Jira 7.3 の拡張
1 つの Jira インスタンスの規模を決定する
組織内の Jira のパフォーマンスに影響を与える可能性のある要因は複数あります。これらの要因は次のカテゴリーに分類されます (特定の順序はありません):
- データ サイズ
- 課題、コメント、および添付ファイルの数。
- プロジェクトの数。
- Jira プロジェクト属性の数 (カスタム フィールド、課題タイプおよびスキーム)。
- Jira やグループに登録されているユーザー数。
- ボード数、およびボード上の課題数 (Jira Software を使用している場合)。
- 使用パターン
- Jira を同時に使用しているユーザー数。
- 同時操作の数。
- 電子メール通知の量。
- 構成
- プラグインの数 (一部は独自のメモリ要件を持っている場合がある)。
- ワークフロー ステップ実行の数 (移行や事後操作など)。
- ジョブの数とスケジュールされたサービス。
- デプロイメント環境
- 使用されている Jira のバージョン。
- Jira が実行されているサーバー。
- 使用されているデータベースとデータベースへの接続性。
- オペレーティング システム (ローカル ファイル ストレージ、メモリ割り当ておよびガベージ コレクションを含む)。
このページは、データベースに保存されているデータのサイズや特徴によって、Jira の速度がどのように影響を受けるかを示しています。
Jira 7.3 のパフォーマンス
Jira 7.3 はパフォーマンスのみに焦点を当てたバージョンではありませんでしたが、 各リリースでそれ以上のパフォーマンスを提供することを目指しています。このシナリオでは、Jira 7.3.0 を Jira 7.2.5 と比較します。具体的には、両方の Jira バージョンで同じ広範囲のテスト シナリオを実行しました。シナリオ間の唯一の違いは Jira バージョンです。
次のグラフは、テスト中に実行された個別操作の1% 刈り込み平均応答時間を表しています。
Jira 操作の応答時間
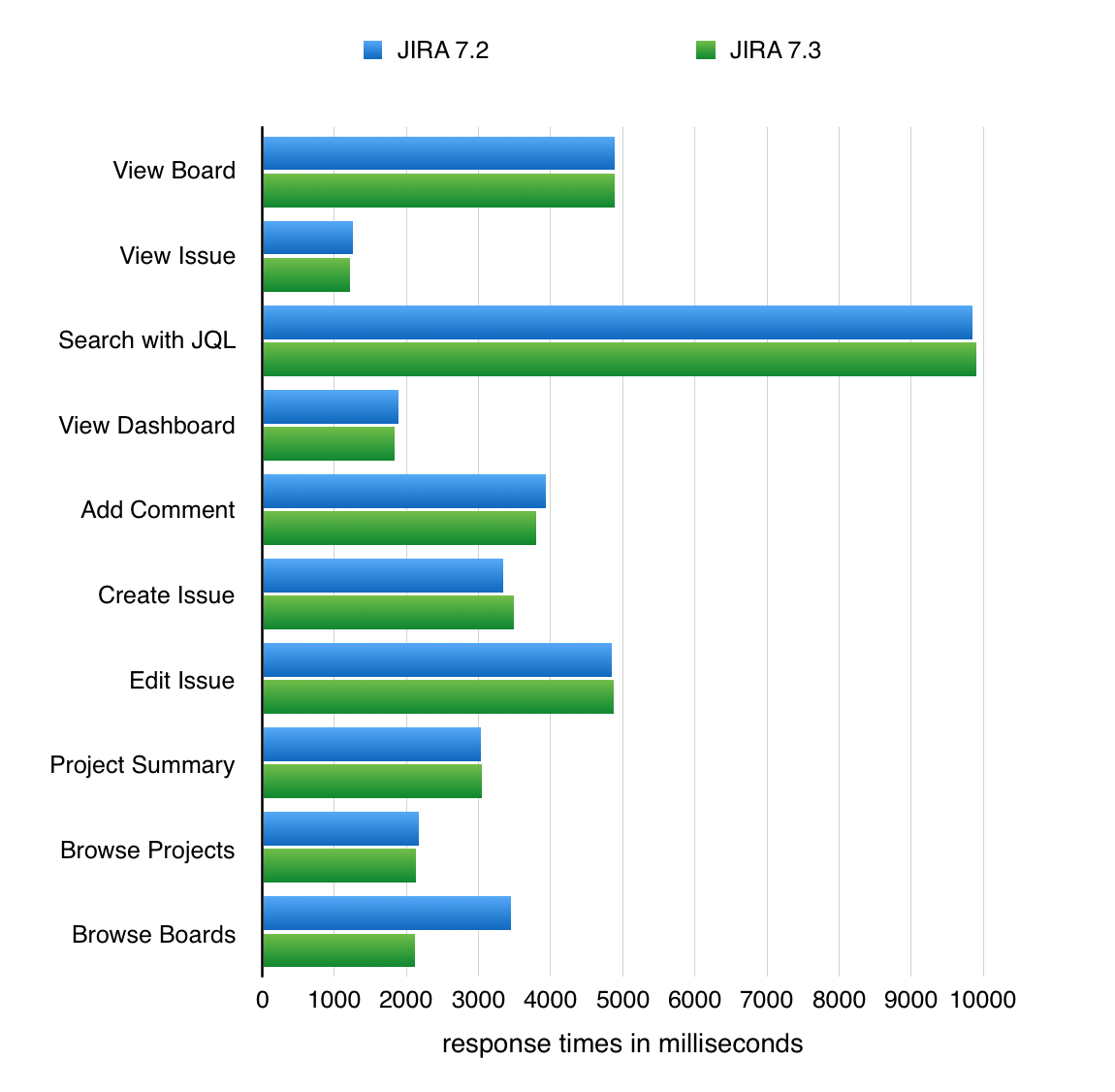
パフォーマンス テストの結論:
- 平均して、Jira 7.3.0 は Jira 7.2.5 よりも 4% 早く操作を実行する。これは、以下のテストから得られた、操作を完了するための平均時間に基づいている。
- ほとんどの個別操作のパフォーマンスは非常に似ています。
- Agile ボードの参照は非常に高速です。
Jira パフォーマンス テストの方法
以下のセクションでは、当社のパフォーマンス テストで使用するテスト環境 (ハードウェア仕様を含む) とテスト方法を詳しく説明します。
テスト方法
テストを開始する前に、一般的な大きい Jira インスタンスを表すデータセットのサイズと形状を決定する必要があります。
これを実現するため、顧客環境の全体像や、大組織で Jira を拡張する際に顧客が直面する問題を把握するため、Analytics データを使用しました。
Analytics データには Agile ボードや添付ファイルに関する情報が含まれていないため、Jira 6.4 拡張レポートからそれらを課題と比較して拡張することで推測しました。
次の表では、各データ ディメンションの 999 番目のパーセンタイルの値を切り捨てています。これらの値を使用して、Jira Data Generator でランダム テスト データが入ったサンプル データセットを生成します。
ベースライン テスト Jira データ セット
| Jira データ ディメンション | 値 |
|---|---|
| 課題 | 1,000, 000 |
| プロジェクト | 1500 |
| カスタム フィールド | 1400 |
| ワークフロー | 450 |
| 添付ファイル | 660,000 |
| コメント | 2,900, 000 |
| アジャイルボード | 1,450 |
| ユーザー | 100,000 |
| グループ | 22,500 |
