Bitbucket Mesh whitepaper
概要
Bitbucket Mesh is a distributed, replicated, and horizontally scalable Git repository storage subsystem designed for high performance, scalability, and resilience. It's intended as an alternative to the existing Network Filesystem (NFS) based Git repository storage subsystem that Bitbucket Data Center has shipped with since its inception.
On this page
Benefits of Bitbucket Mesh
Bitbucket Mesh has a number of benefits compared to the NFS-based Git repository storage subsystem. These benefits particularly improve the experience of larger Bitbucket instances that service large numbers of users, host large or very active repositories, or require a high degree of redundancy and resilience.
パフォーマンス
When moving from a single node to a clustered deployment, Bitbucket instances often see a decrease in performance. Moving from a single node to a multinode (clustered) deployment does provide increased scalability, due to the additional CPU and memory available to service user requests. So, such a system can sustain more concurrent users successfully.
However, individual requests can become slower. This occurs as a side-effect of moving the repository storage from a local filesystem to a network-attached filesystem, specifically NFS. In effect, this moves the storage further away from the processing, increasing filesystem input and output (I/O) operation latency.
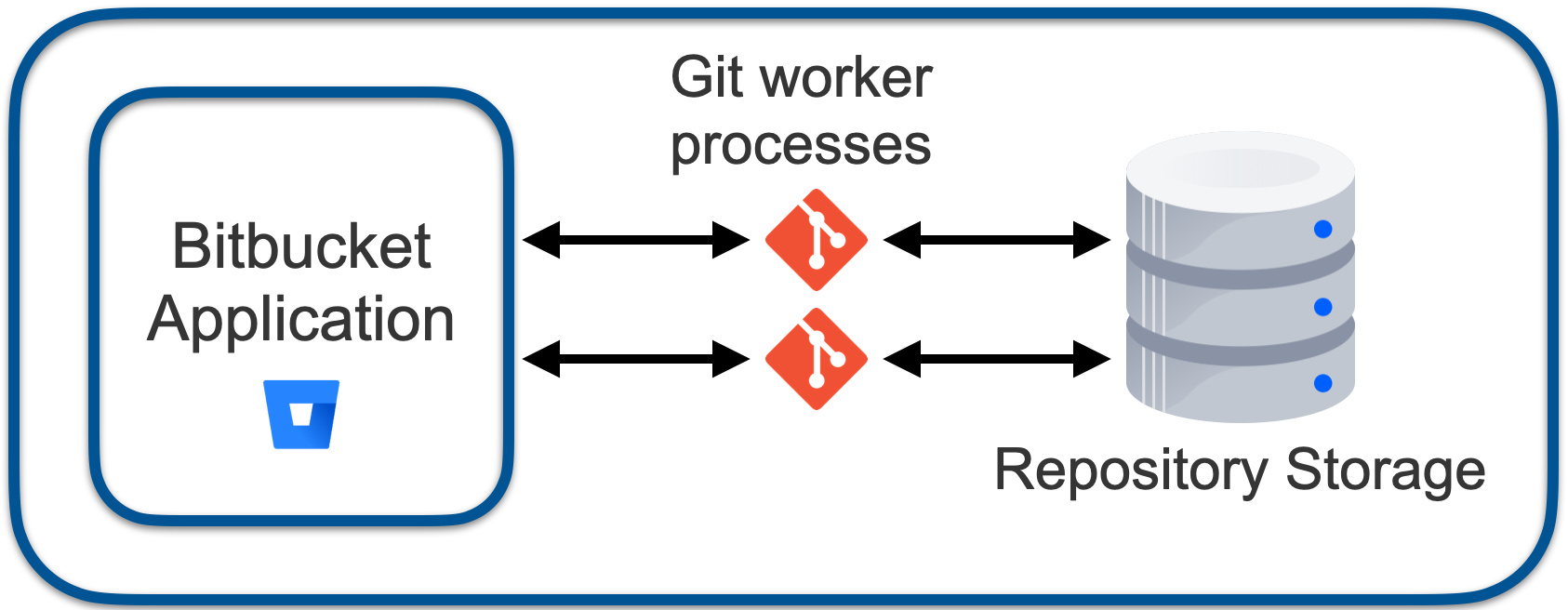
In a single-node Bitbucket deployment, the repository storage is hosted on a local filesystem (see Figure 1). In such a system, I/O latency for obtaining the size of a file, reading a block of data, and other operations is fast, often taking a few microseconds where data is cached, or on the order of 100 microseconds for a disk read.
