティと機密性に基づいてデータを除外する必要がある場合は、データをエクスポートした後に行う必要があります。
エクスポートされたファイルは共有ホーム ディレクトリに保存されるため、このファイルが適切に保護されていることも確認できます。
エクスポート パフォーマンス
エクスポートのスケジュールを設定するときは、次のことをお勧めします。
fromDateパラメーターを使用してエクスポートするデータの量を制限します。日付が古すぎるとより多くのデータがエクスポートされるため、データのエクスポートに要する時間が長くなります。- エクスポート中にパフォーマンスの低下が見られる場合は、アクティビティが少ない時間帯またはアクティビティのないノードでエクスポートをスケジュールします。
データ パイプラインにアクセスする
To access the data pipeline select ![]() > Data pipeline.
> Data pipeline.
定期エクスポートをスケジュール
エクスポート スケジュールを設定するには、次の手順に従います。
- データ パイプラインの画面で [スケジュールの設定] を選択します。
- [定期エクスポートをスケジュール] チェックボックスをオンにします。
- データを含める日付を選択します。この日付より前のデータは含まれません。通常、12 か月以下に設定されます。
- エクスポートを繰り返す頻度を選択します。
- エクスポートを開始する時刻を選択します。勤務時間外にエクスポートが実行されるようにスケジュールすることをお勧めします。
- 使用するスキーマ バージョンを選択します (使用可能なスキーマが複数ある場合)。
- スケジュールを保存します。
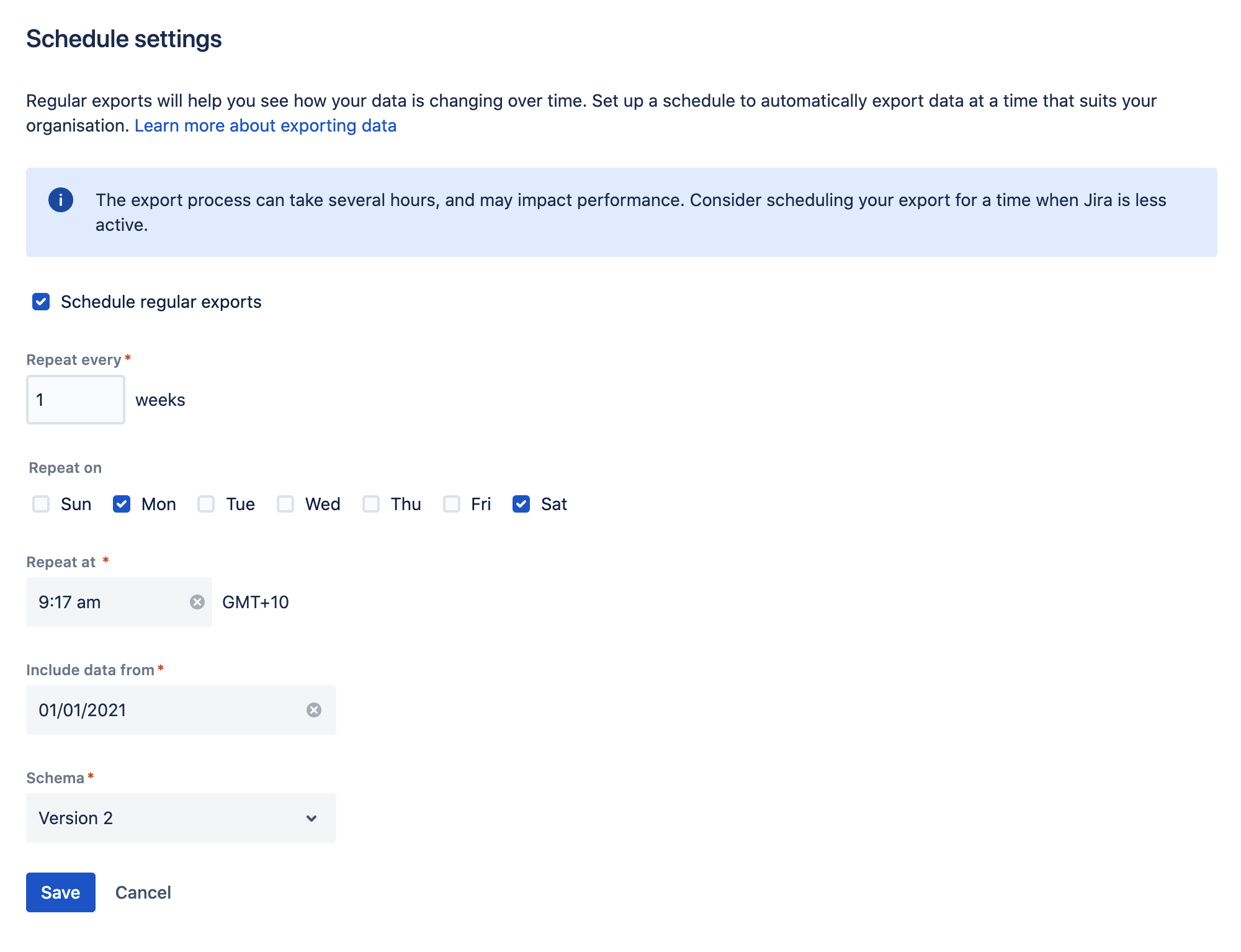
タイムゾーンと反復するエクスポート
エクスポートをスケジュールするときは、サーバーのタイムゾーンを使用します (アプリケーションでサーバーの時刻を上書きした場合はシステムのタイムゾーンを使用します)。タイムゾーンを変更しても、エクスポート スケジュールは更新されません。タイムゾーンを変更する必要がある場合は、スケジュールを編集してエクスポート時刻を再入力する必要があります。
エクスポートは必要な頻度で実行するようにスケジュールできます。複数の曜日にエクスポートすることを選択した場合、最初のエクスポートはスケジュールを保存した後の直近の曜日に行われます。上のスクリーンショットの例では、木曜日にスケジュールを設定した場合は最初のエクスポートは土曜日に、2 回目のエクスポートは月曜日に行われます。週の始まりを待ちません。
エクスポート スキーマ
エクスポート スキーマでは、エクスポートの構造を定義します。エクスポートが以前のエクスポートと同じ構造になることがわかるように、スキーマのバージョンを管理します。これによって、このデータに基づいてダッシュボードまたはレポートを作成した場合の問題を回避できます。
