Jira アプリケーションを Pgpool-II に接続する
Pgpool-II について
Pgpool-II のアクティブ - パッシブ (プライマリ - スタンバイ) 構成のみをサポートしています。このセットアップでは、ロード バランサーを 2 つ以上のデータベースと一緒に使用できます。1 つのデータベースがアクティブで、そのデータベースが故障した場合に、別のデータベースが処理を引き継いで継続性を確保します。このセットアップには、アクティブ データベースとパッシブ データベースが含まれます。
Pgpool-II は、Postgres をベースにした高可用性 (HA) データベース ソリューションです。ここでは、Pgpool-II のような高可用性データベースへの移行をお勧めする理由を説明します。
単一障害点 (SpoF) はありません。Pgpool-II は、サービスのダウンタイムによるビジネスへの影響につながるような単一障害点を露呈する、PostgreSQL データベース特有の課題に対処します。
接続プーリング。Pgpool-II は接続プーリングを提供しているため、複数のクライアント アプリがデータベース接続プールを共有できます。これにより、クライアント リクエストごとに新しい接続を確立するオーバーヘッドが大幅に軽減され、結果的にパフォーマンスが向上し、リソース消費量を削減できます。
負荷分散。Pgpool-II には、クライアント リクエストを複数の PostgreSQL サーバー全体に分散するロード バランサーが組み込まれています。これにより、ワークロードが均等に分散され、利用可能なデータベース サーバー全体で最適なリソース使用が保証されます。
高可用性。Pgpool-II は、自動フェイルオーバーやオンライン復旧などの機能を実装することで、可用性の高い構成をサポートします。プライマリ PostgreSQL サーバーに障害が発生したことを検出し、スタンバイ サーバーを自動的にプライマリ サーバーに昇格させることができるため、ダウンタイムが最小限に抑えられ、データベースの可用性を確実に維持できます。
Pgpool-II の詳細については、公式ドキュメントをご覧ください。
はじめる前に
- ご利用の PostgreSQL のバージョンがサポート対象であることをご確認ください。詳細は「サポート対象プラットフォーム」をご参照ください。
- Jira を別のサーバーに移行する場合は、データをエクスポートしてバックアップを作成してください。古いデータベースから新しいデータベースにデータを転送できます。データベース間のデータ移行に関する詳細は、「データベースの切り替え」をご確認ください。
- セットアップ ウィザードを実行中の場合を除き、開始する前に Jira をシャットダウンします。
1. Pgpool-II 環境を実行/設定する
このドキュメントでは、VMware が提供する Bitnami の Docker イメージを使用して説明します。Pgpool の公式ドキュメントによると、この方法には いくつかのメリットがあります。
- Bitnami は上流のソースの変更を綿密に追跡し、当社の自動システムを使用してこのイメージの新バージョンを速やかに公開します。
- Bitnami イメージがあれば、最新のバグ修正と機能を早急に利用できます。
セットアップ
まず、Postgres ノードをセットアップする必要があります。これらのノードは相互にアクセスできる必要があります。同じプライベート サブネットの一部にすることも、インターネットに公開することもできます。ただし、インターネットへの公開はお勧めしません。
別のマシンにプライマリ PostgreSQL ノードを作成します。次のコマンドを実行します。
docker network create my-network --driver bridgeノードを起動すると次のようになります。
docker run --detach --rm --name pg-0 \ -p 5432:5432 \ --network my-network \ --env REPMGR_PARTNER_NODES={PG-0-IP},{PG-1-IP} \ --env REPMGR_NODE_NAME=pg-0 \ --env REPMGR_NODE_NETWORK_NAME={PG-0-IP} \ --env REPMGR_PRIMARY_HOST={PG-0-IP} \ --env REPMGR_PASSWORD=repmgrpass \ --env POSTGRESQL_POSTGRES_PASSWORD=adminpassword \ --env POSTGRESQL_USERNAME=customuser \ --env POSTGRESQL_PASSWORD=custompassword \ --env POSTGRESQL_DATABASE=customdatabase \ --env BITNAMI_DEBUG=true \ bitnami/postgresql-repmgr:latest