Figure 1 – Bitbucket with local repository store
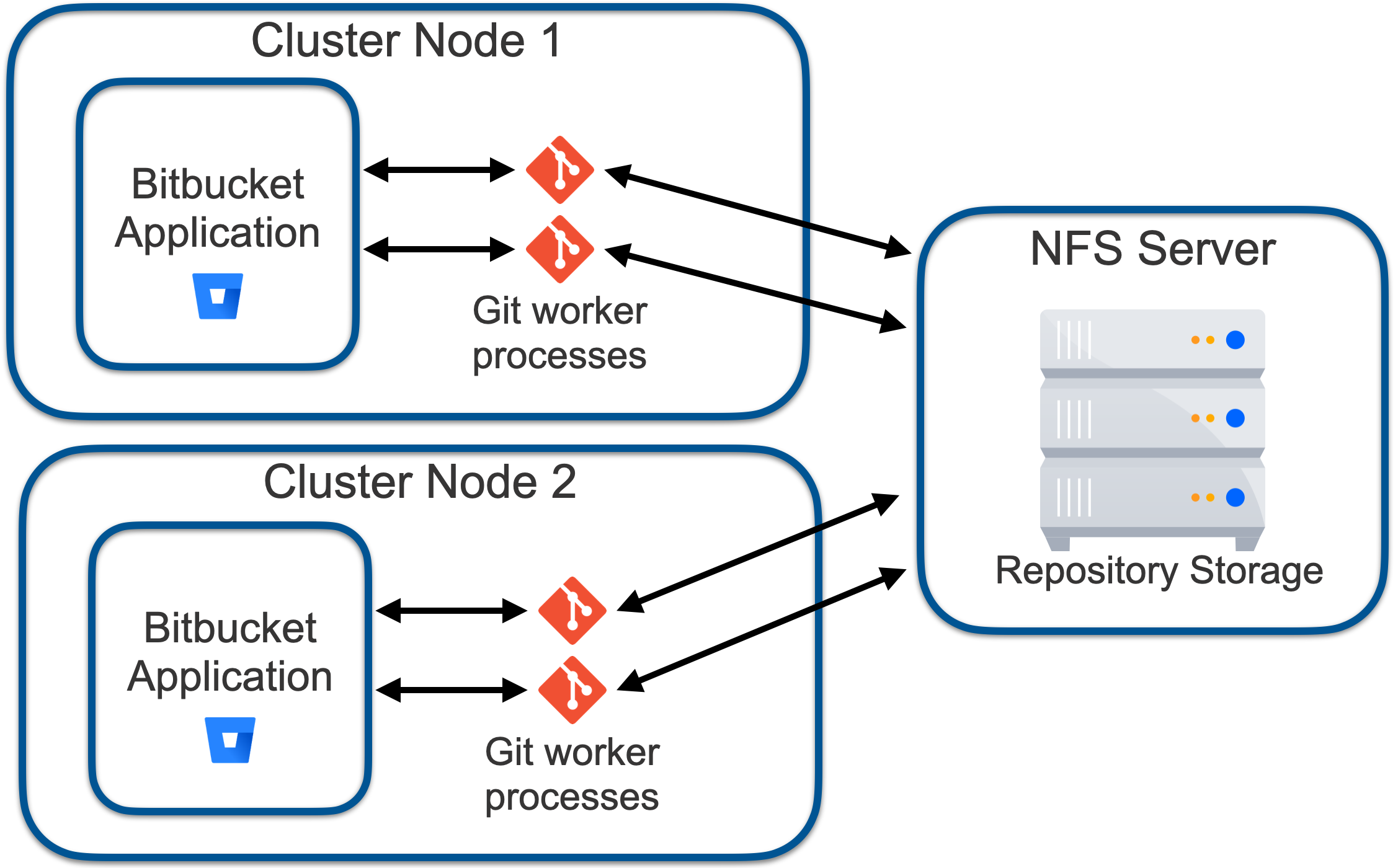
In a multinode Bitbucket cluster deployment, the repository storage is hosted on a remote NFS (see Figure 2). In such a system, I/O latency for similar operations is 10 to 1000 times slower due to the necessity of requests transiting the network, and due to the shared nature of the filesystem, many things can't be cached on the NFS client (that is the cluster node) but can only be cached on the NFS server, thus still incurring network latency overheads.
Figure 2 – Bitbucket cluster with NFS-based repository store
This increase in I/O operation latency is particularly harmful to Git as it relies on low-latency filesystems for high performance. To illustrate this, we can take a user request to list all branches or tags in a repository. This would result in Bitbucket forking a git-for-each-ref process to obtain the list from the repository on disk. For a repository with many branches, particularly if git-pack-refs hasn’t run recently, such a request may require, for example, 5000 individual I/O operations. On a local filesystem where operation latency is 10 ms, this request would take 50 ms to complete, appearing almost instantaneous to a user.
The same request on an NFS-based repository store, where operation latency is often in the range of 0.5-
2 ms, could instead take between 2.5 and 10 s, which is an unacceptably long time for an interactive user interface.
Mesh solves the above problem by moving the processing to the storage, eliminating the additional I/O operation latency that exists in the NFS-based system (see Figure 3). If we take the above example and apply it to a Mesh-based system, the cluster node makes a single remote procedure call (RPC) to a Mesh node. Then, the forked Git process makes its 5000 I/O requests to the local storage, taking 50 ms to complete (that is 5000 x 10 ms). Then, factoring in the RPC round trip overhead of, for example, 1 ms, the entire request would take a total of 51 ms to complete – again appearing almost instantaneous to a user.
Figure 3 – Bitbucket with Mesh-based repository store

Resilience
When deployed as a cluster, Bitbucket Data Center is designed for high availability. Figure 4 shows a typical Bitbucket cluster in a high-availability deployment. This type of deployment can sustain the loss of a cluster node either due to scheduled maintenance or a failure.
Figure 4 – Bitbucket cluster with NFS-based repository store in a typical high-availability deployment

However, it can be challenging to build a truly highly available NFS server. The standard supported NFS deployment is a Linux-based NFS server. While this system may be built with redundant disks, power supplies, and network interfaces, it's still a single node and subject to failures. Besides, it can’t be restarted for maintenance (such as operating system patching) without a Bitbucket system outage.