| セキュリティ レベル | 170 |
| 権限 | 200 |
次に、最も一般的なユーザー操作のサンプルを表す混合操作を選択します。このコンテキストにおける「操作」とは、ブラウザ ウィンドウで課題を開くなどの、完全なユーザー操作です。次の表は、ペルソナのテスト用にスクリプトに含めた操作の詳細と、1 回のテスト中に各操作が何回繰り返されるかを示しています。
| 操作名 | 説明 | 1 回のテスト実行中に操作が実行された回数 |
|---|---|---|
| ダッシュボードの表示 | ダッシュボード ページを開く。 | 10 |
| 課題の作成 | 課題の作成ダイアログを送信する。 | 5 |
| 課題の表示 | 別のブラウザー ウィンドウで個別の課題を開く。 | 55 |
| 課題の編集 | 既存のフィールドのサマリー、説明およびその他のフィールドを編集する。 | 5 |
| コメントを追加 | 課題へのコメント追加。 | 2 |
| JQL の検索 | 課題ナビゲーター インターフェイスで JQL を使用して検索クエリを実行する。
| 10 |
| ボードの表示 | Agile Board を開く | 10 |
| プロジェクトの参照 | プロジェクトのリストを開く (プロジェクト > すべてのプロジェクトの検索メニューから利用できます) | 5 |
| ボードの参照 | Agile Boards のリストを開く (Agile > ボードの管理メニューから利用できます) | 2 |
テスト環境
パフォーマンス テストはすべて、同じラボ (アトラシアンが管理する隔離されたラボ) で実施しました。テストのたびに環境全体をリセットして再構築し、各テストの最初にはインスタンス キャッシュをウォームアップするアイドル サイクルを実行しました。テストを実行するにあたり、スクリプトを組んだブラウザーを 10 個使用して、操作の実行にかかる時間を計測しました。各ブラウザーのスクリプトは、定義済みの操作リストからランダムに操作を実行し、すぐに次の操作に移る (つまり思考時間がゼロになる) ように組まれています。これにより、実際のユーザーが実行できるタスク数を大幅に上回るタスクを各ブラウザーで実行できました。ただし、ブラウザーの数が実環境の同時ユーザーの数と等しいと解釈してはならないことにご注意ください。各テストは 45 分間実行され、その後、統計情報が収集されました。
Jira 7.3 の拡張性
Jira は柔軟なため、顧客の構成にはとてつもない多様性があります。Analytics データは、ほとんどの顧客データセットが、独自の特性を示していることを示します。異なる Jira インスタンスは、各データ ディメンションの異なる比率で増加します。いくつかのディメンションは他のディメンションより大幅に大きくなることが多くあります。たとえば、課題数が急速に増加する一方、プロジェクト数は一定数を維持することがあります。また、別の事例では、カスタム フィールドが膨大なのに、課題数が少なくなる場合があります。
多くの組織には独自のプロセスやニーズがあります。これらのさまざまな使用事例をサポートできる Jira の能力が、データセットの多様性の理由となっています。ただし、各データ ディメンションは Jira の速度に影響を与える可能性があります。多くの場合、これらの影響は一定または直線的ではありません。
それぞれの Jira インスタンス ユーザーに最適な体験を提供し、パフォーマンスの劣化を防ぐため、具体的な Jira データ属性がアプリケーションの速度にどのような影響を与えるかを理解することが重要です。このセクションでは、様アマナ構成値の相対的な影響を調査した Jira 7.3 拡張性テストの結果を示します。
テスト方法