 「
「[NOTICE] starting monitoring of node "pg-0" (ID: 1000)」というメッセージは、プライマリ ノードが正常に作成されたことを示します。別のマシンにスタンバイ ノードを作成します。次のコマンドを実行します。
docker network create my-network --driver bridgeノードを起動すると次のようになります。
docker run --detach --rm --name pg-1 \ -p 5432:5432 \ --network my-network \ --env REPMGR_PARTNER_NODES={PG-0-IP},{PG-1-IP} \ --env REPMGR_NODE_NAME=pg-1 \ --env REPMGR_NODE_NETWORK_NAME={PG-1-IP} \ --env REPMGR_PRIMARY_HOST={PG-0-IP} \ --env REPMGR_PASSWORD=repmgrpass \ --env POSTGRESQL_POSTGRES_PASSWORD=adminpassword \ --env POSTGRESQL_USERNAME=customuser \ --env POSTGRESQL_PASSWORD=custompassword \ --env POSTGRESQL_DATABASE=customdatabase \ --env BITNAMI_DEBUG=true \ bitnami/postgresql-repmgr:latest- コード サンプル内の
{PG-0-IP},{PG-1-IP}を、pg-0 ノードと pg-1 ノードへのアクセスに使用できるコンマ区切りの IP アドレスに置き換えます。例:15.237.94.251,35.181.56.169 - 相互接続を確立するために、スタンバイ ノードは起動後すぐにプライマリ ノードへのアクセスを試みます。
- コード サンプル内の
その他のノードを参照する Pgpool バランサー ミドルウェア ノードを作成します。次のコマンドを実行します。
docker network create my-network --driver bridgeノードを起動すると次のようになります。
docker run --detach --name pgpool --network my-network \ -p 5432:5432 \ --env PGPOOL_BACKEND_NODES=0:{PG-0-HOST},1:{PG-1-HOST} \ --env PGPOOL_SR_CHECK_USER=postgres \ --env PGPOOL_SR_CHECK_PASSWORD=adminpassword \ --env PGPOOL_ENABLE_LDAP=no \ --env PGPOOL_USERNAME=customuser \ --env PGPOOL_PASSWORD=custompassword \ --env PGPOOL_POSTGRES_USERNAME=postgres \ --env PGPOOL_POSTGRES_PASSWORD=adminpassword \ --env PGPOOL_ADMIN_USERNAME=admin \ --env PGPOOL_ADMIN_PASSWORD=adminpassword \ --env PGPOOL_AUTO_FAILBACK=yes \ --env PGPOOL_BACKEND_APPLICATION_NAMES=pg-0,pg-1 \ bitnami/pgpool:latest- コード サンプル内の
{PG-0-HOST},{PG-1-HOST}を、pg-0 ノードと pg-1 ノードのホスト アドレス (ポートを含む) に置き換えます。例:15.237.94.251:5432
Bitnami コンテナーの設定に関する詳細
- コード サンプル内の
これで、
pgpoolコンテナーをデータベース クラスタへのエントリ ポイントとして使用できます。pgpoolコンテナーに接続するには、次のコマンドを使用します。psql -h {PGPOOL-HOST} -p 5432 -U postgres -d repmgrコード サンプルの
{PGPOOL-HOST}をpgpoolノード アドレスに置き換えます。たとえば、34.227.66.69とします。