Various commercial NFS “appliances” take the concept of redundancy further, including redundant system boards. These boards mean that updates can be carried out without interrupting operations, and often most components can be replaced without an outage. However, these are expensive and still deployed in a single physical location, so they aren’t truly redundant.
Unfortunately, fully redundant network filesystems are highly unsuited to Bitbucket’s needs, or more specifically Git’s needs, as the synchronization and coordination overheads result in very high I/O latency for filesystem operations. As a consequence, Bitbucket performance becomes wholly unacceptable. This problem also applies to cloud-based NFS services such as Amazon’s Elastic Filesystem and other cloud offerings, making highly available cloud deployments unobtainable.
Mesh solves this problem as it's a sharded, replication-based repository store consisting of multiple truly redundant nodes. When repositories are migrated to Mesh, they're replicated to multiple Mesh nodes. That ensures that the loss of any single node has no impact on the availability of the repositories it hosted because each still has replicas available on other nodes. When Mesh nodes are brought back online, they automatically repair their replicas and are returned to service.
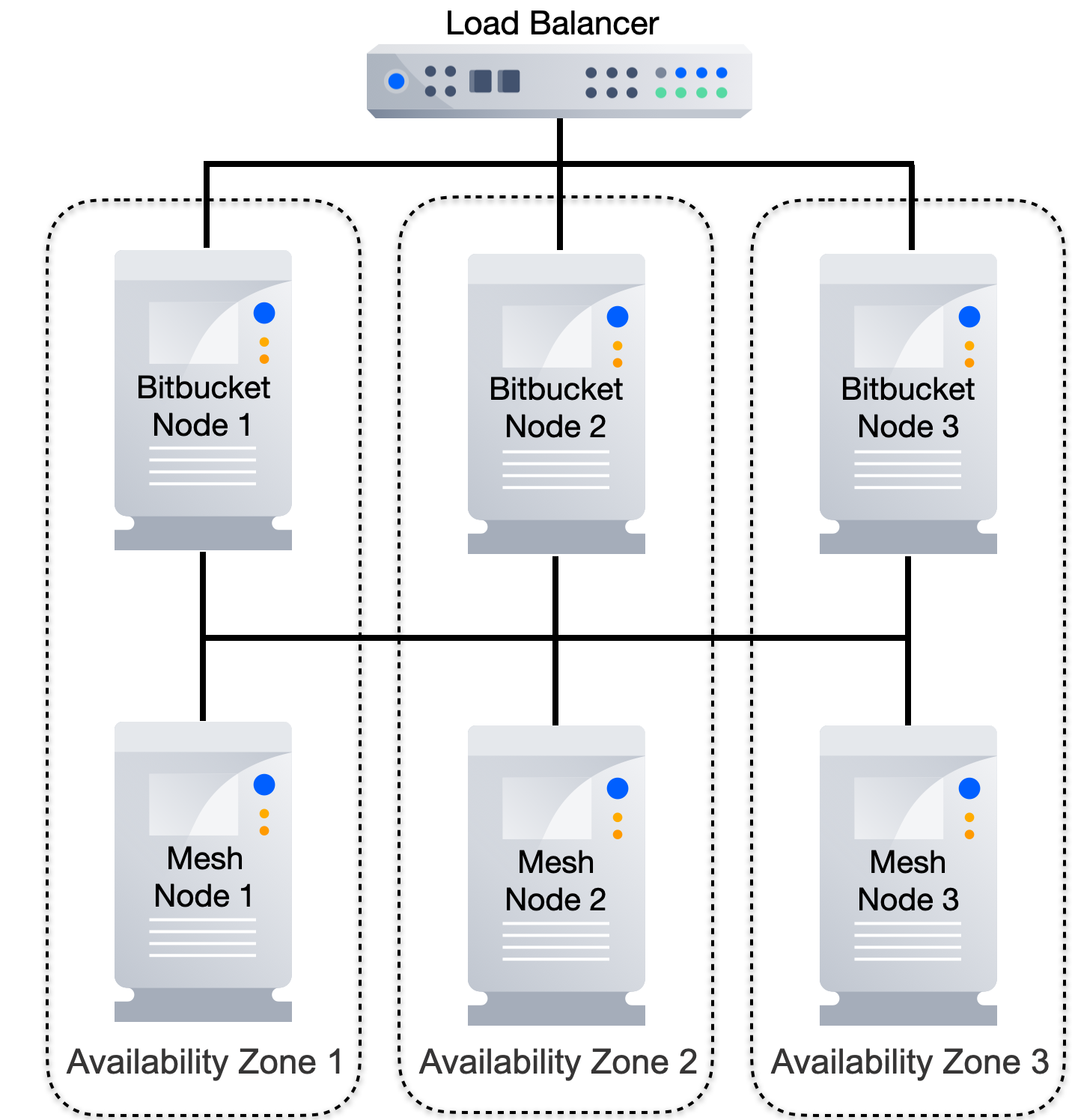
Furthermore, it's possible to host Mesh nodes in different physical locations. This permits different Mesh nodes to reside in different data centers, with separate power supplies, network infrastructure, cooling systems, and other factors that can greatly increase resilience. Using cloud terminology enables a multiavailability zone repository store.
