
Data Center upgrade guide
No organization is the same, and neither is your migration journey. Follow our step-by-step upgrade guide to ensure a smooth transition from Atlassian Server to Data Center.

Assess
Each organization has unique needs and requirements, so it’s important to understand your choices to plan a successful upgrade.
Understand your architecture and infrastructure requirements
Decided on Data Center? You’ll need to to get to know the supported Data Center architecture and deployment configurations.
Data Center can be deployed in two different ways: non-clustered or clustered. Both allow you to leverage enterprise features and capabilities, but each option requires different considerations. Here’s a table that describes the differences between non-clustered and clustered architectures:
Non-clustered recommended
Infrastructure requirements
A non-clustered architecture enables you to upgrade to Data Center on your existing infrastructure, so you don’t need to make any infrastructure changes.

Recommended use cases
We recommend that all customers upgrade to Data Center using the non-clustered upgrade path. Customers can implement a clustered architecture once live on Data Center if needed.
Benefits
Unlock the enterprise features that don’t rely on clustering:
Non-clustered upgrades are typically where many customers begin their Data Center journey. We recommend taking advantage of this 2-minute upgrade to ensure a smooth transition.
Clustered
We recommend that all customers upgrade to Data Center first using the non-clustered upgrade path. Following a successful Data Center upgrade, customers can then implement a clustered architecture if needed.
Infrastructure requirements
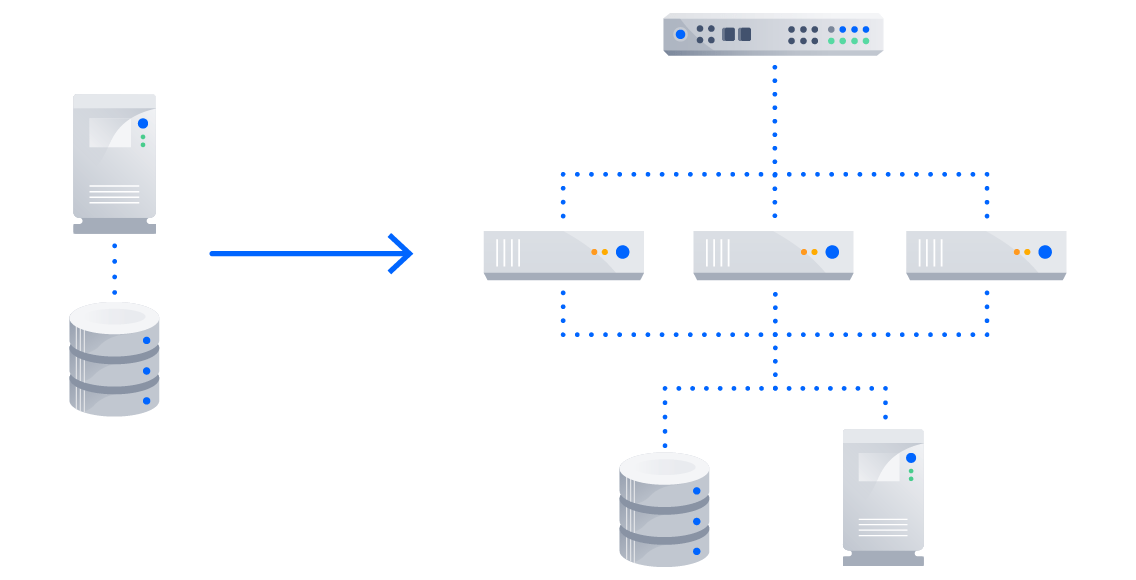
You will need the following components to upgrade to Data Center in a cluster:
- Load balancer
- Application nodes
- File system accessible by all application nodes
- ElasticSearch node (Bitbucket)
Recommended use cases
- You require high availability
- You want to upgrade without downtime
- You expect to grow to XL scale in the short term
Benefits
Unlock the enterprise features that clustering can deliver:
- Enterprise features and capabilities
- High availability and failover – if one node in your application cluster goes down, the others take on the load, ensuring your users have uninterrupted access to the product.
- Instant scalability – Add new nodes to your cluster without downtime or additional licensing fees. Indexes and apps are automatically synced.
- Disaster recovery – Deploy an offsite Disaster Recovery system for business continuity, even in the event of a complete system outage. Shared product indexes get you back up and running quickly.
Plan and prep
Now that you’ve chosen your Data Center path, you’re ready to start creating a detailed upgrade plan.
Build a timeline Required
Here are the basic timelines that you can use to gauge how long your upgrade should take.
| | Non-clustered | Clustered |
|---|---|---|
| Planning | Non-clustered 0–2 weeks | Clustered 1 month + |
| Dry run | Non-clustered 0–1 week | Clustered 3–6 months |
| Go live | Non-clustered 0–1 week | Clustered ~6–9 months |
The timelines included are based on a number of our customers who have successfully upgraded to Data Center, but it’s important to note that the actual timeline will vary based on factors unique to your environment including, but not limited to, environment size, complexity, and preparedness.
Define your Data Center environment Required
Application layer
Instances and locations
- Do you want to federate or consolidate your instances?
- What does your future growth look like?
- Do you need to have any data isolation?
- How many environments does your team have, such as staging or production environments?
Instances profiles
- How many people are going to be accessing your instance?
- Where are your teams going to be located?
- How much data is currently in your instance and how much data do you plan to add to your instance?
Apps, integrations, and customizations
Do you need all of them, or is this an opportunity to simplify?
Infrastructure layer
Instance sizing
- What are your future growth projections?
- Are there times when you have lower levels of user traffic?
For more information, here’s our node sizing overview.
Account structure
- Which accounts should your environment be deployed on?
- Do you want different accounts associated with each of your environments?
- Do you want your Data Center products to use the same account as your other CI/CD or collaboration tools?
Governance model
- What does your governance model look like?
- What are your minimal system standards?
- Are you using centralized logging?
- What are your user management needs?
Consider using AWS landing zone and AWS System Manager as part of your governance model.
VPC
-
Do you want to use a new virtual private cloud (VPC)?
Whether you want to deploy in a new VPC or use an existing one, you can leverage the Atlassian Standard Infrastructure (ASI) template.
- Are there any network principles that you want to change, such as limiting public internet access and internal IP addressing for office and VPN network routing?
- Should you use TLS certificates?
Geography
-
If using an existing VPC, have you come up with a plan for office and VPN network access?
We recommend that you allow access from all offices and VPNs as your product usage will most likely grow over time.
Direct Connect
- Do you want to use Direct Connect to help with performance and security?
- How much data do you need to move from your server instance to Data Center?
AWS Snow Family may be a resource that you may want to consider if you’re moving large amounts of data.
Business continuity and disaster recovery
Backup
What does your backup strategy look like?
We recommend that you use a combination of both your existing backup strategy and backup capabilities built into AWS. For more information, see:
AWS provides infrastructure services that are less prone to singular outages.
Regional failover
Do you need to implement cold, warm, or hot sites in different regions?
Typically, your disaster recovery needs are met by having your services run over multiple availability zones, but you may want to mitigate regional outages too. As you’re deciding if you want to implement these sites in different regions consider the following:
- Cost of infrastructure and data transfer
- Speed of recovery vs AWS
- Time spent maintaining and testing the recovery site
- Cost of running the site