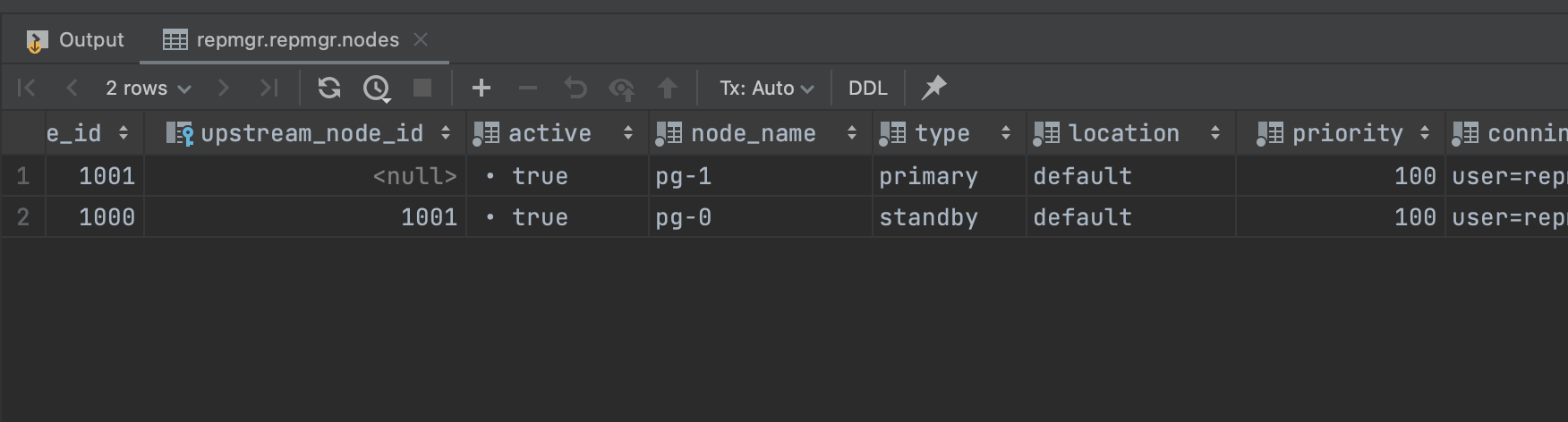
デプロイが成功したことを確認するには、次の SQL クエリを使用してrepmgr.nodesテーブルにアクセスします。SELECT * FROM repmgr.nodes;出力には、各ノードの状態に関する情報がすべて表示されているはずです。
お使いのバージョンの PostgreSQL 用にデータベースやデータベースを作成する
Pgpool インスタンスは、データベースへのエントリ ポイントとしてのみご使用ください。
お使いのバージョンの PostgreSQL のユーザーおよびデータベース作成に関する情報については、PostgreSQL の公式ドキュメントをご覧ください。
- Jira が接続するためのデータベース ユーザー (ログイン ロール) を作成します (例:
jiradbuser)。 このデータベース ユーザー名は、後続の手順で Jira とデータベースの接続を設定するために使用されるため、覚えておく必要があります。
このデータベース ユーザー名は、後続の手順で Jira とデータベースの接続を設定するために使用されるため、覚えておく必要があります。 Unicode 照合を含む課題を保管するために、Jira 用データベースを作成します (例:
jiradb)。 データベース名は、次のステップでこのデータベースへの Jira の接続を設定するために使用されるため、忘れないようにしましょう。CREATE DATABASE jiradb WITH ENCODING 'UNICODE' LC_COLLATE 'C' LC_CTYPE 'C' TEMPLATE template0;または、コマンド ラインで次を実行します。
$ createdb -E UNICODE -l C -T template0 jiradbユーザーがデータベースに接続し、データベース中でテーブルを作成、書き込みできる権限を持っていることを確認します。
GRANT ALL PRIVILEGES ON DATABASE <Database Name> TO <Role Name>- 権限が正常に付与されたことを検証するには、データベースに接続して
\zコマンドを実行します。
最適な PostgreSQL パフォーマンスを達成して維持するには、毎日実行する保守タスクをスケジュールして、データベースの統計を更新する必要があります。定期的な保守タスクのセットアップ方法は、ナレッジ ベース記事「VACUUM、ANALYZE、REINDEX で PostgreSQL パフォーマンスを最適化して改善する」をご確認ください。
2. Jira を構成してデータベースに接続する
Jira サーバーを PostgreSQL データベースに接続する方法は 2 つあります。
Jira セットアップ ウィザード — Jira をインストールした直後で、初めて Jira をセットアップする場合は、この方法を使用します。設定は Jira ホーム ディレクトリの
dbconfig.xmlファイルに保存されます。Jira 設定ツール — 既存の Jira インスタンスがある場合はこの方法を使用します。設定は Jira ホーム ディレクトリの
dbconfig.xmlファイルに保存されます。Jira 設定ツールの起動方法- 次のように Jira 設定ツールを実行します。
- Windows: コマンド プロンプトを開いて、Jira インストール ディレクトリの
binサブディレクトリにあるconfig.batを実行します。 - Linux/Unix: コンソールを開いて、Jira インストール ディレクトリの
binサブディレクトリにあるconfig.shを実行します。 このコマンドは、「X11 DISPLAY 変数がエラーになるため、Jira アプリケーション構成ツールを起動できない」で説明されているエラーによって失敗する可能性があります。その場合は、この記事で回避策をご参照ください。
- Windows: コマンド プロンプトを開いて、Jira インストール ディレクトリの
- [データベース] タブを選択して、[データベース タイプ] を [PostgreSQL] に設定します。
- 「"データベース接続" フィールド」セクションをご参考のうえ、フィールドに入力します。
- 接続をテストし、保存します。
- Jira を再起動します。
- 次のように Jira 設定ツールを実行します。
データベース接続フィールド
次の表は、Jira をデータベースに接続する際に入力する必要があるフィールドです。dbconfig.xml ファイルを手動で作成または編集する場合は、この表や、表の下にある dbconfig.xml ファイルの例もご参照ください。