Figure 5 – Multiavailability zone deployment of Bitbucket with Mesh
スケーラビリティ
The NFS-based Bitbucket cluster permits horizontal scalability but with some limitations as to how the NFS-based repository store can be scaled. Specifically:
Adding new cluster nodes increases CPU and memory available to Git worker processes as well as increases network bandwidth.
Adding additional NFS data stores increases repository storage I/O bandwidth.
However, adding additional NFS data stores only provides the ability to scale the I/O bandwidth available to existing repositories. Only new repositories are created on the additional NFS data stores while existing repositories don't benefit from the additional data stores.
Additional data stores provide scaling where the load is mostly uniformly distributed over all repositories. However, this is also not a helpful scaling mechanism when development teams are using a monorepo – a single large repository that hosts multiple projects, potentially used by all developers or a large fraction of the development staff.
Bitbucket Mesh provides true horizontal scaling of both processing and storage capacity. Repositories are replicated to multiple Mesh nodes, and each replica is capable of actively serving both read and write traffic. Each replica adds capacity, and this capacity can be incrementally added or removed, permitting flexible scaling both up and down.
Disadvantages of Bitbucket Mesh
While discussing the many benefits of Bitbucket Mesh, it's also worth discussing the disadvantages, with the primary disadvantage being the increased complexity.
Complexity
A typical Bitbucket Data Center instance is relatively simple. It consists of the Bitbucket Java application plus a database, filesystem, and an OpenSearch instance. This is made slightly more complex when an instance is deployed in a cluster since there are multiple instances of the Bitbucket Java application running. However, at the core, it's still simple, with the core state existing on the shared filesystem and the database.
Mesh complicates this, with a second Java application type needing deployment (the Mesh application) and the additional core state existing on multiple Mesh nodes. This makes the following activities more complex:
デプロイメント
Bitbucket version upgrades
監視
バックアップとリストア
トラブルシューティング
For a Bitbucket instance running well, one that wouldn’t benefit from any of the abovementioned performance, resilience, or scalability benefits, migrating to a Mesh-based deployment may not be desirable. Instead, the NFS-based Git repository storage subsystem may better suit such instances.
Additional storage capacity requirement
With the traditional NFS-based repository store, there's exactly one copy of each repository on disk. Although this is a slight oversimplification as filesystems may be configured as RAID1, RAID5, or similar, which incurs some additional storage space.
Bitbucket Mesh provides increased scalability, performance, and resilience, but at the cost of additional disk storage requirements. Bitbucket Mesh uses replication of repositories to achieve these goals, and with a minimum replication factor of three, the minimum disk storage requirement is also increased by a factor of three.
This doesn’t necessarily translate to a linear (for example, three-fold) increase in storage pricing. Most Bitbucket Data Center deployments that are built for high availability rely on expensive “NFS appliances” for highly scalable and reliable storage. Bitbucket Mesh permits building out horizontally using usually the most cost-effective internal storage, direct attached storage (DAS), or storage area network (SAN) based storage.
Deployment overview
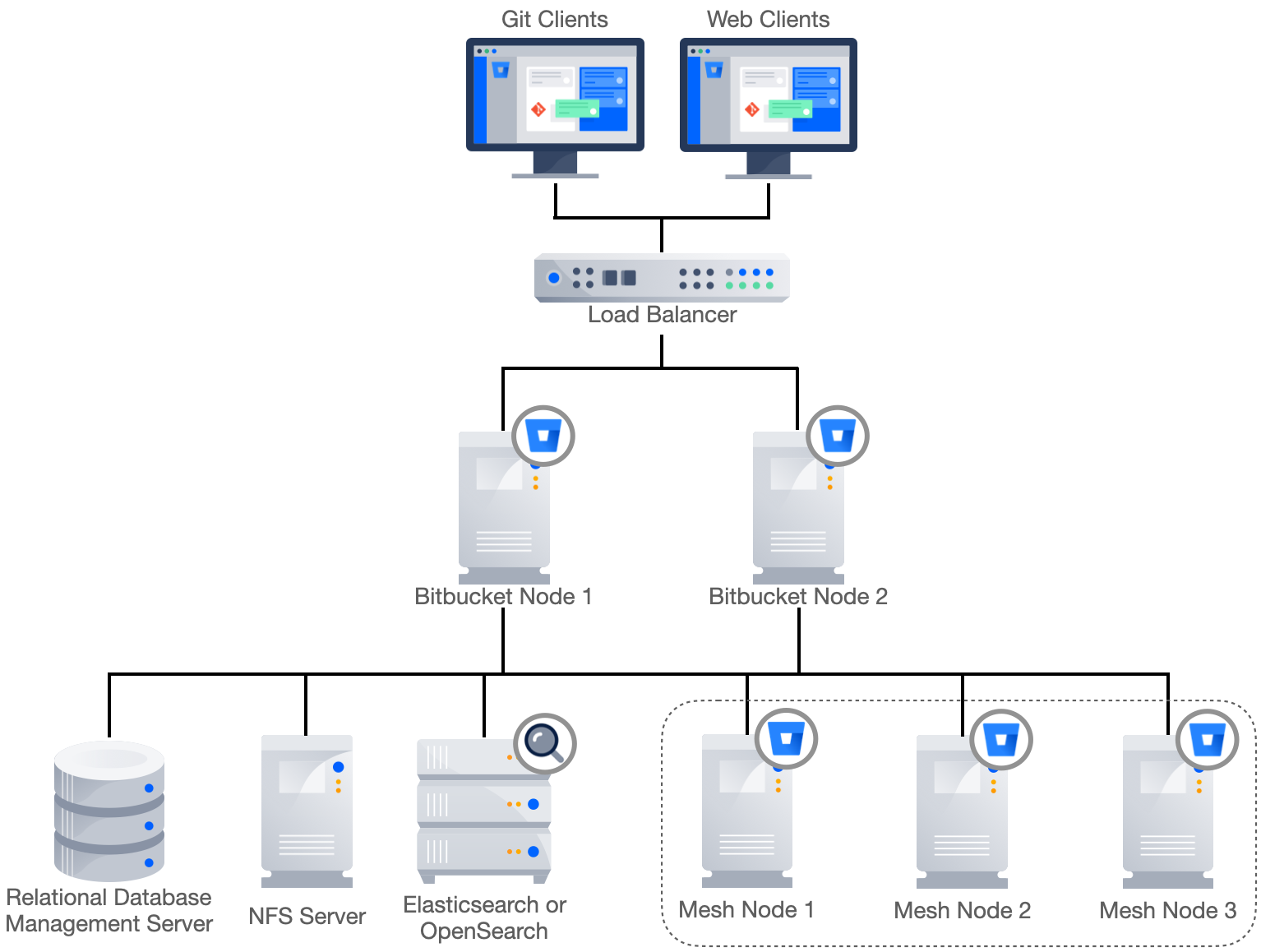
A traditional (pre-Mesh) clustered Bitbucket Data Center deployment is comprised of the following components:
One or more Bitbucket Application nodes
Load balancer
Relational database management system (RDBMS)
OpenSearch instance
Network filesystem (NFS)