フィールドの削除などの重大な変更やデータの構造化方法の変更が発生した場合にのみ、新しいスキーマ バージョンを導入します。新しいフィールドは、最新のスキーマ バージョンにのみ追加されます。
古いスキーマ バージョンは「非推奨」としてマークされて、将来のバージョンで削除される可能性があります。これらのバージョンを使用して引き続きエクスポートできますが、新しいフィールドではこれらのバージョンは更新されませんのでご注意ください。
エクスポートのステータスを確認する
[エクスポートの詳細] テーブルには、最新のエクスポートと現在のステータスが表示されます。

[![]() ] > [詳細を表示] の順に選択すると、エクスポートの詳細が JSON 形式で表示されます。詳細には、エクスポート パラメーター、ステータス、すべての返されたエラー (エクスポートが失敗した場合) が含まれます。
] > [詳細を表示] の順に選択すると、エクスポートの詳細が JSON 形式で表示されます。詳細には、エクスポート パラメーター、ステータス、すべての返されたエラー (エクスポートが失敗した場合) が含まれます。
失敗したエクスポートまたはキャンセルされたエクスポートの解決については、「データ パイプラインのトラブルシューティング」をご参照ください。
エクスポートをキャンセルする
- [データ パイプライン] 画面に移動します。
- エクスポートの横にある
 、エクスポートの [キャンセル] の順に選択します。
、エクスポートの [キャンセル] の順に選択します。 - エクスポートのキャンセルを確定します。
プロセスが終了するまでに数分かかることがあります。すでに書き込まれたファイルは、エクスポート ディレクトリに残ります。これらのファイルが不要なら削除できます。
自動データ エクスポート キャンセル
DELETE リクエストを作成します)。これによって、プロセスのロックが解除されて別のデータ エクスポートを実行できるようになります。プロジェクトをエクスポートから除外する
プロジェクトをオプトアウト リストに追加するには、POST リクエストを <base-url>/rest/datapipeline/1.0/config/optout に行って、次のようにプロジェクト キーを渡します。
{
"type": "PROJECT",
"keys": ["HR","TEST"]
}これらのプロジェクトは、今後すべてのエクスポートから除外されます。オプトアウトの機能はデータ パイプラインのバージョン 2.3.0 以降で導入されたことにご注意ください。
プロジェクトをオプトアウト リストから削除する方法を含む完全な詳細については「データ パイプライン REST API のリファレンス」をご参照ください。
データ エクスポートを設定する
You can configure the format of the export data through the following configuration properties.