| セットアップウィザード/設定ツール | dbconfig.xml | 説明 |
|---|---|---|
| ホスト名 | <url> タグ内 (例の太字テキスト):<url>jdbc:postgresql:dbserver:5432/jiradb</url> | PostgreSQL サーバーがインストールされている PC の名前または IP アドレス |
| ポート | <url> タグ内 (例の太字テキスト):<url>jdbc:postgresql:5432/jiradb</url> | PostgreSQL サーバーがリッスンしている TCP/IP ポート。このフィールドが空の場合は既定のポートが使用されます。 |
| データベース | <url> タグ内 (例の太字テキスト):<url>jdbc:postgresql:jiradb</url> | ご利用の PostgreSQL データベースの名前 (Jira データの保存先) |
| ユーザ名 | <username> タグ内:<username>jiradbuser</username> | PostgreSQL サーバーに接続するために Jira が使用するユーザー |
| パスワード | <password> タグ内:<password>jiradbuser</password> | PostgreSQL サーバーとの認証に利用するユーザーのパスワード |
| スキーマ | <schema-name> タグ内:<schema-name>public</schema-name> | PostgreSQL データベースが使用するスキーマ名。 PostgreSQL 7.2 以降の場合は、 ご利用のデータベース スキーマ名が小文字であることを確認します。Jira では、スキーマ名に大文字が含まれる PostgreSQL データベースは使用できません。 カスタム スキーマは問題を引き起こす可能性があるため、公開スキーマの使用をお勧めします。詳細については、 JRASERVER-64886 - 課題情報を取得中... ステータス をご参照ください。 |
dbconfig.xml ファイルのサンプル
dbconfig.xml ファイルに含まれる、pool で始まる <jdbc-datasource/> の子要素の詳細は「データベース接続のチューニング」をご参照ください。
<?xml version="1.0" encoding="UTF-8"?>
<jira-database-config>
<name>defaultDS</name>
<delegator-name>default</delegator-name>
<database-type>postgres72</database-type>
<schema-name>public</schema-name>
<jdbc-datasource>
<url>jdbc:postgresql://dbserver:5432/jiradb</url>
<driver-class>org.postgresql.Driver</driver-class>
<username>jiradbuser</username>
<password>password</password>
<pool-min-size>20</pool-min-size>
<pool-max-size>20</pool-max-size>
<pool-max-wait>30000</pool-max-wait>
<pool-max-idle>20</pool-max-idle>
<pool-remove-abandoned>true</pool-remove-abandoned>
<pool-remove-abandoned-timeout>300</pool-remove-abandoned-timeout>
<validation-query>select version();</validation-query>
<min-evictable-idle-time-millis>60000</min-evictable-idle-time-millis>
<time-between-eviction-runs-millis>300000</time-between-eviction-runs-millis>
<pool-test-on-borrow>false</pool-test-on-borrow>
<pool-test-while-idle>true</pool-test-while-idle>
</jdbc-datasource>
</jira-database-config>3. Jira の起動
これで、PostgreSQL データベースに接続するための Jira の設定が完了しました。次のステップでは、Jira を起動します。