Enhancing this deployment to include Mesh requires the addition of a minimum of three Mesh nodes. A minimal clustered Bitbucket Data Center deployment with Mesh can be seen in Figure 6.
Figure 6 – Minimal clustered Bitbucket Data Center deployment with Mesh
A minimum of three Mesh nodes must be deployed because this is the minimum supported replication factor required for the system to sustain a failure of one node and still form a write quorum. Any number of Mesh nodes three or greater can still be deployed, as this may be needed to scale processing, storage, or networking capacity.
It should be noted at this point that the application running on the Mesh nodes isn’t the normal Bitbucket Java application, which we’ll call the core Bitbucket application from here onwards. Rather, a new application is installed on the Mesh nodes – we’ll call it the Mesh application. This new application is a gRPC server that provides remote procedure calls (RPCs) to read, write, and manage the Git repositories managed by the Mesh application.
It may seem surprising that the NFS server still exists in the above deployment. On the surface, it might appear that once the repository data is migrated to the Mesh nodes, the NFS server could potentially be removed. The NFS server, or more specifically a shared file system, is still necessary and continues to host non-Git data, including project and user avatars, attachments that may be associated with pull requests and inlined in comments, plugins, Git Large File Storage (LFS) objects, and many other things. However, once all repositories have been migrated to Mesh, many of the strict performance requirements Bitbucket sets for the shared filesystem are no longer present. This means:
The requirement to use NFSv3 can be relaxed to permit NFSv4 usage. Historically, NFSv4 wasn’t supported as it requires more round trips for the same operation when compared to NFSv3, which resulted in inferior performance.
Cloud-managed NFS filesystems such as AWS Elastic Filesystem (EFS) can be utilized.
Potentially, in the future, non-NFS shared filesystem may be available for utilization. This is subject to further testing to ensure the basic requirements are still met, including POSIX compatibility, delete on last close, locking, etc.
主なコンセプト
The following describes a number of key Mesh concepts. Understanding them will improve the understanding of how the system works and why it works that way.
Replication
The key to Bitbucket Mesh’s ability to scale and provide fault tolerance is the concept of replication. In the NFS-based repository store, there's only one copy of the repository on disk. In Mesh, there exist multiple copies of any given repository, with the specific number controlled by the “replication factor” tunable. At the time this document is being written, this setting is global, affecting all repositories. In a future version of Bitbucket, it's expected that the setting will become tunable on a per-repository basis. The default replication factor is three, and the minimum is also three for the reasons described below.
Replication implies an increase in the storage required for repositories when compared to an NFS-based repository store. If we take a simple example with 500 GB of repository data on NFS, deploying three Mesh nodes, and given the default replication factor of three, each Mesh node will require 500 GB of storage for these repositories. This is a total of 1500 GB of storage.
For a more complex example, it's more challenging to determine the exact amount of disk space required. Take the same 500 GB of repository data on NFS, with a replication factor of three, and five Mesh nodes. In this case, the total storage requirement is also 1500 GB but distributed over five Mesh nodes. Assuming a large number of repositories of the same size, 1500 GB could be divided by five, indicating a storage requirement of 300 GB per Mesh node.
In reality, not all repositories are of equal size. In the above example, if the size of one repository was 400 GB, three of the five Mesh nodes would clearly require at least 400 GB of storage.