Upgrade to Data Center (non-clustered) recommended
We recommend that all customers upgrade to Data Center using non-clustered architecture. Non-clustered upgrades are a faster and more simplified upgrade option, providing quicker access to Data Center’s security, support and enterprise features.

Upgrade to Data Center (clustered) not recommended
We do not recommend initial upgrades to Data Center on clustered architecture due to the complexity of upgrading. We recommend that all customers first upgrade to Data Center using the non-clustered upgrade path. Following that, customers who require a clustered architecture can begin their implementation.
Once you’ve upgraded to Data Center on non-clustered architecture you can then implement a clustered architecture if you require high availability.
Get the infrastructure you need for your cluster
To deploy Data Center in a cluster, you’ll want the following components:
- Database
- Load balancer
- Application nodes
- Shared file system
- ElasticSearch node (Bitbucket)
Load balancer
The load balancer is the first thing that your users’ requests hit if you’ve deployed in a cluster. Requests come into the load balancer and the load balancer then distributes each request to the application nodes. You can use either a hardware or software-based load balancer. For both software and hardware solutions, the load balancer should be linked to the application cluster using a high-speed LAN connection to ensure high bandwidth and low latency. All software load balancers should run on dedicated machines.
Data Center products assume that each user’s request will go to the same node during a session. If requests go to different nodes, users may be unexpectedly logged out, and they could even lose information stored in their session. Therefore, it is required to bind a session to the same node by enabling cookie-based “sticky sessions” (or session affinity) on the load balancer. When using cookie-based sticky sessions, you can use the cookie issued by the product, or you can use a cookie generated by the load balancer.
Add an extra layer of protection and prevent the load balancer from becoming a single point of failure by adding redundancy to your load balancing solution. You can do this by setting up two load balancers in an active-passive configuration, using a virtual IP address across both load balancers. If the active load balancer fails, it will failover to the passive load balancer.
For more information, see our load balancer configuration options.
Application nodes
Application nodes are where the actual product lives. Each node in your Data Center cluster must run on the same version of the product and be located together to keep latency to a minimum. However, you can enable a content delivery network (CDN) to support the performance of your geo-distributed teams. These nodes should be configured in a cluster, acting as one, to serve the product to your users. The number of nodes in your cluster depends on your needs and how you configure your product. Typically, we find that between 2-4 nodes are sufficient for most clusters, but use our node sizing guides to help you make the right decision.
Bitbucket requires an additional application node specifically dedicated to ElasticSearch, which enables code search.
Shared file system
The shared file system is where data that should be accessible from any application node is stored, such as attached files, and git repositories.
In a Data Center environment, you need to set up your shared file system as its own node. You can use any NFS based NAS or SAN program for your shared file system, but we recommend NFS3 to maintain your performance. Just be sure to stay away from distributed protocols like DFS, as these are not supported.
Create a staging environment
To successfully upgrade to multi-node, we recommend creating a staging environment to try out Data Center before going live in production.
Your staging environment should closely replicate your production environment, including any reverse proxies, SSL configuration, or load balancer. You may decide to use a different physical server or a virtualized solution. The main thing is to make sure it is an appropriate replica of your production environment.
For detailed instructions, see:
Talk to an expert
Have a question about your migration options or path? Get expert guidance from our team of migration specialists.