テスト用の参照として、上記で指定したベースライン データ セットとともに Jira 7.3 インスタンスを使用し、フル パフォーマンス テスト サイクルを実施しました。次にベースライン データ セットで各属性を 2 倍にし、2 倍になった値に対して独立したパフォーマンス テストを実施し (例:課題数を 2 倍、またはカスタム フィールド数を 2 倍にしてテストを実行しました)、ベースライン データ セットのその他すべての値は変更せずそのままにしました。次に、2 倍にしたデータ セット テスト サイクルの応答時間を参照結果と比較しました。コノアプローチを使用して、個別 Jira 構成アイテムのサイズの増加が (既に大きくなっている) Jira インスタンスの速度にどのように影響するかを隔離し、観察することができました。
以下のグラフでは、個別データ属性のサイズの増加に対し、Jira 操作の応答時間がどのように変化するかを示しています。
分かりやすくするため、各グラフは応答時間の差が、テスト手順のランダム性によって発生した自然発生ノイズのバラツキより大きい場合のみを示しています。



課題
大組織の熟練した Jira 管理者の間では一般的に、Jira パフォーマンスに影響する最も重要な要因は課題数であると信じられています。つまり、個別 Jira インスタンスが 200,000 課題に到達すると、反応しなくなり始めます。古い Jira バージョンでは一般的にこれが当てはまりますが、JIRA 5.1 以降、課題数が Jira の全体的な応答性に与える影響は徐々に小さくなっています。今でも課題数は、課題のインデックス作成に必要な操作の速度に影響を与えますが、応答性の低下はあまり深刻ではなく、Jira 7.3 は 1,000,000 以上の課題を処理することができます。
次のグラフは、課題数が 1,000,000 および 2,000,000 の Jira 7.3 インスタンスにおける Jira 操作の応答時間を表しています。

結論
課題の数は JQL 経由での検索およびボードの表示、つまり課題インデックスからの読み取り操作に最も影響を与えている。
カスタム フィールド
カスタム フィールドは該当コンテキストの設定、フィールド構成の設定や画面スキームの設定、およびこれら 3 つのさまざまな組み合わせを含むさまざまな方法で構成できます。このテストでは、カスタム フィールドの味覚の数がパフォーマンスにどの程度影響するかを確認するため、すべてのカスタム フィールドをグローバルに設定しました。
次のグラフは、カスタム フィールド数が 1,400 および 2,800 の Jira 7.3 インスタンスにおける Jira 操作の応答時間を表しています。

結論
- カスタム フィールドの数はカスタム課題の詳細 (課題の表示、検索、作成および編集、コメントの追加) をリクエストまたは処理する操作に最も影響を与えた。
- ダッシュボードの表示やプロジェクトの参照に対し、わずかではあるが、やや目立つ影響がある。
プロジェクト
次のグラフは、プロジェクト数が 1,500 および 3,000 の Jira 7.3 インスタンスにおける Jira 操作の応答時間を表しています。
 結論
結論
- プロジェクト数は Jira パフォーマンスの多く (最も重要なものはコメントの追加やプロジェクトの参照) の側面に目に見える影響を与える。
- 課題の表示、作成、および編集には大きな影響は見られなかった。
ユーザーとグループ
ユーザーの数は、課題の数に次いで、Jira インスタンス サイズで顧客が最もよく引用している例の 1 つです。Jira のパフォーマンスにおけるユーザー数の影響を評価する際、同時に Jira をアクティブに使用しているユーザー数 (同時ユーザー) から Jira に登録されているユーザー アカウントの数を切り離すことが重要です。このテストでは、同時ユーザーの数を増やさずに、Jira に登録されているユーザーやグループの絶対数の影響を判断しようとしました。同時 Jira ユーザーの数が多い場合は、Jira Data Center ソリューションを検討することをお勧めします。このソリューションではロードバランサを使用して Jira アプリケーションをマルチノード クラスタにクラスタ化し、クラスタ全体で負荷を分散します。
次のグラフは、100,000 ユーザーと 22,500 グループの場合の Jira 7.3 インスタンスにおける Jira 操作の応答時間を、200,000 ユーザーと 45,000 グループの場合を比較したものです。