スケーラビリティ
Mesh provides the ability to scale vertically and horizontally. Horizontal scaling specifically exceeds the scaling capabilities of the NFS-based repository store. However, there are some important subtleties. For the purposes of scaling, we’ll focus on three core factors:
Disk I/O bandwidth and IOPS capacity
CPU available to Git worker processes
Memory available to Git worker processes
In the NFS-based repository store, the ability to scale disk I/O faces an inevitable upper bound since for a given repository, only vertical scaling is possible. Additional NFS filesystems can be attached, providing some horizontal scaling, but a given repository can only ever exist on one NFS filesystem.
However, CPU and memory can be added to the system by adding application nodes. Since each application node has a shared view of mounted NFS filesystems, it can service a request for any repository hosted by the system. This is true regardless of whether the instance has two or 20 application nodes.
Mesh has a slightly different characteristic when scaling horizontally since a given Mesh node can only service requests for repositories for which it hosts a replica. This can become a bottleneck where some “hot” repositories exist. That is repositories that are large, busy, and have a disproportionally large fraction of usage relative to other repositories. For example, given a replication factor of three and a deployment of 20 mesh nodes, only three mesh nodes are able to service requests for a given “hot” repository, with the other 17 nodes remaining idle or only servicing requests for other repositories.
This problem could be resolved by increasing the replication factor to 20, resulting in all 20 mesh nodes hosting a replica of each repository, and thus being able to service requests for any repository. However, this comes at the cost of increased storage space required: in this case, a 20-time increase over the storage requirement of the NFS-based deployment.
In reality, for most systems, there will be a happy middle ground that balances the need for scaling with the desire to minimize the cost of storage. When migrating an existing system, this middle ground can be obtained, at least approximately, by analyzing the distribution of requests using the access logs.
Fault tolerance
Replication also provides increased fault tolerance over the NFS-based repository store. The standard supported NFS deployment is a Linux-based NFS server. While this system may be built with redundant disks, power supplies, and network interfaces, it's still a single node and is subject to failures. Besides, it can’t be restarted for maintenance (such as operating system patching) without a Bitbucket system outage.
Mesh replicas are located on three or more completely separate Mesh nodes which can leverage not just independent hardware but also needn’t share the same power source, cooling, network, or even physical location.
The minimum configurable replication factor is three. This permits the loss of one replica while still supporting writes. The writes succeed on a quorum of replicas, where “n” is the replication factor a quorum of (n/2 + 1) replicas must be available for a write to succeed.
The result of the division should be rounded down. For example, with a replication factor of three, a minimum of two replicas must be present for a write to succeed. For a replica to participate in a write operation, it must be consistent. A replica may be inconsistent because the node missed one or more writes while it was offline and hasn’t been repaired yet. So, a node hosting a replica may be online but may still be inconsistent and thus, ineligible for participating in a write transaction. As a result, it won’t count towards the quorum.
Read operations aren't subject to the same quorum logic and only require one available and consistent replica.
Control plane
To build a model of how Bitbucket Mesh functions, it's useful to understand what the Mesh application is responsible for managing and what the core Bitbucket application is responsible for.
The subsystem in the core Bitbucket application that is responsible for managing the Mesh nodes is known as the control plane. Among other things, it's responsible for:
Distribution of configuration information to Mesh nodes.
Allocation of repository replicas to Mesh nodes, specifically partition replicas described below.
Routing of requests to Mesh nodes based on the knowledge of which Mesh nodes contain a consistent and up-to-date replica of a given repository.
Management and distribution of replica state, either consistent or inconsistent.
Generally, it's useful to think of Mesh nodes as relatively simple repository storage agents and of the control plane in the core Bitbucket application as the brains.
Partitions
Managing replicas on a per-repository basis is potentially inefficient on systems with large numbers of repositories impacting scalability. A higher-level entity exists to solve this – a partition. The partition is an aggregate entity encompassing one or more repository replicas. The concept of the partition isn’t particularly relevant to the operation of a Mesh-based system. It’s introduced here to aid in describing some of the topics in this document.
Rebalancing
Bitbucket Mesh implements partition migration to allow repository replicas (actually, partition replicas) to be migrated between nodes. At this time, partition migration exists to support rebalancing repositories across Mesh nodes in support of the following two use cases.
Adding a new Mesh node
When a new Mesh node is added to the system, it should start servicing requests for existing repositories. When a new Mesh node is added, a rebalancing operation takes place, migrating one or more partition replicas from existing Mesh nodes to the new Mesh node.
Removing a Mesh node
When a Mesh node is removed, it becomes unavailable to host replicas. It's important to understand the difference between an offline node and a removed Mesh node. If a Mesh node is simply shut down or is drained and disabled, this node still hosts replicas. They are unavailable temporarily.
Removing a Mesh node is a configuration change that means the Mesh node is no longer known to the control plane and no longer hosts replicas. For the system to maintain the same availability guarantees, the replicas must be hosted by that node to be migrated to another node prior to removal, and specifically, to another node that doesn’t already host replicas for the given partition.
Currently, rebalancing doesn’t take available disk space or load into account. It implements an algorithm that simply tries to uniformly distribute replicas amongst available Mesh nodes. A future version of Bitbucket is expected to account for these additional factors in making placement decisions.
Repository repair
A repository replica needs to be repaired when the replica has fallen behind either because the node missed one or more writes while it was offline, or because the node failed to replicate the write. The repair is also used to initialize a repository replica from scratch. This is done when:
A new replica is created for a partition.