| 既定値 | 説明 |
|---|---|
plugin.data.pipeline.embedded.line.break.preserve | |
false | 埋め込まれた改行を出力ファイルに保持するかどうかを指定します。Hadoop などのツールでは、改行が問題になる場合があります。 このプロパティはデフォルトで |
plugin.data.pipeline.embedded.line.break.escape.char | |
\\n | 埋め込まれた改行の文字をエスケープします。デフォルトでは、 |
plugin.data.pipeline.minimum.usable.disk.space.after.export | |
| 5 GB | ディスク領域が不足するのを防ぐため、データ パイプラインはエクスポートの前と最中に 5GB 以上の空きディスク領域があるかどうかを確認します。 制限を増減するには、このプロパティを GB 単位で設定します。このチェックを無効にするには、このプロパティを |
| 既定値 | 説明 |
|---|---|
plugin.data.pipeline.bitbucket.export.personal.forked.repository.commits | |
false | Specifies whether commits from forked repositories in personal projects should be exported. Set this property to |
plugin.data.pipeline.bitbucket.export.build.statuses | |
false | Specifies whether build statuses should be included in the export. Exporting build statuses can take a significant amount of time if you have a lot of builds. Set this property to |
plugin.data.pipeline.bitbucket.commit.queue.polling.timeout.seconds | |
20 | Time, in seconds, it takes to receive the first commit from git process. You should only need to change this if you see a |
plugin.data.pipeline.bitbucket.commit.git.execution.timeout.seconds | |
3600 | Sets the idle and execution timeout for the git ref-list command. You should only need to change this if you see "an error occurred while executing an external process: process timed out" error. |
plugin.data.pipeline.bitbucket.export.pull.request.activities | |
true | Specifies whether historical data about pull request activity data should be included in the export. Exporting activity data will significantly increase your export duration. Set this property to |
データ パイプライン REST API を使用する
データ パイプラインをエクスポートし始めるには、<base-url>/rest/datapipeline/latest/export に対する POST リクエストを実行します。
認証に cURL と個人アクセス トークンを使用するリクエストの例を次に示します。
curl -H "Authorization:Bearer ABCD1234" -H "X-Atlassian-Token: no-check"
-X POST https://myexamplesite.com/rest/datapipeline/latest/
export?fromDate=2020-10-22T01:30:11Zまた、API を使用して、ステータスを確認、エクスポート場所を変更、エクスポートをスケジュール設定またはキャンセルできます。
詳細については「データ パイプライン REST API のリファレンス」をご参照ください。
出力ファイル
データ エクスポートを実行するたびに、数値ジョブ ID をタスクに割り当てます (最初のデータ エクスポートに対して 1 から開始)。このジョブ ID は、エクスポートされたデータを含むファイルのファイル名と場所で使用されます。
エクスポートされたファイルの場所
エクスポートされたデータは個別の CSV ファイルとして保存されます。ファイルは次のディレクトリに保存されます。
<shared-home>/data-pipeline/export/<job-id>if you run Bitbucket in a cluster<local-home>/shared/data-pipeline/export/<job-id>you are using non-clustered Bitbucket.
<job-id> ディレクトリ内には次のファイルが表示されます。
build_statuses_<job_id>_<schema_version>_<timestamp>.csvcommits_<job_id>_<schema_version>_<timestamp>.csvpull_request_activities_<job_id>_<schema_version>_<timestamp>.csvpull_requests_<job_id>_<schema_version>_<timestamp>.csvrepositories_<job_id>_<schema_version>_<timestamp>.csvusers_<job_id>_<schema_version>_<timestamp>.csv
これらのファイルでデータをロードして変換するには、そのスキーマを理解する必要があります。「データ パイプライン エクスポート スキーマ」をご参照ください。
カスタム エクスポート パスを設定する
ルート エクスポート パスを変更するには、<base-url>/rest/datapipeline/1.0/config/export-path に PUT リクエストを実行します。
リクエストの本文で、優先するディレクトリに対する絶対パスを渡します。
既定のパスに戻す方法を含む詳細については「データ パイプライン REST API のリファレンス」をご参照ください。
Spark と Hadoop のインポート設定の例
既存の Spark インスタンスまたは Hadoop インスタンスがある場合、次の参照を使用し、さらに変換するためにデータをインポートする方法を設定します。