結論
ユーザーやグループの数はコメントの追加は課題の作成/編集など、ユーザー ピッカーやコメントを視覚的に使用する操作のパフォーマンスにマイナスの影響を与える。
ワークフロー
次のグラフは、ワークフロー数が 450 および 900 の Jira 7.3 インスタンスにおける JIRA 操作の応答時間を表しています。

結論
ワークフローの数はコメントの追加に目立つ影響を与えている。課題の作成や表示に与える影響は小さい。
パーミッションとセキュリティ レベル
次のグラフは、セキュリティ レベルが 170 でパーミッションが 200 の Jira 7.3 インスタンスを、セキュリティ レベルが 340 でパーミッションが 400 の場合を比較しています。

結論
- パーミッションの数は、1 つのボードの表示時間に大きな影響を与えた。
- それ以外に、Jira パフォーマンスの大幅な変更は見られなかった。
重要なポイント
- Jira 7.3.0 はパフォーマンスのみを重視したリリースではありませんでした。パフォーマンスの改善はわずかでした。結果を注意深く観察することで将来の不具合を防ぐため、パフォーマンス テストのパイプラインを拡大しました。
- カスタム フィールドはデータ ディメンションに最も大きな影響を与えます。つまり、Jira 構成を効率的に保つことは今でも優れた方法です。カスタム フィールドやワークフローの数を制限したり、可能な場合はスキームを再使用することは、Jira インスタンスの十分なパフォーマンス レベルを維持するだけでなく、管理の複雑性を軽減するのにも役立ちます。
- コメント、Agile ボードや添付ファイルの数は弊社のテストにおいて Jira パフォーマンスに大きく影響しませんでした。ここでは詳細には説明しません。
その他のリソース
課題をアーカイブする
課題の違いは Jira のパフォーマンスに大きく影響しないことがわかりましたが、まちがいなく最も大きい値のディメンションです。あなたは Jira のビューに膨大な数の課題が溢れているという結論に達し、インスタンスから古い課題をアーカイブしたいと思われるかもしれません。
Jira Data Center
Jira Data Center は、大量の同時実行ユーザーがいる場合に理想的なソリューションです。Jira Data Center では、すべてのノードがアクティブになっているマルチノード クラスタで Jira アプリケーションをクラスタ化することができます。つまり、ロードバランサを前面に使用することで、複数のノードで負荷を分散させることができるため、1 つのサーバーが同じ負荷を処理する場合と比較してスループットが高くなります。また、Jira Data Center 7.3 は高可用性を提供し、Jira ディザスタ リカバリ用にアトラシアンがサポートしている唯一のオプションです。
Jira Data Center の詳細については、メインページを参照してください。
ユーザー管理
Jira ユーザー ベースが増加すると、以下を確認する必要が出る場合があります。
- 認証、ユーザーおよびグループ管理のため、Jira を LDAP ディレクトリに接続する。
- ユーザー管理のために Crowd または別の Jira Server に接続する 。
- 他のアプリケーションに対し、ユーザー管理のために Jira への接続を許可する。
Jira ナレッジベース
パフォーマンス関連のトピックの詳細なガイドラインについては、Jira ナレッジベースの「Jira サーバーのパフォーマンスの問題のトラブルシューティング」の記事を参照してください。
Jira エンタープライズ サービス
経験豊富なアトラシアンから直接組織内の Jira の拡大のサポートが必要な場合は、プレミア サポートと技術アカウント管理サービスをご利用ください。
ソリューションパートナー
お住まいの地域のアトラシアン エキスパートも、お客様の環境での Jira の拡大をサポートできます。