A repository is migrated from NFS to Mesh. The migration does an upload to a ‘primary’ migration target and then, uses the repair to sync up the other replicas.
Migrating partitions from one node to another. This happens during rebalancing, after a new Mesh node has been added or prior to the deletion of a Mesh node.
Request routing
Mesh provides horizontal scaling because multiple nodes can handle read and write requests. A request for a given repository can be routed to potentially any Mesh node that hosts a replica of that repository.
Before we describe request routing to Mesh nodes, let's start with a description of how client requests are routed to application nodes. When a client, either a web UI client or a Git client connecting via SSH or HTTP, makes a request, they're connected to one of the nodes of the primary cluster that runs the core Bitbucket application.
These connections are initially handled by the load balancer, which then proxies those connections through to one of the cluster nodes. Web UI connections generally require session stickiness so subsequent requests for the same session are routed through to the same node, although the initial connection is typically randomly assigned to a node. So, given a large number of users, the load from web users will be roughly uniformly distributed. However, connections from Git clients don't require stickiness, and a user performing multiple clones can see each request connected to a different cluster node.
While processing a request, the cluster node handling the request may need to query the database for information, and it may need to read or write to the Git repository. This need is obvious for Git operations such as clone, fetch, or push. However, even the web UI connections often require information from the Git repository. For example, the user may be asking for a list of all branches, viewing the contents of a file, or comparing the diff between two branches. These needs are fulfilled by the Mesh subsystem, with the application running on the cluster, making gRPC remote procedure calls on the Mesh nodes.
Before making an RPC, a Mesh node must be selected to fulfill the request. This node:
Must host a replica of the repository that is the target of the request.
Must be online and not draining. Draining means the system is trying to quiesce the node so it can be taken offline, perhaps for maintenance.
The replica must be consistent. A replica may be inconsistent either because the node missed one or more writes while it was offline or because the node failed to replicate a write.
Given the set of Mesh nodes that match the above criteria, the request will be assigned to a Mesh node randomly, with the set of all requests expected to be uniformly distributed across eligible Mesh nodes.
認証
The core Bitbucket application communicates with the Mesh process via gRPC so that the Mesh application is the gRPC server and the core Bitbucket application is the gRPC client. Mesh application processes also communicate amongst each other via gRPC, primarily for tasks such as write replication and repairs.
These RPC are authenticated using JWT. Each request has a JWT auth token with claims signed by the caller and each response has a token signed by the responder. A 2048-bit RSA signing key pair exists for each Mesh node, and one exists for the control plane, that is for the core Bitbucket application. The key exchange happens when a Mesh node is first added to the system.
Repository migration
Repository migration is the process of moving repositories from the NFS-based repository store to Mesh. It's possible to upgrade to Bitbucket 8.0+ and not adopt Mesh. Repositories continue to reside on the NFS-based repository store. When ready to leverage Mesh, three or more Mesh nodes are deployed and Bitbucket is configured to use them. However, once the nodes are added to the system, they remain unused until existing repositories are migrated to Mesh or until new repositories are created there.
By default, new repositories aren’t created on Mesh. This can be changed by enabling Create new repositories on Mesh in Bitbucket Administration. Note that forking existing repositories doesn’t result in the fork being created on Mesh. If a repository resides on the NFS store, so do all forks, the existing and new ones.
Separate from the option to create new repositories on Mesh is the ability to migrate existing repositories to Mesh. The UI provides a tool that allows repositories to be migrated individually or for all repositories to be migrated at once. Repository migration doesn’t require downtime and can be carried out even while the repositories being migrated are still in use.
Not all repositories need to be migrated to Mesh simultaneously, permitting a gradual migration that may be phased and stretched out over many days, weeks, or more. This is often useful to derisk a Mesh migration in case you are unsure if your Mesh deployment is appropriately sized or ready for production load. It is possible to move repositories gradually while monitoring load and resource usage.
Sidecar
The Git source code management (SCM) logic, which was part of the core Bitbucket application prior to Bitbucket 8.0, has been extracted to the Mesh application.
Specifically, when upgrading Bitbucket to 8.0+, even repositories hosted on the NFS repository use a sliver of the Mesh code path. In Bitbucket prior to 8.0, the Git SCM logic existed in the core Bitbucket application. It was responsible for forking Git worker processes (see Figure 1). In Bitbucket 8.0, this Git SCM logic is factored out of the core Bitbucket process into its own process that we call the Sidecar (see Figure 7).
This sidecar is actually the same application as Bitbucket Mesh, but only a small subset of the functionality is used in this role. Think of it as a Mesh-lite process. It's used for repository access but doesn't leverage concepts such as replication, or partitions.
Figure 7 – Bitbucket with sidecar process

Generally, the sidecar is a concept that isn’t important to the operations of your Bitbucket instance. Where previously the Bitbucket application made Java method calls to access process-local SCM code, now it makes a gRPC call to the sidecar process to do the same. The primary areas where the administrator needs to be aware of the existence of the sidecar are monitoring and troubleshooting.
The existence of the sidecar process doesn’t constitute “using Mesh”. The sidecar process isn’t listed in Mesh nodes in the administration UI. None of the benefits of using a Mesh-based deployment are granted by the use of this sidecar process.
Deployment considerations
The following describes a number of considerations relating to the deployment of Bitbucket Mesh.
Multiple availability zone deployments
The concept of an availability zone is a common cloud term used to describe a data center where all resources share a physical location and often cooling, power, and other core subsystems. A multiple availability zone deployment leverages two or more of these availability zones to provide additional redundancy. The system is then more resilient in the face of power, cooling, and other hardware failures, as well as to events such as fires and floods.
As described previously, Bitbucket Mesh supports the concept of multiavailability zone deployment. This wasn’t possible with the NFS-based repository store since the NFS server could only exist in a single location and thus, be a single point of failure. Consequently, deploying the Bitbucket application nodes in multiple availability zones didn’t increase resilience. Furthermore, the low filesystem I/O latency Bitbucket and Git require means that even if a multiavailability zone NFS service was available, the performance of this deployment would be unacceptable.
A successful multiavailability zone deployment of Bitbucket Mesh hinges on two factors:
The ability to ensure the additional latency incurred for the RPCs is acceptable.
Replicas are distributed across Mesh nodes so that they exist in a sufficient number of availability zones to permit a single availability zone failure, while still having enough replicas to form a write quorum.
The first requirement can be met by ensuring the round trip latency between Mesh nodes is under five ms, and similarly, the round trip latency between the Bitbucket application nodes and the Mesh nodes is under five ms. This can be measured with an Internet Control Message Protocol (ICMP) ping between nodes. This figure of five ms implies that these availability zones must be relatively close geographically, generally within the same city. In cloud terminology, this also means that while multiavailability zone deployments are viable, multiregion deployments aren’t. The typical latency between regions is often tens of milliseconds and often over one hundred milliseconds.
The second requirement can be met when some conditions are fulfilled. Specifically, nodes must be distributed between availability zones so that the loss of one availability zone leaves a sufficient number of replicas for a write to succeed. The writes succeed on a quorum of replicas, where “n” is the replication factor a quorum of (n/2 + 1) replicas must be available. Note that the result of the division should be rounded down. For example, with a replication factor of three, a minimum of two replicas must be present for a write to succeed.
In a simple scenario with a replication factor of three and three Mesh nodes each in separate availability zones, it’s easy to check how an outage in one availability zone would still result in two replicas being available. See Figure 8.
Figure 8 – Redundant multiavailability zone deployment

However, a scenario with a replication factor of three and only two availability zones results in a nonredundant deployment. See Figure 9, where a failure of availability zone 1 would mean repository 1 only has one remaining replica, and thus a quorum can't be achieved and writes would be rejected. Reads would be successful via node 3.
Figure 9 – Nonredundant multiavailability zone deployment

However, having a redundant deployment isn’t sufficient in many cases. Bitbucket must be aware of availability zones and the replica placement aware of availability zone must be implemented.
Take the scenario in Figure 10. For a replication factor of three, each replica can be placed in a separate availability zone. However, as illustrated, this hasn’t happened. An outage in any availability zone will result in one of the three repositories not being able to form a quorum for writing.
Figure 10 – Multi availability zone deployment with nonredundant replica placement

In Bitbucket 8.9, the logic to perform the replica placement aware of availability zones doesn't exist. It's still in development. The work can be tracked here: BSERV-13270 - Getting issue details... STATUS
Until support for the replica placement aware of availability zones is added, achieving a redundant multiavailability zone deployment must be implemented manually. This can be achieved manually by ensuring that, even with the most pessimistic replica placement, the loss of a single availability zone would still permit a write quorum to be formed. This can often be achieved by increasing the replication factor. For example, the case in Figure 10 can be made resilient by increasing the replication factor from the default three to at least five.
The simplest approach may be to ensure that each Mesh node resides in its own availability zone, with no other Mesh nodes residing in the same availability zone.
Auto-scaling
Bitbucket Mesh can scale up by adding more nodes and scale down by removing nodes. This can be a desirable characteristic for a Bitbucket deployment since the load is often very spiky. These spikes occur due to the load from build systems that can execute hundreds of build jobs in response to a change being pushed to Bitbucket. These build jobs can result in hundreds of Git clone or fetch requests almost simultaneously.
In many cloud environments, it's desirable to implement automatic scaling or auto-scaling. This is a method of scaling up and down automatically, based on continuous monitoring of the load combined with some logic that decides when to add or remove nodes.
Auto-scaling works well for mostly stateless applications. However, Mesh is very stateful by definition. Adding a Mesh node so that it can service requests involves a process called rebalancing. This process migrates some replicas from existing Mesh nodes to new Mesh nodes. Likewise, deleting a Mesh node also involves rebalancing, where replicas are evacuated to the remaining Mesh nodes. So, the configured replication factor is maintained after the node is deleted. These processes can take tens of minutes or even hours for larger systems. Such timeframes are somewhat incompatible with the demand for auto-scaling because the bursts of traffic that auto-scaling aims to handle have a duration of about five to 20 minutes typically. So, by the time a Mesh node is available to service requests, the spike may have subsided.
Furthermore, when adding a new node, populating it with repositories replicas places a load on the existing nodes, as these are the source of the data being copied. So, right at the moment, the system is trying to better handle a load spike while replication actually taxes the system, reducing its capacity to handle user-driven requests. Consequently, it's unlikely that fine-grained auto-scaling would be beneficial, so it wasn’t a design goal for Bitbucket Mesh.